CAP理论用来指导分布式系统设计,以保证系统的可用性、数据一致性等。
一致性、可用性和分区容错性是分布式系统的三个特征。
CAP理论是指在分布式系统中,C、A、P这三个特征不能同时满足,只能满足其中两个。
在实际场景中,网络环境不可能百分百不出故障,比如网络拥塞、网卡故障等,都会导致网络故障或者不通,从而导致节点之间无法通信,或者集群中节点被划分成多个分区,分区中的节点之间可以通信,但是分区之间是不能通信的。
这种由网络故障导致的集群分区情况,被称为网络分区。
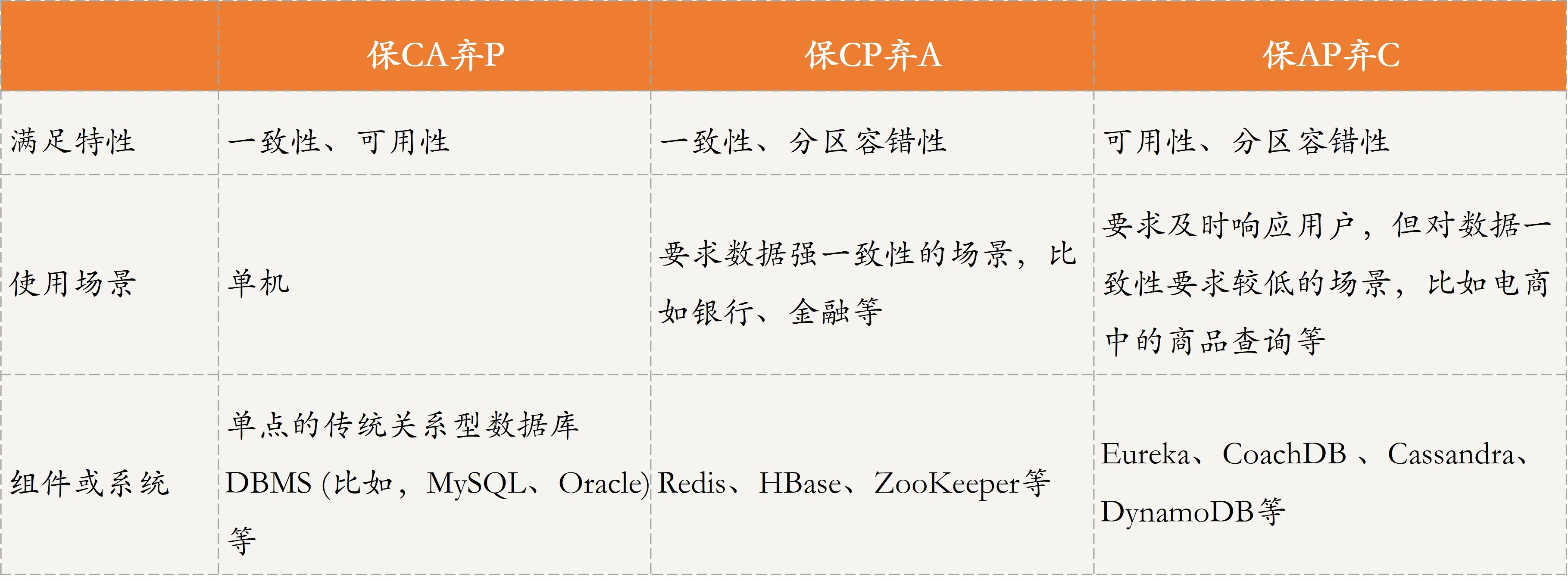
在分布式系统中,现有的网络基础设施无法做到始终保持稳定,网络分区难以避免,牺牲分区容错性P,就相当于放弃部分分布式系统,因此在分布式系统中,是不需要考虑CA模式的。
但是在单点系统或者单机系统中,CA需求是可以满足的,例如大部分关系型数据库,如果部署在单台机器上,因为不存在网络通信,所以是可以保证CA的。
如果一个分布式场景需要很强的数据一致性,或者该场景可以容忍系统长时间没有响应,那么放弃可用性A,保留一致性C是比较合适的。
一个保证CP的分布式系统,一旦发生网络分区会导致数据无法同步的情况,这时需要牺牲系统的可用性,降低用户体验,直到节点数据达到一致后再提供服务。
一般涉及到金融相关的场景,在任何时候都需要保证强一致,因此要保证CP。
保证CP的系统包括Redis、HBase、ZooKeeper等。
例如,ZooKeeper集群包括Leader节点和Follower节点,Leader节点专门负责处理用户的写请求:
当ZooKeeper集群中出现网络分区,如果其中一个分区的节点数大于集群节点数的一半,那么这个分区可以再选出一个Leader,仍然对外提供服务,但是在选出Leader之前,系统是不可用的;如果形成的分区中,没有一个分区的节点数大于集群节点总数的一半,那么系统不能正常对外提供服务,必须等待网络恢复后,才能正常提供服务。
如果一个分布式系统需要很高的可用性,或者说在网络状况不好的情况下,允许数据暂时不一致,那么可以牺牲一定的一致性。
这时网络分区出现后,各节点之间的数据无法马上同步,为了保证高可用,分布式系统需要即刻响应用户请求,但此时某些节点还没有拿到最新数据,只能将本地旧的数据返回给用户,从而产生数据不一致的情况。
适合AP的场景有很多,例如查询网站、电商中的商品查询等,这样的系统用户体验更加重要,需要保证系统的可用性。
保证AP的系统包括CoachDB、Eureka、Cassandra、DynamoDB等。
下面是关于CA、CP和AP的详细比较。
ACID是数据库事务中常见的理论,它和CAP是两回事:
出处:http://wing011203.cnblogs.com/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
 登录查看全部
登录查看全部
参与评论
手机查看
返回顶部