此分类用于记录吴恩达深度学习课程的学习笔记。
课程相关信息链接如下:
本周为第二课的第二周内容,2.3到2.5和2.9到2.10的内容。
本周为第二课的第二周内容,和题目一样,本周的重点是优化算法,即如何更好,更高效地更新参数帮助拟合的算法,还是离不开那句话:优化的本质是数学。
因此,在理解上,本周的难道要相对较高一些,公式的出现也会更加频繁。
当然,我仍会补充一些更基础的内容来让理解的过程更丝滑一些。
本篇的内容关于指数加权平均数和学习率衰减。
我同样在最后增加了总结部分,但这部分内容我更建议以理解为主,因为这是之后的具体算法的基础,且只是公式较多,理解并不困难。
对这个概念,我们用一个例子来一步步引入,假定下面这组数据是一周的气温:
我们先从最基本的“平均”开始。
不用再多提,这组数据的简单平均为:
[bar{x}=frac{10+16+12+14+18+11+15}{7}=13.7 ]
而对于这种最基本的平均值,我们得到就是这一周气温的“平均水平”,在这个“平均水平”里,每一天的温度都是同等重要的。
因此,对于平均数,我们往往用它和数据本身作运算,用数据和平均值的运算来量化“波动”。
而现在,有这样一个问题:
假如我是一个爱家人的笨蛋打工人,在一周里,相比工作日,我更希望知道周六日的温度适不适合我带家人出游。 我想确认看看上周末的气温,但是我忘了上周的具体气温,只对一个平均值有印象。
那在这种情况下,我更希望这个平均值和周六日的气温更接近,而不是周六日的气温被工作日的气温“拉平了”。
应对这种情况的就是下一步:加权平均数。
继续上面的例子,我们希望“平均值”更贴近周六、周日的气温。
这时候,“每一天同等重要”的普通平均就不够用了,我们需要让“重要的日子权重大”,不重要的权重小,于是就有了加权平均数:
[bar{x}_w=frac{sum_{i=1}^n w_i x_i}{sum_{i=1}^n w_i} ]
其中, (x_i) 是数据,(w_i) 是权重,代表“这个数据点的重要程度”。
我们来看看,仍然是那组气温:
[[10, 16, 12, 14, 18, 11, 15] quad (text{周一到周日}) ]
现在为了让平均值更反映出周六日的温度,我们把工作日(周一~周五)权重都设为 (1),而把周六、周日权重设为 (3)。
那么加权平均值就是:
[bar{x}_w=frac{10+16+12+14+18 + 3cdot11 + 3cdot15}{1+1+1+1+1+3+3}approx 13.45 ]
你会发现它比普通平均 (13.7) 更偏向周末的气温(11℃、15℃)。
总结一下,加权平均数会往“权重大”数据靠近。
可是又有一个问题:上一周的气温不一定和这一周类似。
一年有四季,气温会随时间不断变化,尤其在换季的时候,可能这一周突然降温,而你上周的平均气温却还停留在“秋天的温柔”里。
在这种情况下,如果我们还继续对所有天数给固定权重,就会出现一个问题:
一个月前的周末和昨天的周末“权重”一样大,这是不合理的,因为在小范围里,过去越久的气温对预测明天的气温参考价值越小(再次强调小范围)
而现在,如果我想预测本周末的气温,更合理的做法应该是根据更近的信息去预测。
总结一下,在现在这个受时间影响的气温预测问题中:
你可能会说,那就按时间顺序,给越往前的数据越小的权重,这个思路是对的,可是实施起来,我们难度要每过一天,就给所有的数据排新的权重吗?
能解决这个问题的就是这部分的主角:指数加权平均数。
刚才我们说到了一个关键需求:
我们希望越新的气温越影响我们对当前“平均气温水平”的判断,越旧的数据影响越小。
如果继续用加权平均数,每过一天就重新给所有数据分配一次权重,这样不仅麻烦,还不够灵活。
于是,指数加权平均数出现了,他可以实现:
让旧数据的权重自动随时间“指数衰减”。
即越早的数据影响越弱、越近的数据影响越强,而我们完全不需要手动更新所有权重。
具体来说,我们给出一个参数:
[0
它叫“衰减因子”或 “平滑系数”,代表我们对“历史印象”的依赖程度,展开来说:
而具体实现这个逻辑的公式,也就是指数加权平均值公式就是:
[v_t = beta v_{t-1} + (1-beta)x_t ]
它的含义非常直观:
[今天我认为的平均气温水平= 一部分保留昨天的印象 + 一部分采纳今天的真实气温。 ]
我们仍然用这组数据来说明:
[[10, 16, 12, 14, 18, 11, 15] quad (text{周一到周日}) ]
我们固定设置 (v_0 = 0) 开始,并使用一个比较温和的参数: (beta = 0.3)
依次类推,(v_t) 表示到第 (t) 天为止,根据指数加权平均计算出的“当前平均值”
展开两个小问题:
把今天(第 (t) 天)的平均 (v_t) 展开,可以看到每一天对今天平均的影响:
[v_t = (1-beta)x_t + beta(1-beta)x_{t-1} + beta^2(1-beta)x_{t-2} + beta^3(1-beta)x_{t-3} + cdots ]
可以发现:
我们展开一下(beta=0.3) 时的权重衰减示例如下:
| 天数 | 权重 | 累计权重比 |
|---|---|---|
| 今天 | 0.70 | 70% |
| 昨天 | 0.21 | 91% |
| 前天 | 0.063 | 91.6% |
| 大前天 | 0.019 | 91.8% |
| 四天前 | 0.006 | 91.86% |
可以看到,当 (beta) 较大时,历史数据仍然有显著权重,指数平均“记忆长”;当 (beta) 较小时,历史数据迅速衰减,指数平均更重视近期数据。
我们可以用等效天数量化 (beta) 的影响:
[n_{text{eff}} = frac{1}{1-beta} ]
(n_{text{eff}}) 表示今天权重对应普通平均的天数,也可以理解为历史信息平均贡献的有效天数。
这样就可以根据需求确定一个较合理的衰减因子。
刚才我们用公式:
[v_t = beta v_{t-1} + (1-beta)x_t ]
计算得到指数加权平均值。
但是,如果我们从 (v_0 = 0) 开始,会发现前几天的 (v_t) 往往偏低。这是为什么呢?
原因很简单:初始值 (v_0 = 0) 并没有反映真实平均值,因为前几天的 EMA 都会被这个“零值”拉低,从而产生偏差。
举个例子:假设我们继续用前面的气温数据,(beta=0.3):
| 天数 | 实际气温 (x_t) | EMA (v_t) |
|---|---|---|
| 周一 | 10 | 7.0 |
| 周二 | 16 | 13.3 |
| 周三 | 12 | 12.39 |
你会发现,周一的 EMA (v_1 = 7),比实际温度 (10) 低得多;周二 (v_2=13.3),也略低于真实平均。
为了修正这种“初始偏差”,我们引入偏差修正:
[hat{v}_t = frac{v_t}{1 - beta^t} ]
其中:
继续刚才的例子,我们看看修正后的 EMA:
总结一下:EMA 的初始值会导致前几天平均被“拉低”,用 (hat{v}_t = v_t / (1-beta^t)) 可以快速修正偏差,同时也不影响后续数据。
我们在此之前一直用梯度下降法来不断调整参数,让损失函数越来越小。
在这个过程中,学习率(learning rate)控制每次参数更新的步幅,我们称其为一个超参数,需要我们手动地设置,但怎么设置,好像并没有一个公认的科学标准。
因为更好的方法是在训练中动态调整,而不是像我们之前一样使用一个固定值。
我们早说过:学习率设置得太大或者太小,都会影响训练效果:

在训练过程中,参数更新的路径往往不是一条直线,而是像爬山/下谷一样崎岖不平:
有时候,我们可能先到达一个局部最优点(Local Minimum),不是全局最优,但梯度很小,参数更新几乎停滞。如果学习率保持不变,我们可能永远停在这个局部最优,无法进一步优化。
要强调一点的是,在高维参数空间里,局部最优点往往不是局部最小值而是鞍点,大家了解即可。
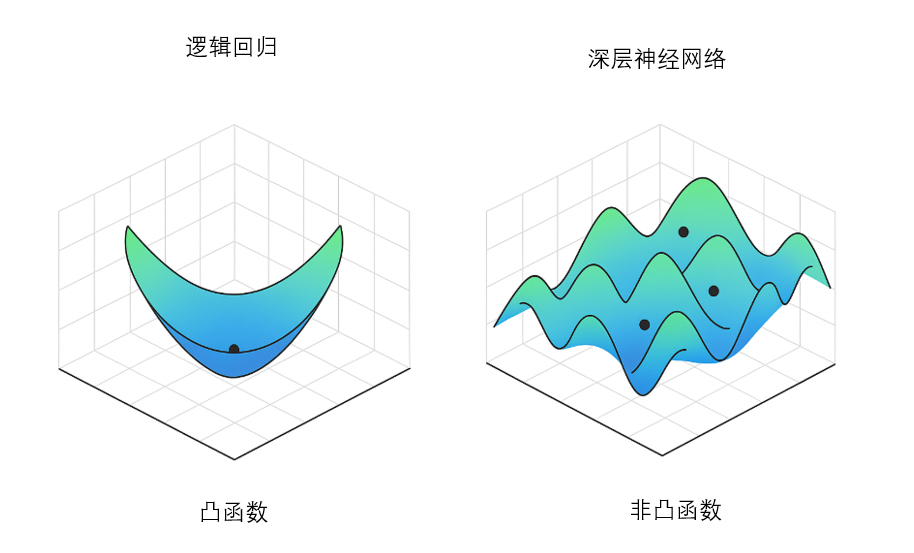
这就像走在山谷里,如果你步子太小,爬不出小山丘;步子太大,又可能越过真正的大山谷。
解决这个问题的一个策略就是先大步快走(大学习率),再小步精修(小学习率)。
这也是学习率衰减的核心思想:
和 EMA 类似,学习率衰减也可以看作随着训练步数,历史信息逐渐被“淡化”,步幅逐渐变小。
常见方法有以下几种:
最简单的方法:每隔固定训练轮次,将学习率缩小一个比例。
公式:
[eta_t = eta_0 cdot gamma^{lfloor t / T rfloor} ]
其中:
| epoch | 学习率 (eta_t) |
|---|---|
| 1~10 | 0.1 |
| 11~20 | 0.05 |
| 21~30 | 0.025 |
可以看到,学习率像阶梯一样逐步降低,训练初期大步,后期小步。
和 EMA 很像:每一步训练后,学习率按指数规律衰减:
[eta_t = eta_0 cdot e^{-lambda t} ]
| epoch (t) | 学习率 (eta_t = 0.1 cdot e^{-0.1 t}) |
|---|---|
| 1 | 0.1 × e^{-0.1 × 1} ≈ 0.0905 |
| 2 | 0.1 × e^{-0.1 × 2} ≈ 0.0819 |
| 3 | 0.1 × e^{-0.1 × 3} ≈ 0.0741 |
| 4 | 0.1 × e^{-0.1 × 4} ≈ 0.0670 |
| 5 | 0.1 × e^{-0.1 × 5} ≈ 0.0607 |
另一种方式是按时间倒数衰减:
[eta_t = frac{eta_0}{1 + lambda t} ]
| epoch (t) | 学习率 (eta_t = frac{0.1}{1 + 0.05 t}) |
|---|---|
| 1 | 0.1 / (1 + 0.05 × 1) = 0.0952 |
| 2 | 0.1 / (1 + 0.05 × 2) = 0.0909 |
| 3 | 0.1 / (1 + 0.05 × 3) = 0.08696 |
| 4 | 0.1 / (1 + 0.05 × 4) = 0.0833 |
| 5 | 0.1 / (1 + 0.05 × 5) = 0.08 |
有些优化器内置类似 EMA 的机制,自动根据历史梯度调整每个参数的有效学习率:
| 概念 | 基本原理 | 比喻 |
|---|---|---|
| 平均数(Mean) | 对一组数据求算术平均,每个数据权重相同 | 所有数据都是等重要的朋友,每个人的意见一样 |
| 加权平均数(Weighted Mean) | 给不同数据分配不同权重,权重大 → 更影响平均值 | 更重要的人意见更大,比如周末气温对出游更重要 |
| 指数加权平均数(Exponential Moving Average, EMA) | 历史数据权重按指数衰减,越新的数据权重越大;公式 (v_t = beta v_{t-1} + (1-beta)x_t) | 记忆力随时间衰减:最近的印象更鲜明,旧印象慢慢淡忘 |
| EMA 偏差修正(Bias Correction) | 解决初始值导致前期平均被拉低问题:(hat{v}_t = v_t / (1-beta^t)) | 刚开始看信息时容易低估真实水平,修正后更准确 |
| 学习率(Learning Rate) | 控制梯度下降每次更新参数的步幅 | 下山步子大小:步子大 → 快但可能蹦过谷底,步子小 → 精确但慢 |
| 学习率衰减(Learning Rate Decay) | 随训练进程逐渐减小学习率,提高收敛稳定性 | 先大步快下山,再小步精细找谷底 |
| 固定衰减(Step Decay) | 每隔固定步数按比例缩小学习率 | 爬山每隔一段路就换小步走 |
| 指数衰减(Exponential Decay) | 学习率随训练步数按指数规律连续衰减 | 步子逐渐变小,前期快,后期慢 |
| 1/t 衰减(Inverse Time Decay) | 学习率按时间倒数衰减 | 前期快跑,后期慢慢走 |
| 自适应学习率方法(Adaptive LR) | 每个参数根据历史梯度调整步幅,类似 EMA 机制 | 每个腿根据走路经验自动调节步子大小,更聪明地下山 |
 登录查看全部
登录查看全部
参与评论
手机查看
返回顶部