01 动机与背景
Facebook Presto是一个以SQL语言作为接口的分布式实时查询引擎,可以对PB级的数据进行快速的交互式查询。它支持标准的ANSI SQL.包含查询、聚合、JOIN以及窗口函数等。
Alluxio将其在数据层的创新作为Presto和各种分析应用程序和用例的关键支持技术。它创建了一个虚拟数据层,可以聚合来自任何文件或对象存储的数据,提供跨存储系统的统一命名空间,并允许应用程序继续使用原有的行业标准接口来访问数据,同时能够为Presto提供内存级别的速度和响应时间。
为了提高请求的响应速度,Presto正在探索缓存容量与缓存命中率对于性能的影响。Presto需要通过Alluxio知道某些关于缓存的信息,从而判断当一个集群被缓存大小所限制时,扩大缓存容量是否能够帮助集群提高缓存命中率以及请求的响应速度。同时这些信息也能够对探索缓存算法潜在的优化策略提供一定的帮助。在此基础上,为了更好的负载均衡和效率,Presto想要通过这些信息优化缓存扩容的路由算法。于是如何更好的对Alluxio缓存数据进行追踪管理,就成了presto优化决策的关键。
针对上面Presto提出的需求,我们提出两个关键问题:
运行的应用程序需要多大的缓存?
缓存的命中率提升的极限在哪里?
我们提出Shadow cache:用于追踪工作集大小和缓存命中率的轻量级Alluxio组件。首先为解决第一个问题,Shadow cache会告知管理者在过去24小时之内缓存一共接受到了多少互不重复的bytes,依此可以估计出未来缓存的需求量。此外为解决另一个问题,Shadow cache将会告知管理者在缓存能够将过去24h的所有请求全部保留的情况下请求命中缓存的数量,也就是说,未命中的都是从未出现过的数据,而这就意味着得到了缓存最大命中率。
这个轻量级的Alluxio组件Shadow cache能够提供相当于无限缓存空间下,缓存工作集大小以及缓存命中率的趋势。因此,我们定义以下关键指标,希望这些指标能够为我们观察集群缓存状态提供帮助:
C1: 在一段时间内的真正的缓存占用空间大小
C2:Shadow cache在一个时间窗口中的工作集
H1:真实缓存命中率
H2:Shadow cache的缓存命中率
02 挑战
想要为Alluxio的缓存提供上述指标是十分困难的,在实践尝试的过程中我们也遇到了方方面面的问题,我们将Shadow cache面临的挑战归类为以下三个方面:
低开销:作为一个跟踪缓存工作集大小的轻量级组件,留给Shadow cache的内存很小,利用有限的内存去追踪“无限”的工作集是相当困难的。另外,由于Shadow cache是在每次应用查询缓存时对本次查询的数据进行处理,Shadow cache也必须要做到低CPU开销,否则将会导致用户的请求被长时间堵塞。
高精准:Shadow cache也必须要有精度上的保证,在Presto中,Shadow cache被用于评估集群的缓存状况,如果估计的极限缓存命中率过小,可能会使Presto错误的判断此作业是缓存不友好的;相反的,如果估计的极限缓存命中率过大,可能导致Presto认为此时集群扩大缓存能够极大地提升整体性能。
实时性:Presto以及其他大多数应用在如今都只关心能够反映当前或未来趋势的最新项。因此,实时地将过时的项丢弃对于Shadow cache也是相当重要的。否则,很有可能对决策带来噪音干扰。【滑动窗口】便是记录最新项的著名技术之一,然而为滑动窗口模型设计数据结构也不是一件简单的事情。每当窗口滑动时,都需要我们实时地删去那些刚刚被移出窗口的项。如何找到需要被删的项以及尽量快的删去它成为了一个重要的问题。
03 实现方案
既然提到了高精准与低开销两个需求,那么我们首先就想到了在各类分布式数据库中大放异彩的布隆过滤器,基于布隆过滤器,Shadow cache便完成了对工作集大小和极限命中率的估计。下面我们来对布隆过滤器做一个简单的介绍:
布隆过滤器:满足开销小与精度高的要求
布隆过滤器是一个以bit为单位的初始化全0的数组,它将每个项映射为几个bits,极大的节省了空间上的开销,并能够以极高的效率进行查询。布隆过滤器能够判断项是否存在,若布隆过滤器返回该项不存在,则项一定不存在。反之,则该项不一定存在。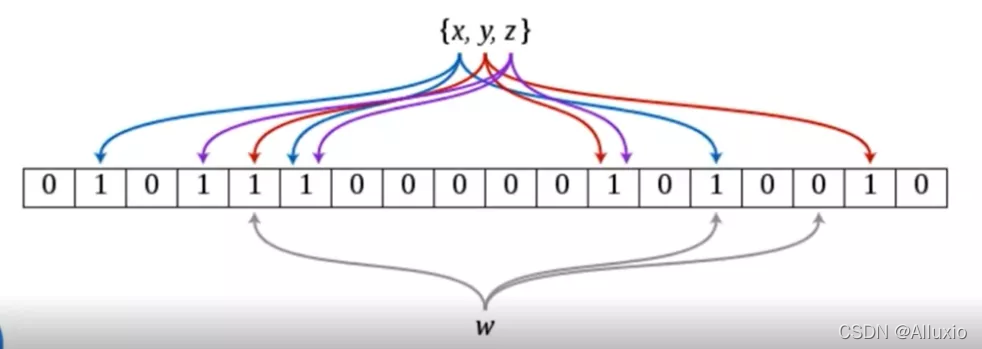
布隆过滤器拥有k个hash函数,在插入一个项时,会对此项分别进行k次hash运算,并得到k个位置,将在过滤器中对应位置的bit将被置为1。而需要查询时,则仍然对项进行k次hash运算,若得到的k个位置上所有bit都为1,那么判断此项存在,否则判断此项不存在。具体过程如上图所示。
实时更新!布隆过滤器链
既然布隆过滤器能够同时满足开销小和精度高的两种需求,那么我们能够直接将布隆过滤器应用于Shadow cache中吗?
首先我们遇到的问题就是布隆过滤器不支持删除,我们不关心比较久远的工作集负载情况,而只关心用户的应用程序在过去的一段时间中的工作集大小,这就要求Shadow cache必须做到能够将过时的项删去,为了做到这一点,Shadow Cache将多个过滤器连接到一起,组成了布隆过滤器链。下面我们来看看如何通过布隆过滤器链,实时地对工作集负载大小进行更新
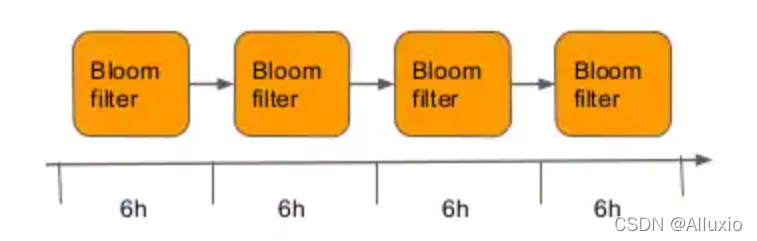
查询:如上图所示,Shadow cache是由多个布隆过滤器所组成的链,如果我们需要跟踪的是用户过去24h的工作集大小,那么可以将24h分为4个时间段,对应每个时间段Shadow cache有一个布隆过滤器,每个布隆过滤器都跟踪一个时间段。对于一个项的查询,Shadow cache会将所有布隆过滤器相“或“得到新的布隆过滤器,再对新的布隆过滤器进行此项的查询,如下图所示: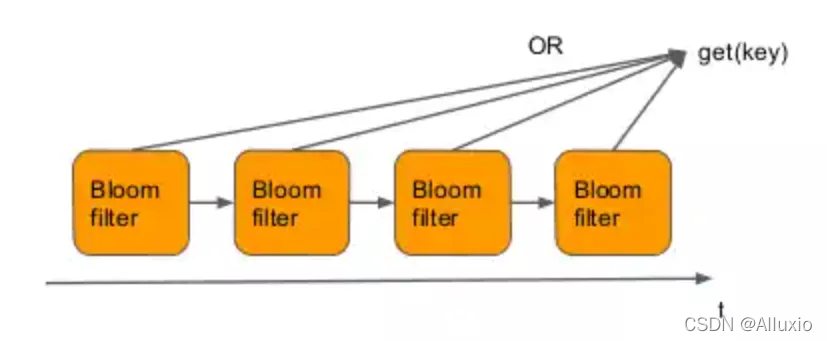
更新:而为了保证数据的实时性,当时间窗口进行滑动时,我们需要Shadow cache丢弃已经过时的数据。也就是说需要随着时间t不断更新布隆过滤器中的数值,将布隆过滤器中已经处于时间窗口外的项删掉。如下图所示,由于我们是将多个布隆过滤器组合在了一起,因此,很容易判断过时的项的位置,它们就处于最末端的布隆过滤器中。于是每当一个新的时间段到来,我们就从链中删去最老的过滤器,并新增一个全空的过滤器来记录最新数据。
工作集大小:布隆过滤器将一个项映射为多个 bits,若将工作集大小直接判断为bit为1的数量将会带来不可接受的误差,因为某一bit可能代表多个项,而某一项也被分散为了多个bits,于是在这里我们使用了Swamidass & Baldi (2007) 所推导出的以下公式对工作集大小进行估算,并取得了良好的效果: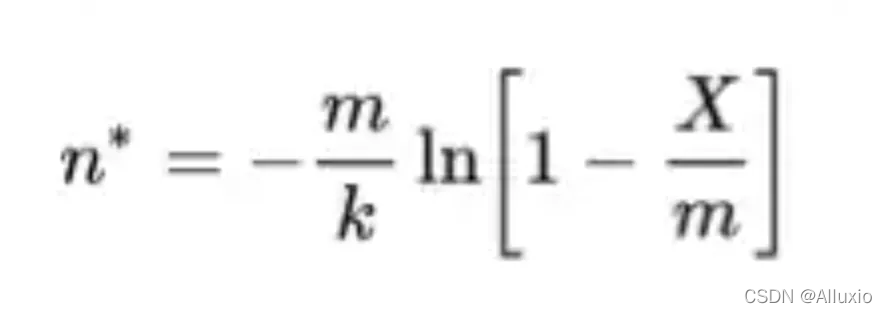
其中是被插入进过滤器中所有元素的估计值,m是过滤器的长度(大小),k是hash函数的个数,X是所有被置为1的位置的个数。
极限命中率:在提供了工作集大小这一指标后,Shadow cache还需要提供极限命中率这一指标。由于布隆过滤器能够以极小的内存使用量跟踪巨量的数据,我们可以将布隆过滤器视作一个空间大小为无限的缓存,因此,“用户请求“命中布隆过滤器的数量就相当于命中一个无限大小的缓存的数量,我们将此数量记为hit,而“用户请求”的总数量记为queryNum,于是极限命中率就等于hit/queryNum。
利用Shadow cache判断Presto集群缓存状态
在完成布隆过滤器链之后,我们就可以轻松得知之前定义的指标H1、H2、C1、C2,之后Presto可以通过比较它们之间的大小关系来判断集群的缓存状态,如下图所示: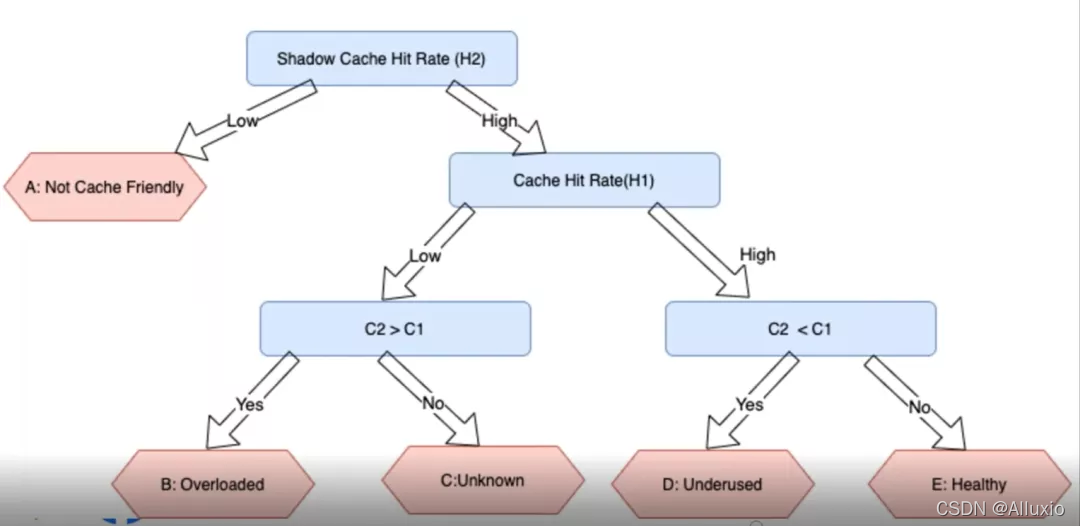
当H2比较低时,表明就算拥有无限的缓存空间,也不能使得缓存命中率达到理想的数值,因此说明该集群中运行的应用是缓存不友好的。当H2高H1低且C2>C1时,说明集群的缓存空间分配不足,如果扩大缓存容量,命中率能够进一步提高;而当H2高H1高且C2>C1时,证明集群状态良好,无需对缓存进行缩放。
具体实现
Shadow cache的布隆过滤器实现是基于Guava库的,并且支持根据用户自定义的空间开销,窗口大小等参数选择过滤器的具体配置。目前Shadow cache支持统计的工作集单位包括pages和bytes,分别代表工作集包含多少页以及工作集包含多少具体bytes。而对于命中率的计算,Shadow cache 可以以byte为单位记为一次命中,同样的也可以用一个对象为单位来记为一次命中。
配置项如下图示:

评估测试
我们对Shadow cache进行了实验评估,发现仅需125MB的空间,Shadow cache就能追踪27TB的工作集,并且错误率仅有3%。并且错误率还可以通过HyperLogLog算法进一步减少,但如果使用HyperLogLog就将不支持极限命中率的估计。
04 Presto 路由优化
在利用Shadow cache得知集群的具体状态后,如果集群状态不良,Presto需要一些手段来及时的调整集群,以此提高集群的响应速度。我们接下来先介绍目前presto的路由算法,然后给出几种在加入Shadow cache之后可选的路由优化方案。
Presto路由
Presto将不同的表存储在不同的集群中,以表名在各个集群之间分享缓存。因此,当一个对于某表请求到来时,该请求总会被发往相同的集群。如果不这样做的话集群的缓存就容易被各种杂乱不一的表充满,不能发挥缓存的效果。下面我们通过一张图来说明路由逻辑:
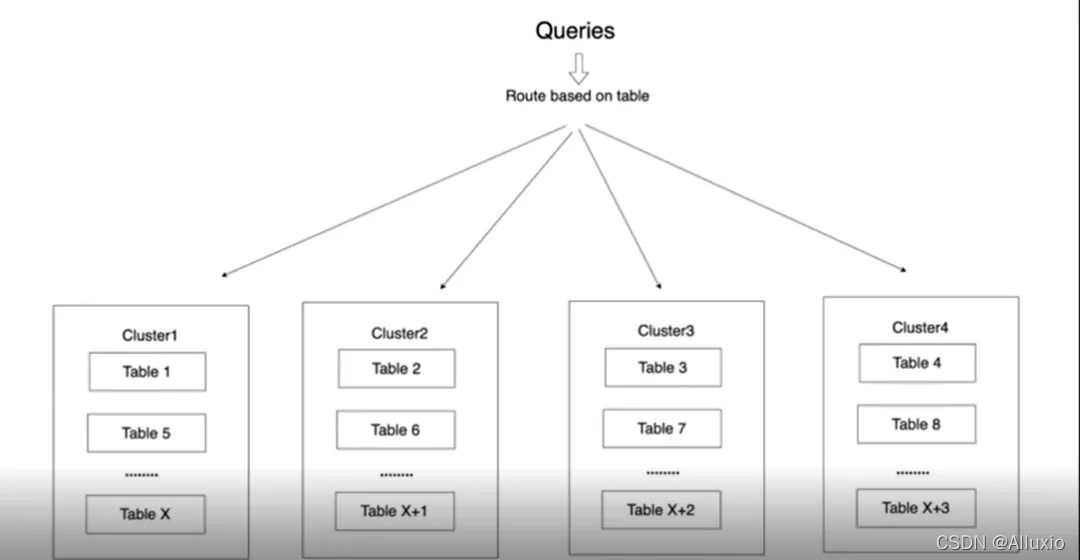
如上图所示,table 1到table4有着不同的表名,因此被分配到不同的集群中 。当请求table1中的数据时,路由逻辑将会把此请求发往cluster1,而请求table3中的数据时,路由逻辑将把请求发往cluster3。
路由优化方案
判断一个集群是否正常的一个简单方案就是看一个指向某个集群的请求的响应时间,若该集群迟迟没有回应或回应的时间过长,我们就认为该集群出现了问题。在有了Shadow cache之后,就像上文所提到的,结合H1、H2、C1、C2,我们可以快速判断一个集群是否是因为缓存有压力而出现的性能下降。
对于这样一个表现不佳的集群,Presto提出以下三种路由优化方案:
方案一:当主要集群正忙时,我们有一个指定的也拥有该缓存的第二集群会被启用来为请求进行服务。但这种方法会在每个集群中占用额外的缓存空间。
方案二:两个集群都被视为主集群对请求进行服务,并且在这两个集群中进行负载均衡,然而这种方案将会使得缓存磁盘空间占用倍增。
方案三:基于请求的模式来交换各集群中的表,进而让CPU占用的分布更加均匀。同样的,这种方案也有问题:会使得缓存分布不均匀从而需要额外的缓存空间。
05 总结
对用户缓存中的工作集大小进行追踪估算是一项重要而又富有挑战性的工作,为此我们基于布隆过滤器设计了一个轻量化的Alluxio组件Shadow cache。由于我们只关心用户工作集大小的最新情况,因此需要使用时间窗口模型来淘汰过时项,为此Shaodow cache将时间窗口拆分为4段,每段用不同的布隆过滤器进行跟踪,每次淘汰时只需删除最早创建的布隆过滤器,再创建一个新的布隆过滤器追踪最新数据。最后,需要提供工作集大小时,我们用到了Swamidass & Baldi (2007) 提出的基数估计公式。
总体来看,Shadow cache为Presto提供了四种方便的指标:H1、H2、C1、C2,其中H1、C1分别代表真实缓存命中率和容量,而H2、C2则代表着缓存的极限命中率以及一段时间内用户的工作集大小。基于以上的四种指标,Presto能够轻松的判断缓存容量与应用性能之间的关系 ,并进一步探索路由算法的优化策略。
想要获取更多有趣有料的【活动信息】【技术文章】【大咖观点】,请关注[Alluxio智库]:


