前预训练时代的自监督学习自回归、自编码预训练的前世

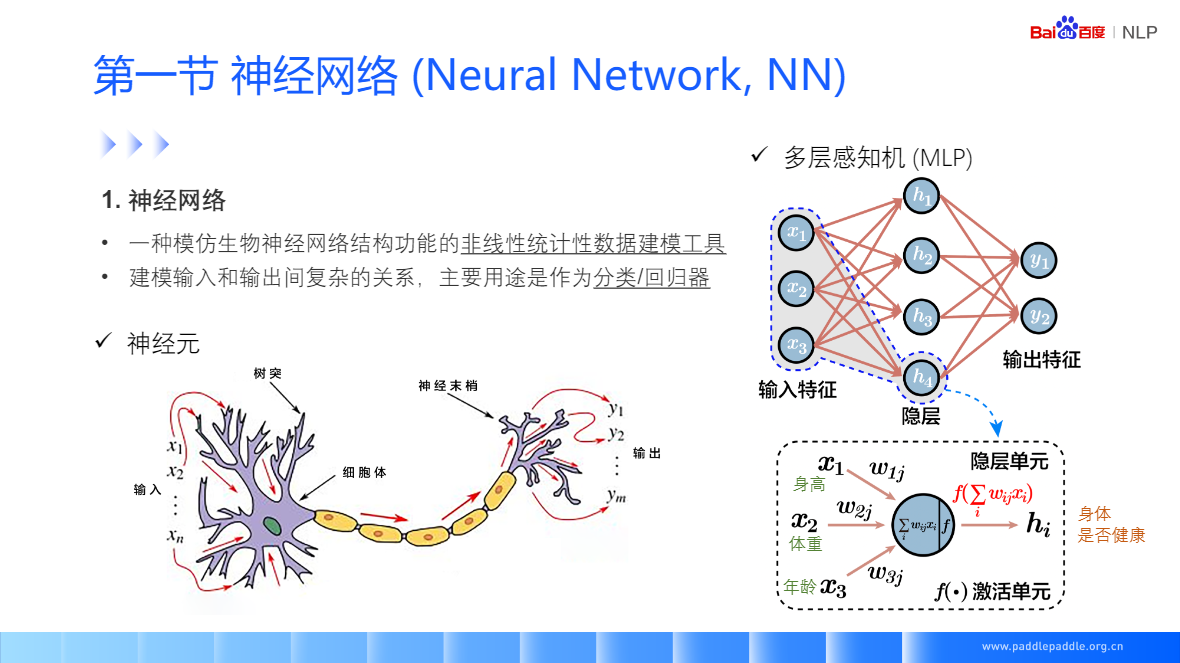
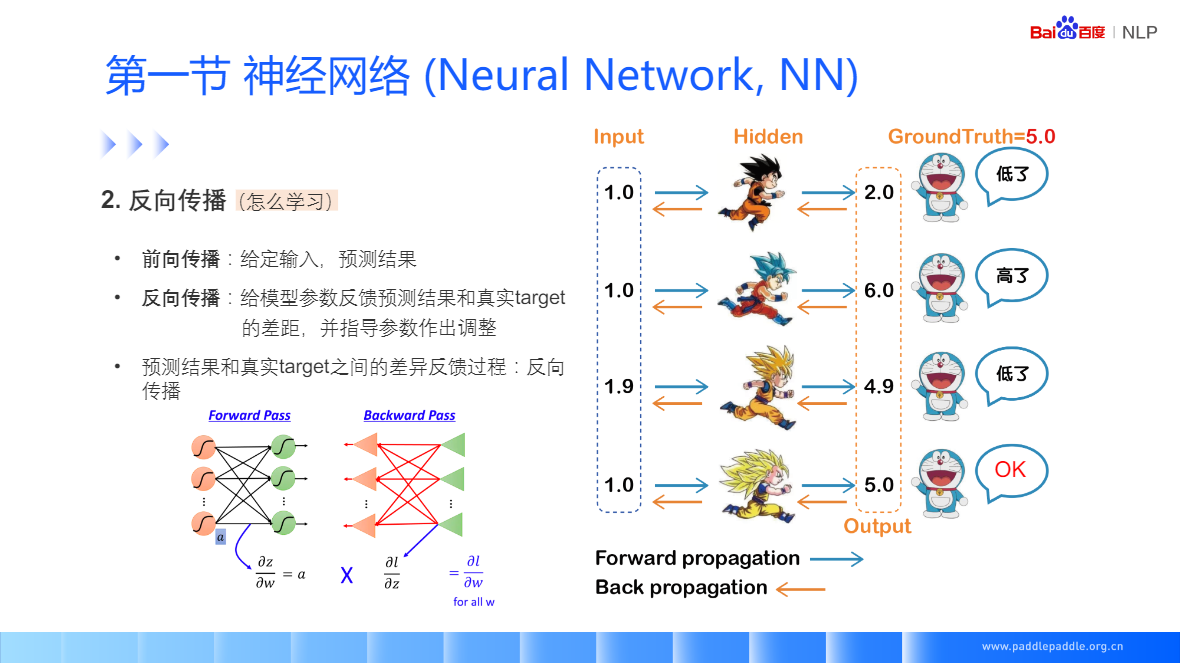
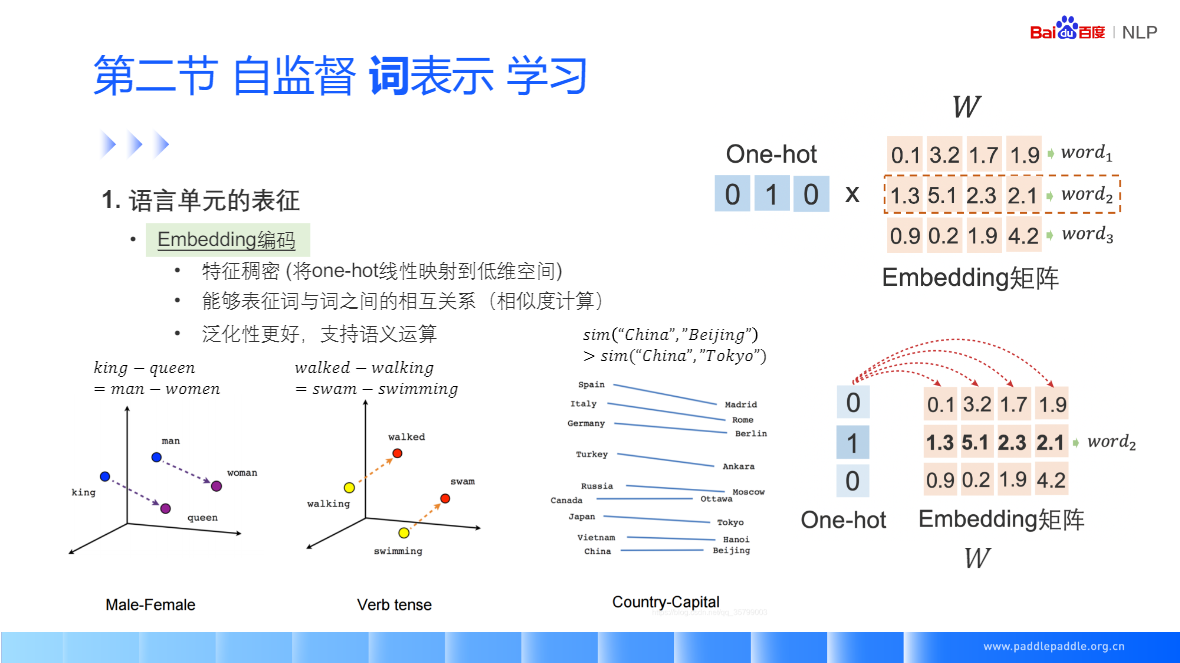
神经网络(Neural Network, NN)
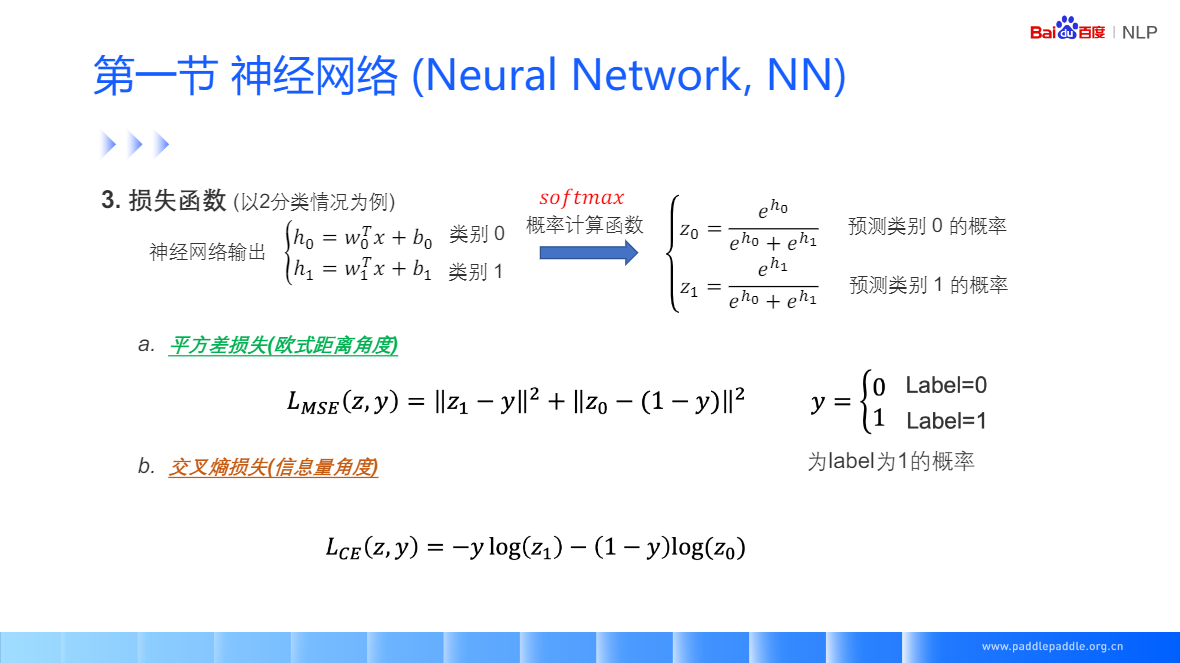
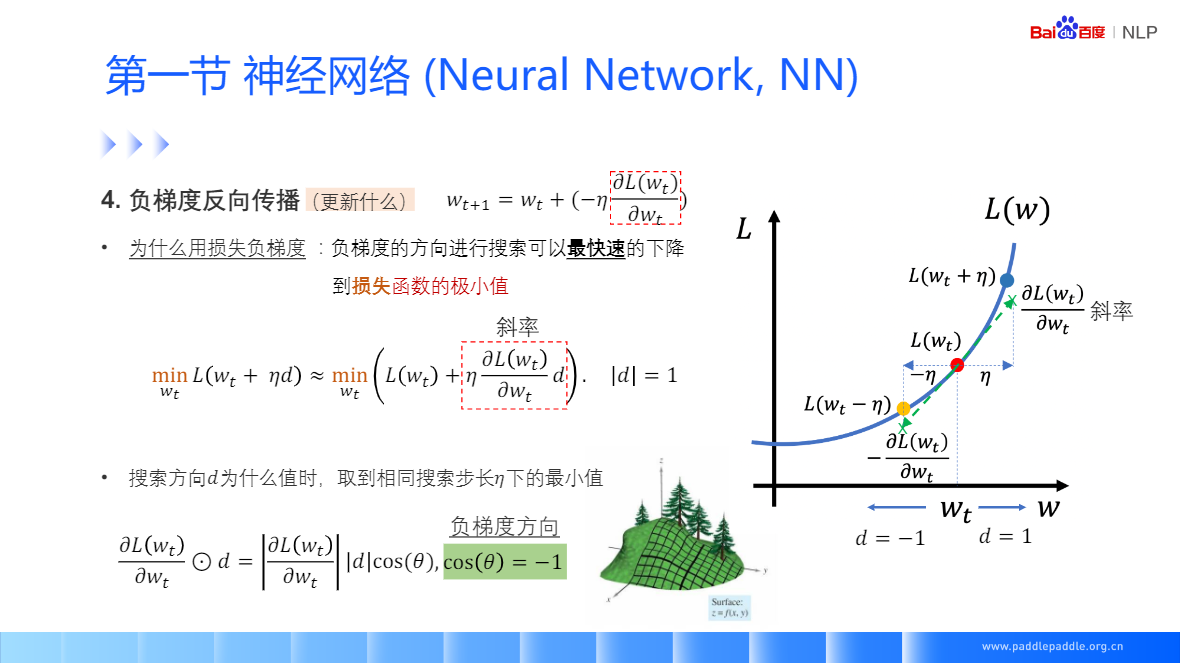
损失函数,度量神经网络的预测结果和真实结果相差多少


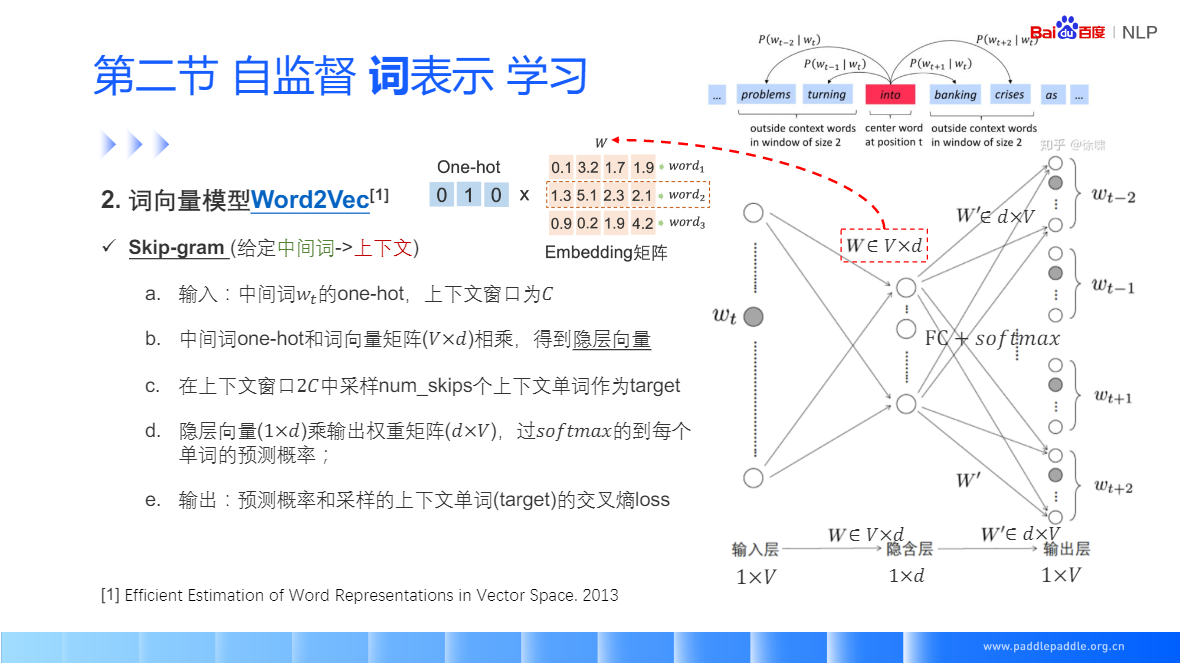
Skip-gram: 给定一个中间值,预测上下文窗口中的一个词

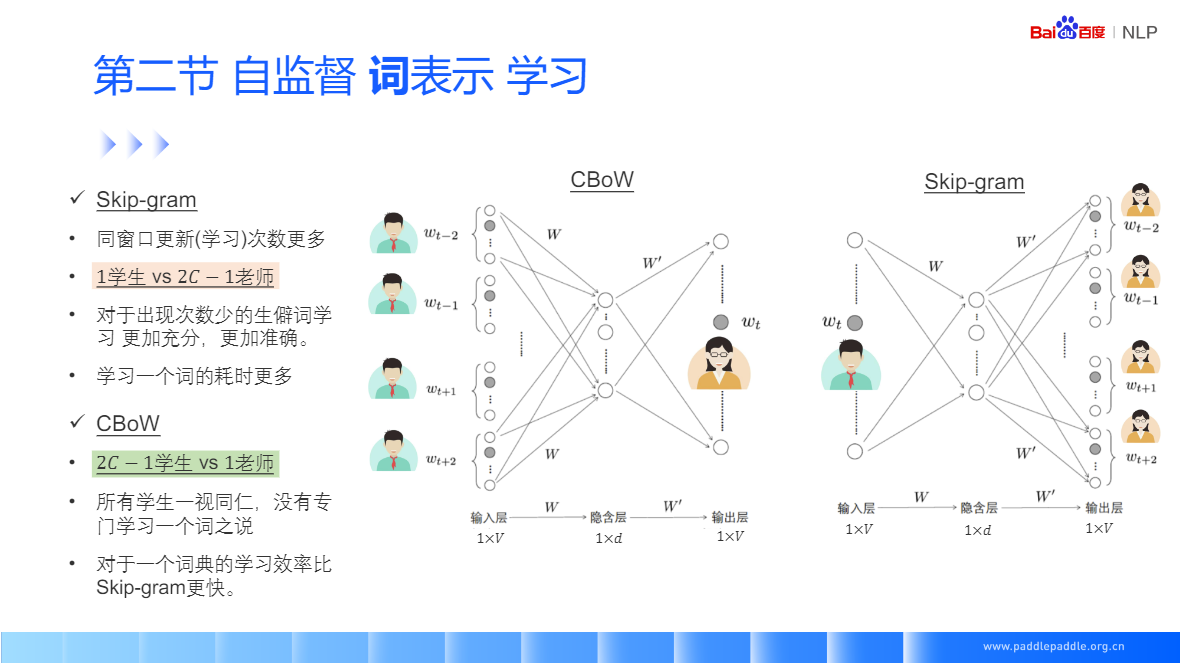
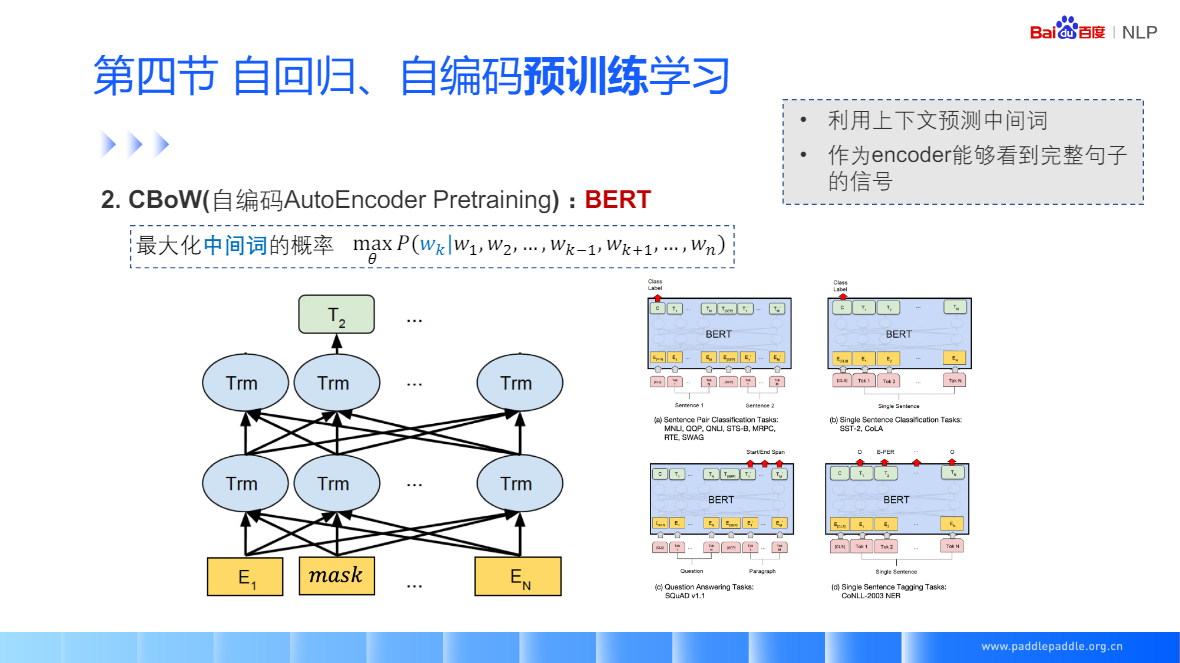
CBoW:给定一个上下文词,预测中间值

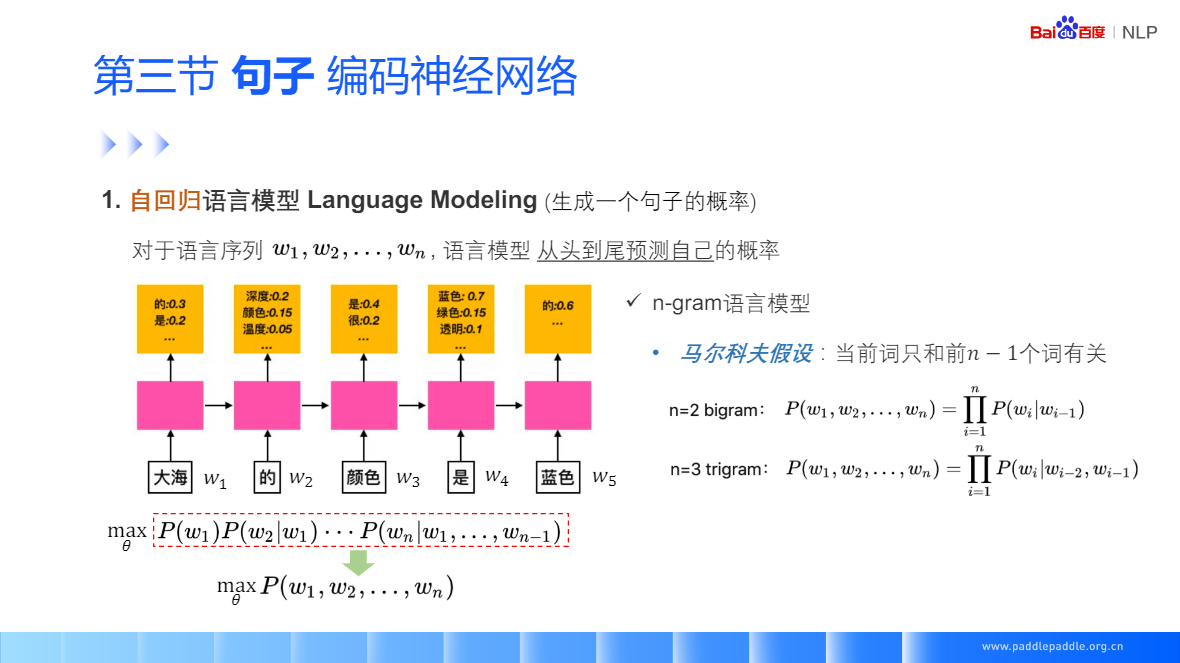
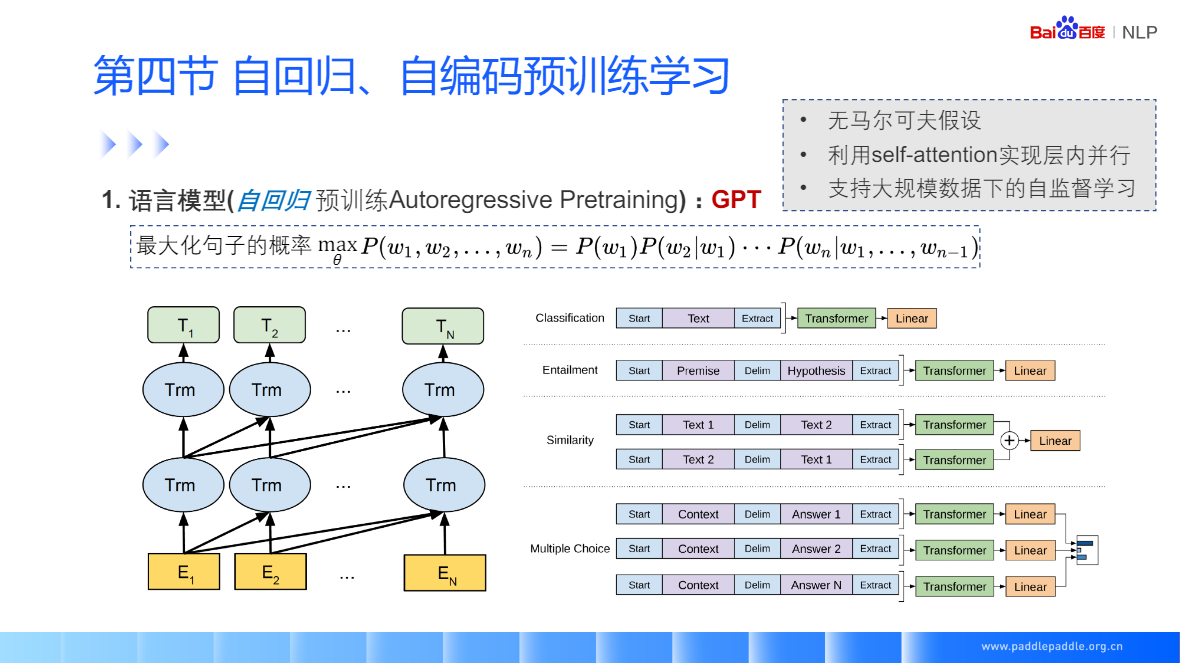
RNN 抛开马尔科夫假设,
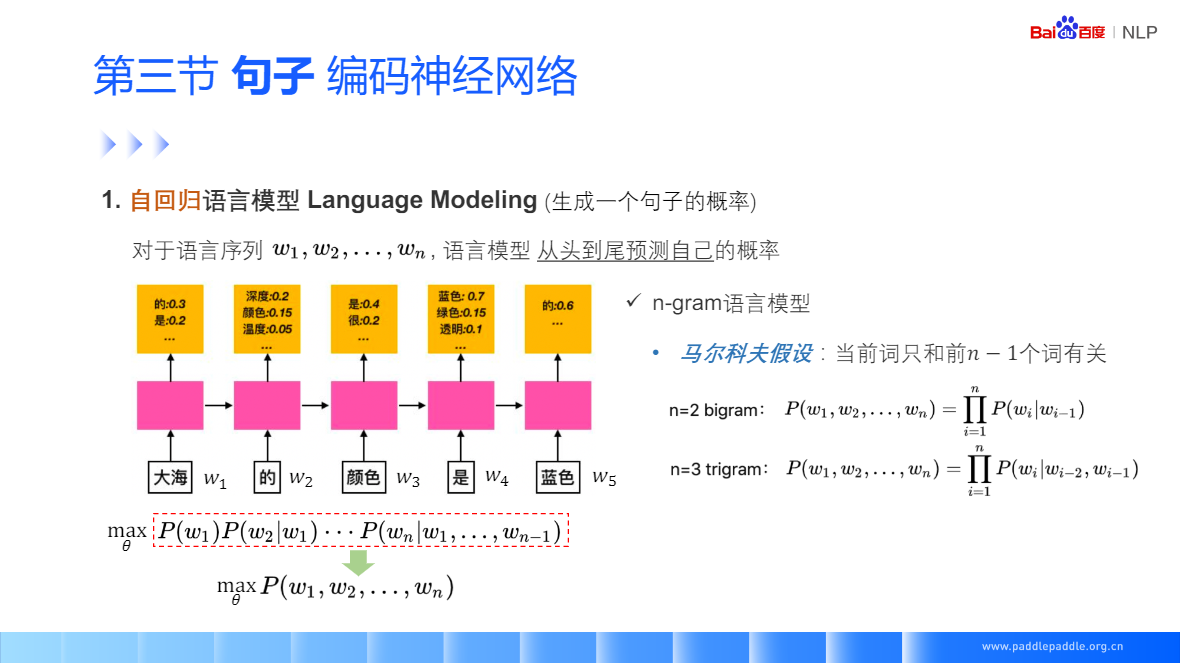
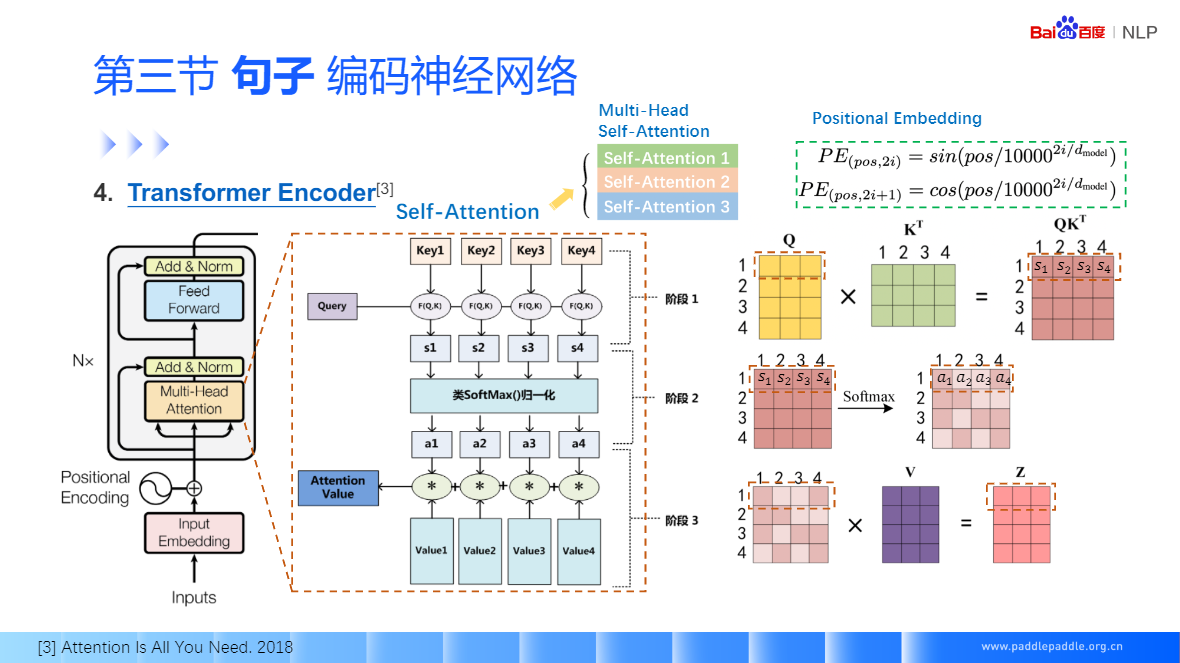
Self-Attention:每个单词和整句所有话进行匹配,来获取当前单词对每个单词的重视程度,利用这个重视程序,对整句话的每个单词进行加权,加权的结果用于表示当前这个单词
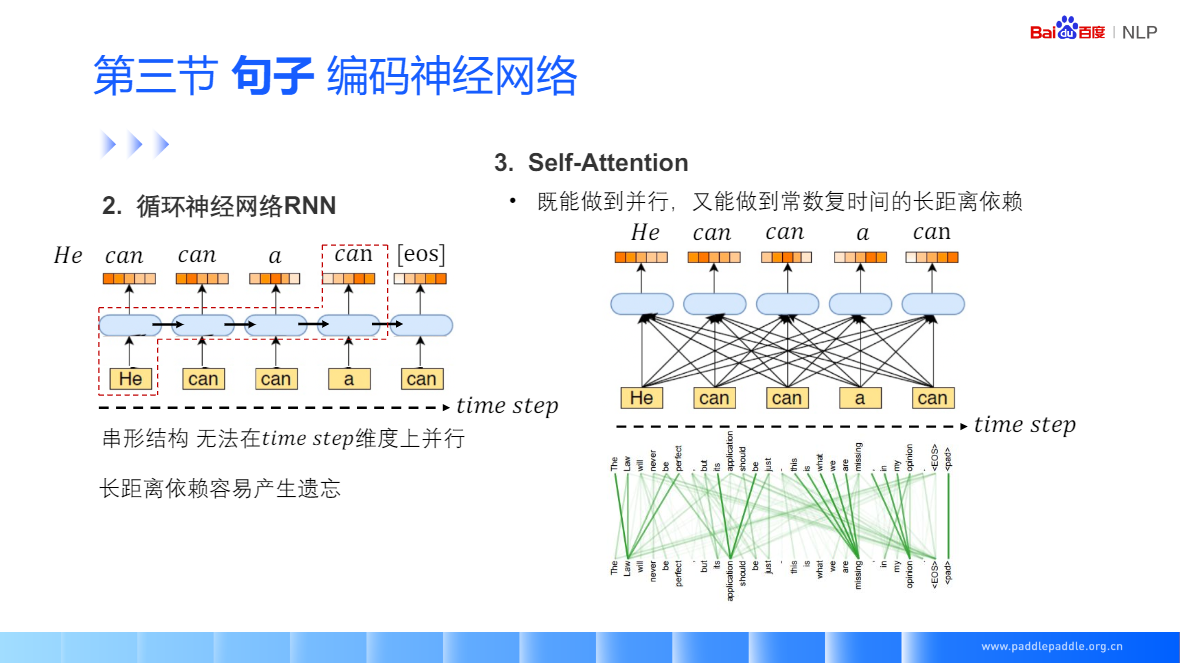
Self-Attention:也是非常流行的 Transformer 的核心模块,
Seft-Attention 没有考虑单词的顺序,所以为了更精装的表示位置信息,需要对句子的输入加个位置的序号 Positional Embedding
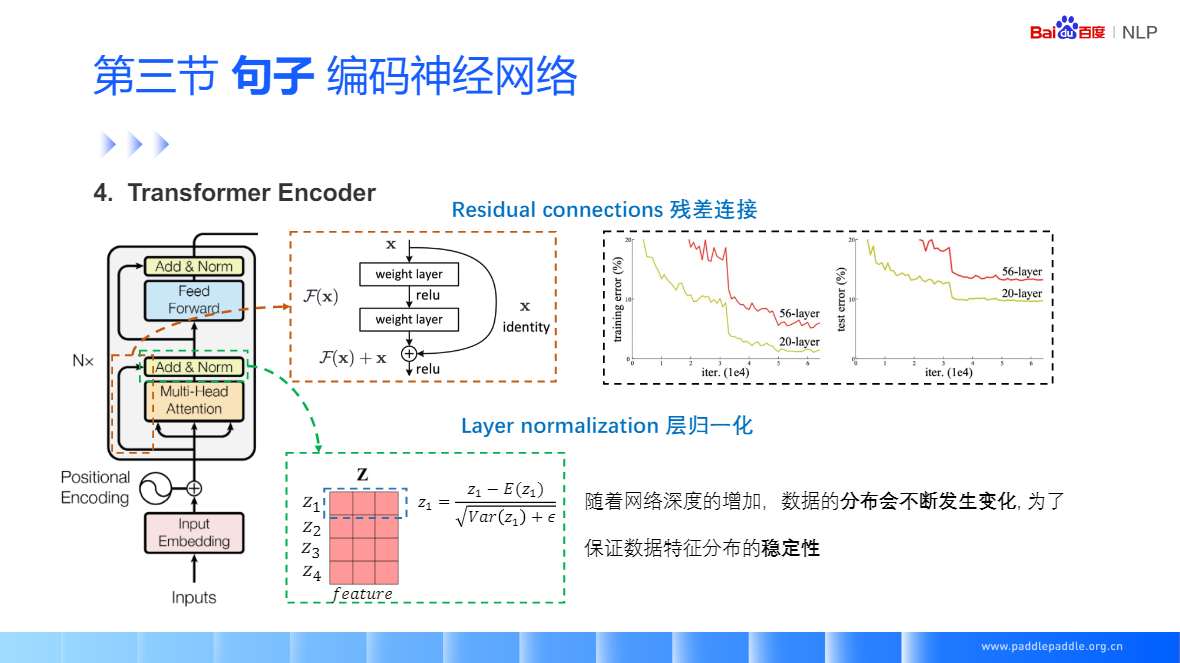
残差连接,很好的缓解梯度消失的问题,包括映射和直连接部分
https://aistudio.baidu.com/aistudio/education/lessonvideo/1451160
 登录查看全部
登录查看全部
参与评论
手机查看
返回顶部