说明:
我一般会把数据库中的数据类型,简单分为三类:
数据库的能力边界:
其实,关系数据库也能比较好处理半结构化数据,比如 Json,可以基于 Path 来访问具体的数据,Json Path 就有点类似于我们关系数据表的列的概念。而且,半结构化数据,是可以拆解成结构化数据的,基于关系数据库的能力,我们是可以对半结构化数据做存储和计算的。
除了上面提到的结构化数据和半结构化数据,还有一类,叫做 “非结构化数据”:
在现实世界中,非结构化数据占比 80% 以上。但这些数据,绝大多数都只是存储,没有计算。
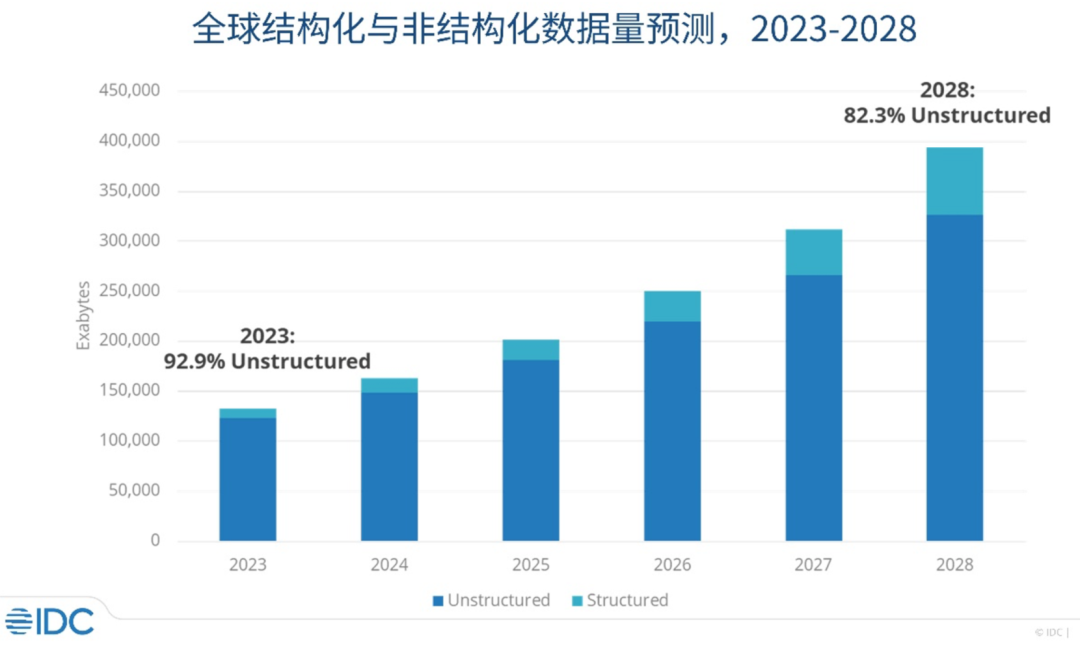
而在 AI 时代,数据只有能被计算,才能产生价值。
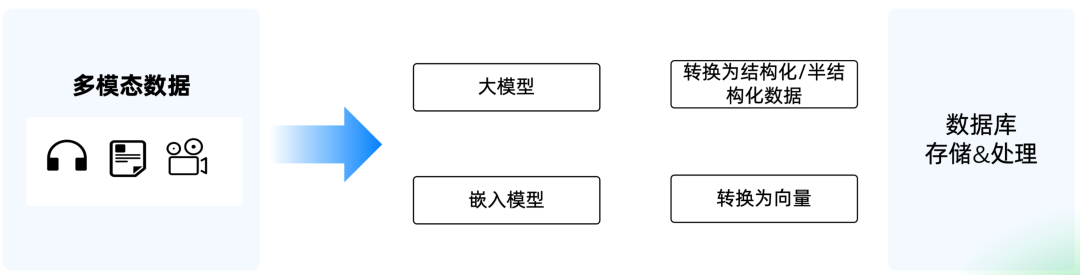
GenAI 带来了通用大模型。
在数据处理上,总结下来,大模型有两类能力:
在 GenAI 时代之前,非结构化数据是不是能被处理?其实也是可以的,只不过非常 “复杂”,需要进行 “定制”。
之前核心技术就是机器学习,在 GenAI 时代,这种技术门槛更低、更通用,也更便宜。
大模型的维度都是以 B(Billon)为单位,嵌入模型一般都在 1K 维左右。
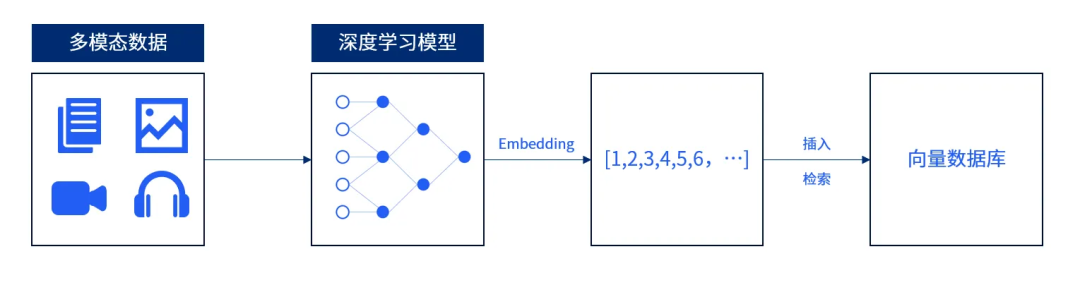
嵌入模型能捕获非结构化数据的 “隐形” 特征,然后将这些特性用高纬向量来表示,通过计算 2 个高纬向量的距离(比如 Cosin / IP 距离)等,来近似代替 2 个非结构化数据的相似度。相关内容详见:《浅入了解向量数据库》。
向量其实是一个半结构化数据(前面讲过,数据库只能高效处理结构化 / 半结构化数据),比如一个 1024 维度的向量,其实是一个 1024 个元素的 Array,每个 Array 都是一个 Float 类型。
在传统数据库中,非结构化数据是不可比较的,比如 2 张照片通过二进制比较完全没有意义。通过嵌入模型,2 个非结构化数据,就可以比较了(不过传统关系数据库的大小比较有些不同,这里是 “相似度” 比较),也就是这个 “可以比较了”,打开了非结构化处理的大门。
说明:
传统的关系数据库,最基础的数据处理其实也是比较,排序、过滤,甚至于扫描,都是基于比较的能力。
下图是个很常见的二维空间的例子。财富和相貌,是向量的 2 个维度。向量的每一个维度,就是非结构化数据 “隐形” 的一个特征。可以看到,在空间坐标系里,距离越近的 2 种生物,就越相似(这个也是最简单向量数据库的原理)。

大家可以用反证法,先想象一下,在 AI 时代,如果只有大模型而没有向量数据库,会出现什么样的场景?
假设我有 100w 张图片,每次找相似的图片的时候,都绕过向量数据库,直接透传给大模型来处理。然后你就会发现:大模型超级慢,即使是不带推理的 Deepseek R1,也只能秒级出结果。(传统关系数据库的数据处理可是毫秒级,直接相差了 3 个数量级)。所以,在整个 AI 应用的数据链中,向量数据库不是瓶颈,大模型才是。
所以,大模型不适合大量的数据实时处理,向量数据库更合适。在处理海量数据的时候,正常思路只能是:向量数据库做初筛,大模型做总结 / 二次加工。
大模型有幻觉,这个是大家公认的。大模型可以回答很多,但是有可能很多是“胡说八道”。主要原因是大模型的知识是靠训练数据集来的,但是很多企业内的数据是不公开的。
大模型处理数据的上下文是有 “窗口大小” 的,比如 GPT-4 是 8K。一方面没有办法一下子给大模型塞整个企业的数据进去处理,另外大模型在处理特定问题的时候,也需要更加 “专注”,也就是说:少量非常相关的信息就可以了,不需要大量无关的信息。
在这个过程中,就不得不请出向量数据库,让它用最快的速度,过滤出和用户问题最相近的知识,然后交给大模型做总结。
综上,AI 时代最常见的一个需求就是海量非结构化数据的近实时检索,现在,只有向量数据库能干。一般的 AI 解决方案,就是 “向量数据库 + 大模型” 相互配合,向量数据库的 “近实时检索” + 大模型的 “通用智能”。
所以毋庸置疑,向量数据库这个玩意儿,已经是 AI 时代数据库进化路线的重要一环。
最近一段时间,除了专业向量数据库,其他关系型数据库、noSQL 数据库、各种搜索引擎,也都开始逐步支持向量存储和检索的能力。
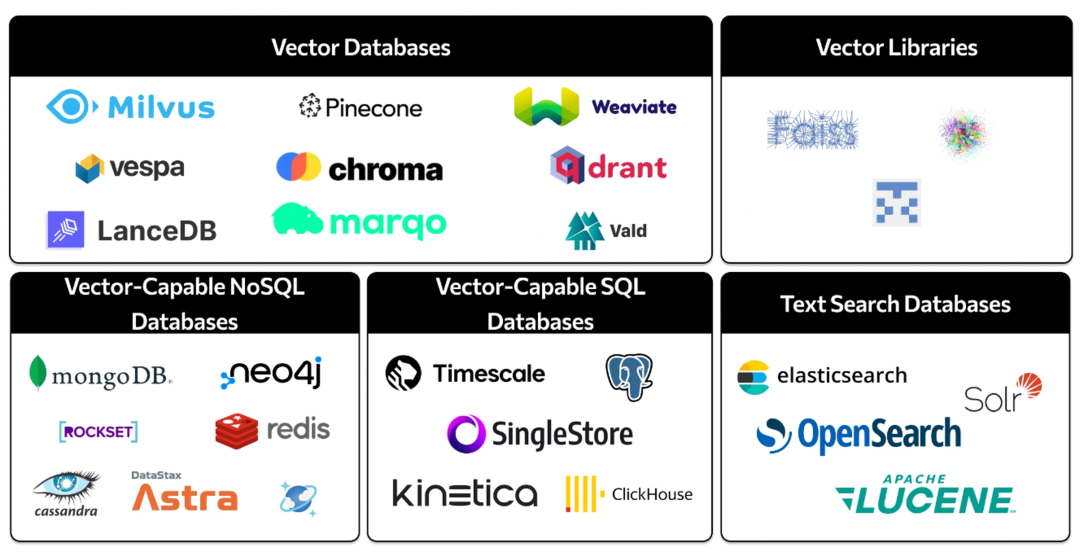
目前,不同数据库的向量能力演进路线可能会略有不同。但在不久的未来,大概率会殊途同归,即:向量(vector)会成为数据库中,和数字类型(number)、字符串类型(string)一样的基础数据类型。

这里多解释一句,上图中把向量索引单独从普通二级索引中抽离出来,主要是因为向量类型的检索开销较大,而且检索结果只要求近似而非绝对,所以会有一种独特的索引形式 —— 向量索引。
同理,全文索引、空间索引等,大致也是类似的原因。
最近一段时间,数据库行业里的很多公司和大佬,都在纷纷发布一些混合检索的原理和实践类文章。Why?因为支持混合检索的数据库已经逐步成为了 AI 时代的刚需。

那什么是混合检索?与其给出定义,不如直接举个例子来的方便。
比如基于蚂蚁百宝箱搭建的一个餐饮推荐 AI Agent 系统,会把用户的自然语言提问,转换成对知识库的搜索。

在上图的这个提问中:

上图是某知名保险行业 ISV 的智能体整体架构图。
各个 Level 的依赖可以简化如下:
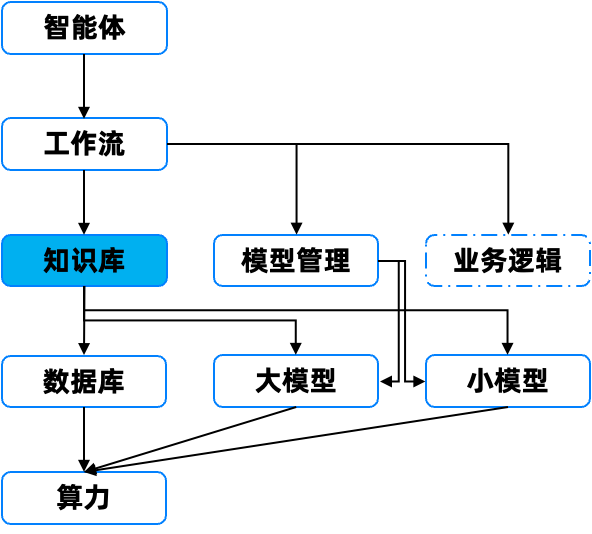
绝大多数 AI 应用的架构都可以简化为上述架构图,例如:通用的知识库平台(各类问答助手)、智能体推荐系统(飞猪的旅游推荐)、类似于 Cursor 的智能编码助手、行业 AI 助手(数据库运维监控智能体)……
接下来,再针对上面这张图多说两句:
基于上述讨论,我们可以基本达成一个共识,就是:知识库是影响 AI 应用效果非常重要的一环,而知识库的效果,强依赖于数据检索的质量和效率。所以,对于 AI 时代的数据库来说,就必须要为用户提供 —— 准确 & 高效的实时混合检索以及数据处理能力。
知识库(RAG,检索增强生成)的最终目标还是模型生成的效果,各个语言大模型类请求上下文窗口一般在 128K 以下,而且喂给模型的请求包含很多信息,比如提示词、记忆、从知识库中检索的信息。
大模型拥有比较强大的泛化能力,但是最终效果还是需要依赖整个请求中的上下文信息。理想情况下,我们希望把更多的信息塞给大模型(如果可以的话,最好能直接整个知识库都填鸭式地塞给大模型),这样能取得最好的效果。
但是实际情况是,大模型的上下文窗口比较小,而且塞的越满,模型效果就可能越差。受限于大模型的上下文窗口大小,每个 token 都珍贵,最终塞给大模型的数据要尽量有相关性、精炼、准确。
下面是 Chroma 的创始人 Jeff Huber 在分享 Context Engineering 的概念时,报告里的一张折线图。可以很直观地看出,随着上下文长度不断增加,模型的效果会有明显的衰减。
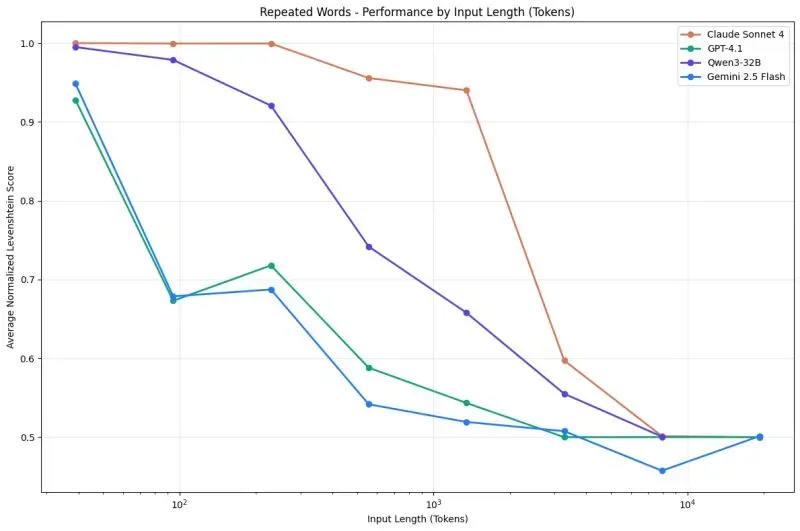
虽然最近 DeepSeek-OCR 模型重新定义了 AI 的输入和输出(从文本到像素),能够在一定程度上对数据进行压缩(详见:《用最纯粹的语言,解析 DeepSeek OCR》)。然而,知识库一般都非常庞大,如何高效地从一个超大数据集找到大模型强依赖的信息,依然尤为重要。
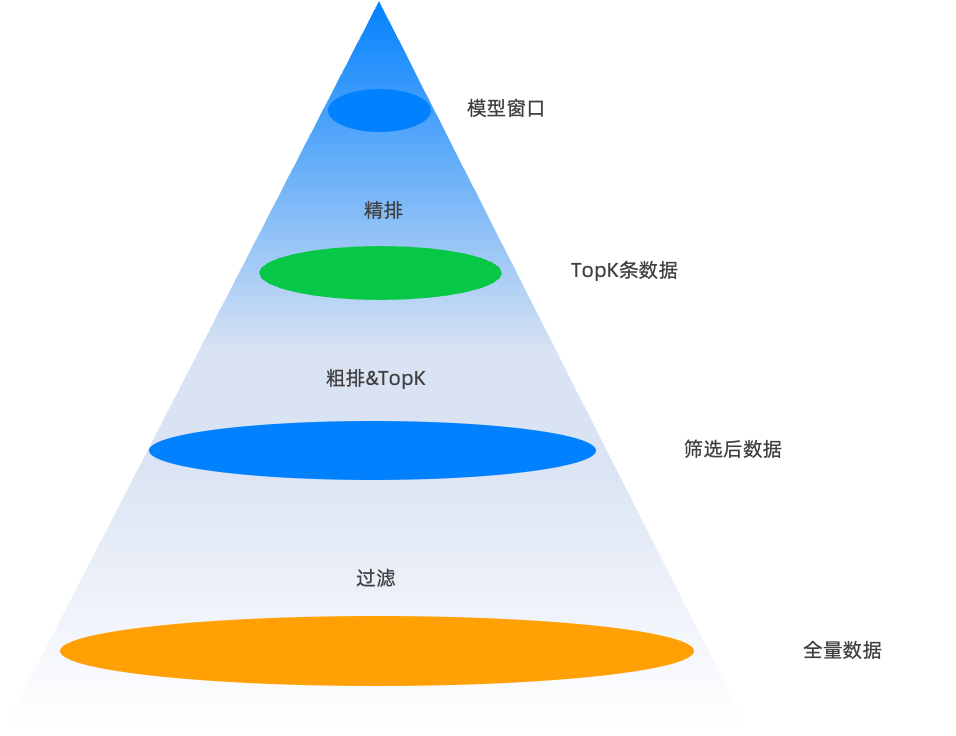
如上图,从全量数据到模型窗口之间,形成了一个大漏斗。这里有几个概念需要再多解释一下:
圈数据很重要,很多数据库都会支持,比如 ES / Mongo / 关系数据库,每种数据库适用的场景也不尽相同。
对于 ES 等 NoSQL 数据库,一般只支持单表操作,设计上往往是反范式,会把一个业务场景的所有数据字段都放到一张表中,经常会形成一张大宽表。
对于一些依赖范式的 “一对多” 的能力,比如一个人有多个电话号码,ES 往往使用嵌套结构来实现。但是反范式的大宽表 + 嵌套结构的方式,往往会带来更新代价大,数据一致性等问题。所以一般是在一致性 / 实时性要求不高的边缘系统中出现,核心系统一般还是会选择关系型数据库。
关系型数据库基于关系范式,一个业务场景,往往会有多张表,每张表各司其职,多张表间有外键等关联。关系数据库优化器比较重要的能力是在各张表中选代价最低的索引以及在多张表间选择最优的 Join 顺序以及算法,整体扩展性和灵活性更好。
单一的粗排手段,往往有很多不容易被覆盖到的场景。比如召回一堆基于模版生成的数据,使用单一向量数据库不能很好的区分;比如需要召回多语言、有同义 / 近义语意的数据,只是基于关键字的搜索引擎也不能很好地解决。所以在实际工程中,往往会把多种召回方式(稠密向量、稀疏向量、搜索引擎、图等)混合使用。
基于多路检索的粗排,会带来如下几个问题:
因此,混合检索在粗排阶段的优势也非常明显。也就是说,如果一款数据库可以支持多模数据类型,那就可以基于同一份数据,同时支持向量、全文等排序方式,并且是将多路检索融合到一个算分排序框架中,在给粗排带来更高精度的同时,也避免了数据一致性 / 成本 / 易用性等问题。
在多路检索中涉及到向量以及重排(精筛)时,因为向量依赖嵌入模型,精筛依赖重排模型,而目前的向量 / 关系数据库都不支持在 DB 内调用模型,所以会导致整个流程十分复杂,涉及到应用和 DB 的多次交互。如下图所示:
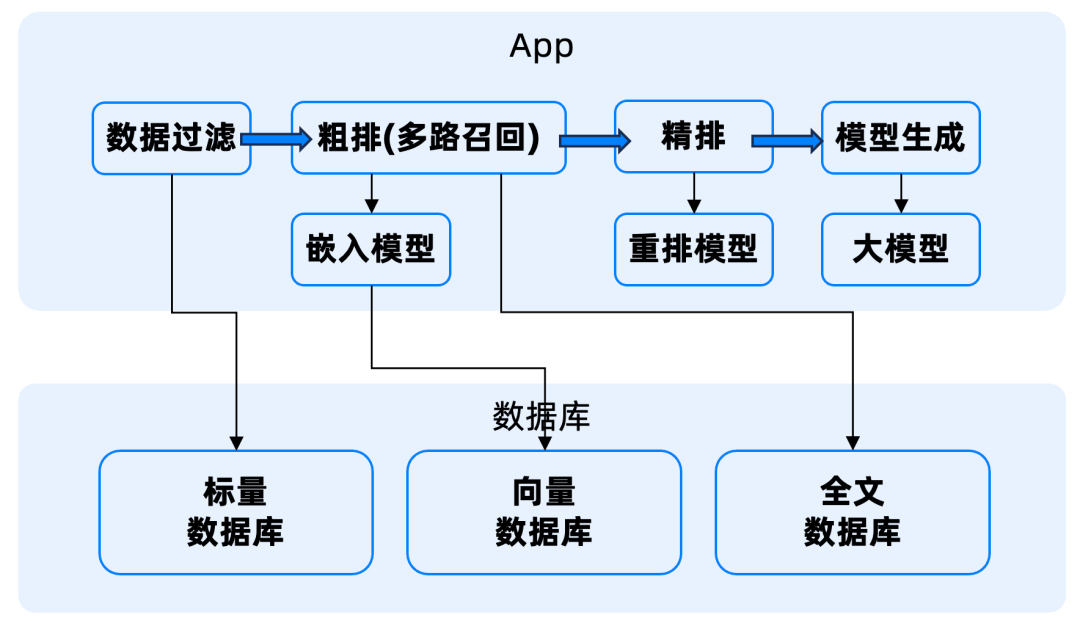
因此,未来数据库的混搜框架中,需要内置 AI Function 的能力,支持嵌入模型、重排模型、大模型的调用。
无论是数据写入触发的索引构建流程中的向量 Embedding 生成,还是查询时候查询语句的向量 Embedding生成,都应该让数据库自动触发。在集成 Embedding 的 AI Function 能力后,用户可以不感知向量的存在,向量隐藏在数据库自身的索引表中。
数据库需要集成 Embedding 的原因是:
除此以外,用户还可以考虑显示调用 Rerank 模型的能力,在粗排之后,调用 Reranker 的 AI Function 即可。
至此,正文结束。这篇文章没有涉及过多的混合检索底层实现原理和使用上的最佳实践,后面再继续更新吧。

对混合检索实现原理感兴趣的老师们,欢迎继续观看下面这个视频(如果能点赞、收藏、留言就更好了)。
最后,这篇文章可能会有很多疏漏以及表述不当的地方,希望各位老师多多在留言区批评和指导。
接下来,就是大家期待已久的广告时间了~
因为在最前面说了在正文部分不会包含和数据库厂商相关的内容,所以数据库厂商在混合检索方面的能力、性能对比,就不得已放到了最后的这个 “广告时间” 中。
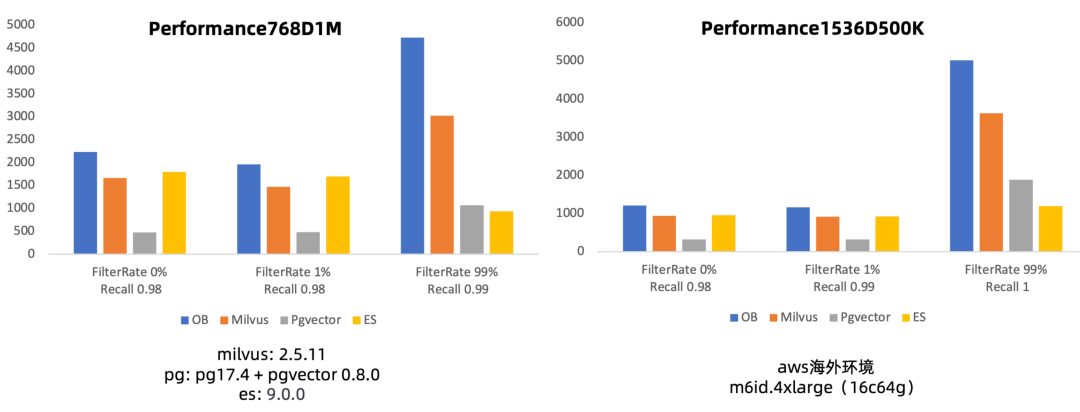
OceanBase 内置了 AI Function 的能力,支持嵌入模型、重排模型、大模型的调用。
目前 OceanBase 已经把 AI Function 的能力融入到整个混搜的框架中。
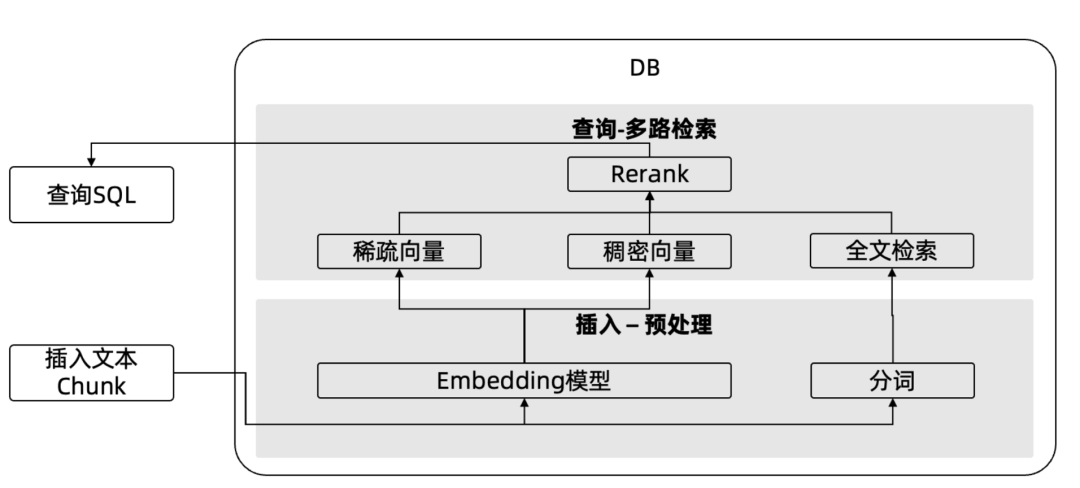
整个混合检索过程中的圈数、粗排、精排,都可以完全融入到 OceanBase内核,用户可以直接向 OceanBase 中插入文本 Chunk,查询的时候直接使用原始自然语言字符串做查询,实现真正意义上的 Data In,Data Out,让整个 AI 多路检索更加简单和高效。
OceanBase 4.4.1 社区版已经在 10 月 24 日正式发布,混合检索的能力得到了进一步的提升,欢迎大家来下载和试用。
以下内容摘自 OceanBase V4.4.1 CE 版本的 release notes[1]:
文档详见:OceanBase 官方文档《向量索引混合检索》[2]。
下载地址:OceanBase 软件下载中心[3]。
To be continue.(这款产品会在 OceanBase 2025 年度发布会[4]上的 “开源之夜” 环节中正式亮相,欢迎大家关注)
参考资料
[1]
OceanBase V4.4.1 CE 版本的 release notes: https://www.oceanbase.com/product/oceanbase-database-community-rn/releaseNote_#V4__.4.1_
[2]
OceanBase 官方文档《向量索引混合检索》: https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000004020382_#3__-title-%E6%99%AE%E9%80%9A%E6%A0%87%E9%87%8F%E6%A3%80%E7%B4%A2_
[3]
OceanBase 软件下载中心: https://www.oceanbase.com/softwarecenter
[4]
OceanBase 2025 年度发布会: https://www.oceanbase.com/conference2025
 登录查看全部
登录查看全部
参与评论
手机查看
返回顶部