n> 原文来源:https://tidb.net/blog/eb060e49nn本文介绍了基于数据库时间的系统优化方法,以及如何利用 TiDB Performance Overview 面板进行性能分析和优化。
通过本文中介绍的方法,你可以从全局、自顶向下的角度分析用户响应时间和数据库时间,确认用户响应时间的瓶颈是否在数据库中。如果瓶颈在数据库中,你可以通过数据库时间概览和 SQL 延迟的分解,定位数据库内部的瓶颈点,并进行针对性的优化。
基于数据库时间的性能优化方法
TiDB 对 SQL 的处理路径和数据库时间进行了完善的测量和记录,方便定位数据库的性能瓶颈。即使在用户响应时间的性能数据缺失的情况下,基于 TiDB 数据库时间的相关性能指标,你也可以达到以下两个性能分析目标:
- 通过对比 SQL 处理平均延迟和事务中 TiDB 连接的空闲时间,确定整个系统的瓶颈是否在 TiDB 中。
- 如果瓶颈在 TiDB 内部,根据数据库时间概览、颜色优化法、关键指标和资源利用率、自上而下的延迟分解,定位到性能瓶颈具体在整个分布式系统的哪个模块。
确定整个系统的瓶颈是否在 TiDB 中
-
如果事务中 TiDB 连接的平均空闲时间比 SQL 平均处理延迟高,说明应用的事务处理中,主要的延迟不在数据库中,数据库时间占用户响应时间比例小,可以确认瓶颈不在数据库中。
-
在这种情况下,需要关注数据库外部的组件,比如应用服务器硬件资源是否存在瓶颈,应用到数据库的网络延迟是否过高等。
-
如果 SQL 平均处理延迟比事务中 TiDB 连接的平均空闲时间高,说明事务中主要的瓶颈在 TiDB 内部,数据库时间占用户响应时间比例大。
如果瓶颈在 TiDB 内部,如何定位
一个典型的 SQL 的处理流程如下所示,TiDB 的性能指标覆盖了绝大部分的处理路径,对数据库时间进行不同维度的分解和上色,用户可以快速的了解负载特性和数据库内部的瓶颈。
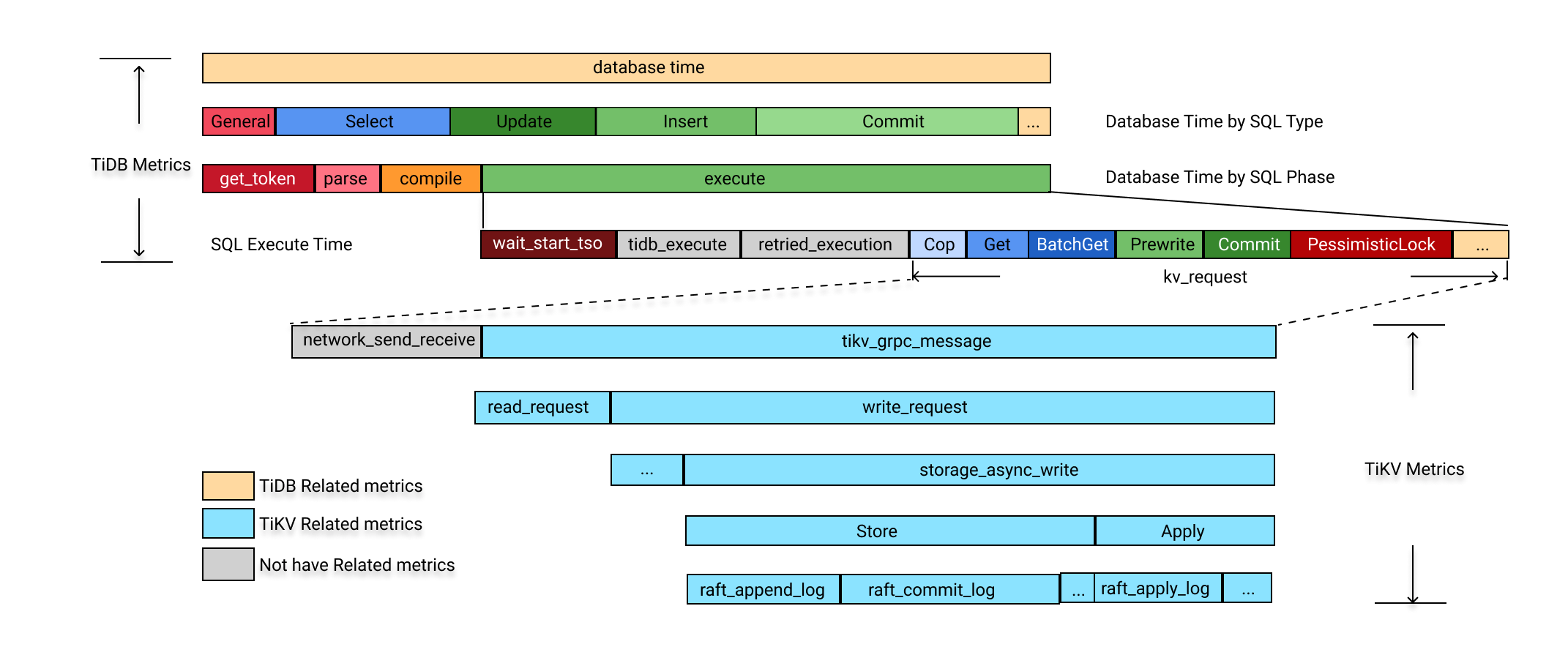
数据库时间是所有 SQL 处理时间的总和。通过以下三个维度对数据库时间进行分解,可以帮助你快速定位 TiDB 内部瓶颈:
-
按 SQL 处理类型分解,判断哪种类型的 SQL 语句消耗数据库时间最多。对应的分解公式为:
-
DB Time = Select Time + Insert Time + Update Time + Delete Time + Commit Time + ... -
按 SQL 处理的 4 个步骤(即 get_token/parse/compile/execute)分解,判断哪个步骤消耗的时间最多。对应的分解公式为:
-
DB Time = Get Token Time + Parse Time + Comiple Time + Execute Time -
对于 execute 耗时,按照 TiDB 执行器本身的时间、TSO 等待时间、KV 请求时间和重试的执行时间,判断执行阶段的瓶颈。对应的分解公式为:
-
Execute Time ~= TiDB Executor Time + KV Request Time + PD TSO Wait Time + Retried execution time
利用 Performance Overview 面板进行性能分析和优化
本章介绍如何利用 Grafana 中的 Performance Overview 面板进行基于数据库时间的性能分析和优化。
Performance Overview 面板按总分结构对 TiDB、TiKV、PD 的性能指标进行编排组织,包括以下三个部分:
- 数据库时间和 SQL 执行时间概览:通过颜色标记不同 SQL 类型,SQL 不同执行阶段、不同请求的数据库时间,帮助你快速识别数据库负载特征和性能瓶颈。
- 关键指标和资源利用率:包含数据库 QPS、应用和数据库的连接信息和请求命令类型、数据库内部 TSO 和 KV 请求 OPS、TiDB 和 TiKV 的资源使用概况。
- 自上而下的延迟分解:包括 Query 延迟和连接空闲时间对比、Query 延迟分解、execute 阶段 TSO 请求和 KV 请求的延迟、TiKV 内部写延迟的分解等。
数据库时间和 SQL 执行时间概览
Database Time 指标为 TiDB 每秒处理 SQL 的延迟总和,即 TiDB 集群每秒并发处理应用 SQL 请求的总时间(等于活跃连接数)。
Performance Overview 面板提供了以下三个面积堆叠图,帮助你了解数据库负载的类型,快速定位数据库时间的瓶颈主要是处理什么语句,集中在哪个执行阶段,SQL 执行阶段主要等待 TiKV 或者 PD 哪种请求类型。
- Database Time By SQL Type
- Database Time By SQL Phase
- SQL Execute Time Overview
颜色优化法
通过观察数据库时间分解图和执行时间概览图,你可以直观地区分正常或者异常的时间消耗,快速定位集群的异常瓶颈点,高效了解集群的负载特征。对于正常的时间消耗和请求类型,图中显示颜色为绿色系或蓝色系。如果非绿色或蓝色系的颜色在这两张图中占据了明显的比例,意味着数据库时间的分布不合理。
- Database Time By SQL Type:蓝色标识代表 Select 语句,绿色标识代表 Update、Insert、Commit 等 DML 语句。红色标识代表 General 类型,包含 StmtPrepare、StmtReset、StmtFetch、StmtClose 等命令。
- Database Time By SQL Phase:execute 执行阶段为绿色,其他三个阶段偏红色系,如果非绿色的颜色占比明显,意味着在执行阶段之外数据库消耗了过多时间,需要进一步分析根源。一个常见的场景是因为无法使用执行计划缓存,导致 compile 阶段的橙色占比明显。
- SQL Execute Time Overview:绿色系标识代表常规的写 KV 请求(例如 Prewrite 和 Commit),蓝色系标识代表常规的读 KV 请求(例如 Cop 和 Get),其他色系标识需要注意的问题。例如,悲观锁加锁请求为红色,TSO 等待为深褐色。如果非蓝色系或者非绿色系占比明显,意味着执行阶段存在异常的瓶颈。例如,当发生严重锁冲突时,红色的悲观锁时间会占比明显;当负载中 TSO 等待的消耗时间过长时,深褐色会占比明显。
示例 1:TPC-C 负载

- Database Time by SQL Type:主要消耗时间的语句为 commit、update、select 和 insert 语句。
- Database Time by SQL Phase:主要消耗时间的阶段为绿色的 execute 阶段。
- SQL Execute Time Overview:执行阶段主要消耗时间的 KV 请求为绿色的 Prewrite 和 Commit。
注意
-
KV 请求的总时间大于 execute time 为正常现象,因为 TiDB 执行器可能并发向多个 TiKV 发送 KV 请求,导致总的 KV 请求等待时间大于 execute time。TPC-C 负载中,事务提交时,TiDB 会向多个 TiKV 并行发送 Prewrite 和 Commit 请求,所以这个例子中 Prewrite、Commit 和 PessimisticsLock 请求的总时间明显大于 execute time。
-
execute time 也可能明显大于 KV 请求的总时间加上 tso_wait 的时间,这意味着 SQL 执行阶段主要时间花在 TiDB 执行器内部。两种常见的例子:
- 例 1:TiDB 执行器从 TiKV 读取大量数据之后,需要在 TiDB 内部进行复杂的关联和聚合,消耗大量时间。
- 例 2:应用的写语句锁冲突严重,频繁锁重试导致
Retried execution time过长。
示例 2:OLTP 读密集负载

- Database Time by SQL Type:主要消耗时间的语句为 select、commit、update和 insert 语句。其中,select 占据绝大部分的数据库时间。
- Database Time by SQL Phase:主要消耗时间的阶段为绿色的 execute 阶段。
- SQL Execute Time Overview:执行阶段主要消耗时间为深褐色的 pd tso_wait、蓝色的 KV Get 和绿色的 Prewrite 和 Commit。
示例 3:只读 OLTP 负载

- Database Time by SQL Type:几乎所有语句为 select。
- Database Time by SQL Phase:主要消耗时间的阶段为橙色的 compile 和绿色的 execute 阶段。compile 阶段延迟最高,代表着 TiDB 生成执行计划的过程耗时过长,需要根据后续的性能数据进一步确定根源。
- SQL Execute Time Overview:执行阶段主要消耗时间的 KV 请求为蓝色 BatchGet。
注意
示例 3 select 语句需要从多个 TiKV 并行读取几千行数据,BatchGet 请求的总时间远大于执行时间。
示例 4: 锁争用负载

- Database Time by SQL Type:主要为 Update 语句。
- Database Time by SQL Phase:主要消耗时间的阶段为绿色的 execute 阶段。
- SQL Execute Time Overview:执行阶段主要消耗时间的 KV 请求为红色的悲观锁 PessimisticLock,execute time 明显大于 KV 请求的总时间,这是因为应用的写语句锁冲突严重,频繁锁重试导致
Retried execution time过长。目前Retried execution time消耗的时间,TiDB 尚未进行测量。
TiDB 关键指标和集群资源利用率
Query Per Second、Command Per Second 和 Prepared-Plan-Cache
通过观察 Performance Overview 里的以下三个面板,可以了解应用的负载类型,与 TiDB 的交互方式,以及是否能有效地利用 TiDB 的执行计划缓存。
-
QPS:表示 Query Per Second,包含应用的 SQL 语句类型执行次数分布。
-
CPS By Type:CPS 表示 Command Per Second,Command 代表 MySQL 协议的命令类型。同样一个查询语句可以通过 query 或者 prepared statement 的命令类型发送到 TiDB。
-
Queries Using Plan Cache OPS:TiDB 集群每秒命中执行计划缓存的次数。执行计划缓存只支持 prepared statement 命令。TiDB 开启执行计划缓存的情况下,存在三种使用情况:
- 完全无法命中执行计划缓存:每秒命中次数为 0,因为应用使用 query 命令,或者每次 StmtExecute 执行之后调用 StmtClose 命令,导致缓存的执行计划被清理。
- 完全命中执行计划缓存:每秒命中次数等于 StmtExecute 命令每秒执行次数。
- 部分命中执行计划缓存:每秒命中次数小于 StmtExecute 命令每秒执行次数,执行计划缓存目前存在一些限制,比如不支持子查询,该类型的 SQL 执行计划无法被缓存。
示例 1:TPC-C 负载
TPC-C 负载类型主要以 Update、Select 和 Insert 语句为主。总的 QPS 等于每秒 StmtExecute 的次数,并且 StmtExecute 每秒的数据基本等于 Queries Using Plan Cache OPS。这是 OLTP 负载理想的情况,客户端执行使用 prepared statement,并且在客户端缓存了 prepared statement 对象,执行每条 SQL 语句时直接调用 statement 执行。执行时都命中执行计划缓存,不需要重新 compile 生成执行计划。

示例 2:只读 OLTP 负载,使用 query 命令无法使用执行计划缓存
这个负载中, Commit QPS = Rollback QPS = Select QPS。应用开启了 auto-commit 并发,每次从连接池获取连接都会执行 rollback,因此这三种语句的执行次数是相同的。

- QPS 面板中出现的红色加粗线为 Failed Query,坐标的值为右边的 Y 轴。非 0 代表此负载中存在错误语句。
- 总的 QPS 等于 CPS By Type 面板中的 Query,说明应用中使用了 query 命令。
- Queries Using Plan Cache OPS 面板没有数据,因为不使用 prepared statement 接口,无法使用 TiDB 的执行计划缓存, 意味着应用的每一条 query,TiDB 都需要重新解析,重新生成执行计划。通常会导致 compile 时间变长以及 TiDB CPU 消耗的增加。
示例 3:OLTP 负载,使用 prepared statement 接口无法使用执行计划缓存
StmtPreare 次数 = StmtExecute 次数 = StmtClose 次数 ~= StmtFetch 次数,应用使用了 prepare > execute > fetch > close 的 loop,很多框架都会在 execute 之后调用 close,确保资源不会泄露。这会带来两个问题:
- 执行每条 SQL 语句需要 4 个命令,以及 4 次网络往返。
- Queries Using Plan Cache OPS 为 0, 无法命中执行计划缓存。StmtClose 命令默认会清理缓存的执行计划,导致下一次 StmtPreare 命令需要重新生成执行计划。
注意
从 TiDB v6.0.0 起,你可以通过全局变量 (set global tidb_ignore_prepared_cache_close_stmt=on;) 控制 StmtClose 命令不清理已被缓存的执行计划,使得下一次的 SQL 的执行不需要重新生成执行计划。

KV/TSO Request OPS 和连接信息
在 KV/TSO Request OPS 面板中,你可以查看 KV 和 TSO 每秒请求的数据统计。其中,kv request total 代表 TiDB 到 TiKV 所有请求的总和。通过观察 TiDB 到 PD 和 TiKV 的请求类型,可以了解集群内部的负载特征。
在 Connection Count (连接信息)面板中,你可以查看总的连接数和每个 TiDB 的连接数,并由此判断连接总数是否正常,每个 TiDB 的连接数是否不均衡。active connections 记录着活跃连接数,等于每秒的数据库时间。
示例 1:繁忙的负载

在此 TPC-C 负载中:
- 每秒总的 KV 请求的数量为 104.2k。按请求数量排序,最高的请求类型为
PessimisticsLock、Prewrite、Commit和BatchGet等。 - 总的连接数为 810,三个 TiDB 实例的连接数大体均衡。活跃的连接数为 787.1。对比活跃连接数和总连接数,97% 的连接都是活跃的,通常意味着数据库是这个应用系统的性能瓶颈。
示例 2:空闲的负载

在此负载中:
- 每秒总的 KV 请求数据是 2.6 K,TSO 请求次数是每秒 1.1 K。
- 总的连接数为 410,连接数在三个 TiDB 中相对均衡。活跃连接数只有 2.5,说明数据库系统非常空闲。
TiDB CPU,以及 TiKV CPU 和 IO 使用情况
在 TiDB CPU 和 TiKV CPU/IO MBps 这两个面板中,你可以观察到 TiDB 和 TiKV 的逻辑 CPU 使用率和 IO 吞吐,包含平均、最大和 delta(最大 CPU 使用率减去最小 CPU 使用率),从而用来判定 TiDB 和 TiKV 总体的 CPU 使用率。
- 通过
delta值,你可以判断 TiDB 是否存在 CPU 使用负载不均衡(通常伴随着应用连接不均衡),TiKV 是否存在热点。 - 通过 TiDB 和 TiKV 的资源使用概览,你可以快速判断集群是否存在资源瓶颈,最需要扩容的组件是 TiDB 还是 TiKV。
示例 1:TiDB 资源使用率高
下图负载中,每个 TiDB 和 TiKV 配置 8 CPU。

- TiDB 平均 CPU 为 575%。最大 CPU 为 643%,delta CPU 为 136%。
- TiKV 平均 CPU 为 146%,最大 CPU 215%。delta CPU 为 118%。TiKV 的平均 IO 吞吐为 9.06 MB/s,最大 IO 吞吐为 19.7 MB/s,delta IO 吞吐 为 17.1 MB/s。
由此可以判断,TiDB 的 CPU 消耗明显更高,并接近于 8 CPU 的瓶颈,可以考虑扩容 TiDB。
示例 2:TiKV 资源使用率高
下图 TPC-C 负载中,每个 TiDB 和 TiKV 配置 16 CPU。

- TiDB 平均 CPU 为 883%。最大 CPU 为 962%,delta CPU 为 153%。
- TiKV 平均 CPU 为 1288%,最大 CPU 1360%。delta CPU 为 126%。TiKV 的平均 IO 吞吐为130 MB/s,最大 IO 吞吐为 153 MB/s,delta IO 吞吐为 53.7 MB/s。
由此可以判断,TiKV 的 CPU 消耗更高,因为 TPC-C 是一个写密集场景,这是正常现象,可以考虑扩容 TiKV 节点提升性能。
Query 延迟分解和关键的延迟指标
延迟面板通常包含平均值和 99 分位数,平均值用来定位总体的瓶颈,99 分位数用来判断是否存在延迟严重抖动的情况。判断性能抖动范围时,可能还需要需要借助 999 分位数。
Duration 和 Connection Idle Duration
Duration 面板包含了所有语句的 99 延迟和每种 SQL 类型的平均延迟。Connection Idle Duration 面板包含连接空闲的平均和 99 延迟,连接空闲时包含两种状态:
- in-txn:代表事务中连接的空闲时间,即当连接处于事务中时,处理完上一条 SQL 之后,收到下一条 SQL 语句的间隔时间。
- not-in-txn:当连接没有处于事务中,处理完上一条 SQL 之后,收到下一条 SQL 语句的间隔时间。
应用进行数据库事务时,通常使用同一个数据库连接。对比 query 的平均延迟和 connection idle duration 的延迟,可以判断整个系统性能瓶颈或者用户响应时间的抖动是否是由 TiDB 导致的。
- 如果应用负载不是只读的,包含事务,对比 query 平均延迟和
avg-in-txn可以判断应用处理事务时,主要的时间是花在数据库内部还是在数据库外面,借此定位用户响应时间的瓶颈。 - 如果是只读负载,不存在
avg-in-txn指标,可以对比 query 平均延迟和avg-not-in-txn指标。
现实的客户负载中,瓶颈在数据库外面的情况并不少见,例如:
- 客户端服务器配置过低,CPU 资源不够。
- 使用 HAProxy 作为 TiDB 集群代理,但是 HAProxy CPU 资源不够。
- 使用 HAProxy 作为 TiDB 集群代理,但是高负载下 HAProxy 服务器的网络带宽被打满。
- 应用服务器到数据库延迟过高,比如公有云环境应用和 TiDB 集群不在同一个地区,比如数据库的 DNS 均衡器和 TiDB 集群不在同一个地区。
- 客户端程序存在瓶颈,无法充分利用服务器的多 CPU 核或者多 Numa 资源,比如应用只使用一个 JVM 向 TiDB 建立上千个 JDBC 连接。
示例 1:用户响应时间的瓶颈在 TiDB 中

在此 TPC-C 负载中:
- 所有 SQL 语句的平均延迟 477 us,99 延迟 3.13ms。平均 commit 语句 2.02ms,平均 insert 语句 609ms,平均查询语句 468us。
- 事务中连接空闲时间
avg-in-txn171 us。
由此可以判断,平均的 query 延迟明显大于 avg-in-txn,说明事务处理中,主要的瓶颈在数据库内部。
示例 2:用户响应时间的瓶颈不在 TiDB 中

在此负载中,平均 query 延迟为 1.69ms,事务中连接空闲时间 avg-in-txn 为 18ms。说明事务中,TiDB 平均花了 1.69ms 处理完一个 SQL 语句之后,需要等待 18ms 才能收到下一条语句。
由此可以判断,用户响应时间的瓶颈不在 TiDB 中。这个例子是在一个公有云环境下,因为应用和数据库不在同一个地区,应用和数据库之间的网络延迟高导致了超高的连接空闲时间。
Parse、Compile 和 Execute Duration
在 TiDB 中,从输入查询文本到返回结果的典型处理流程。
SQL 在 TiDB 内部的处理分为四个阶段,get token、parse、compile 和 execute:
- get token 阶段:通常只有几微秒的时间,可以忽略。除非 TiDB 单个实例的连接数达到的 token-limit 的限制,创建连接的时候被限流。
- parse 阶段:query 语句解析为抽象语法树 abstract syntax tree (AST)。
- compile 阶段:根据 parse 阶段输出的 AST 和统计信息,编译出执行计划。整个过程主要步骤为逻辑优化与物理优化,前者通过一些规则对查询计划进行优化,例如基于关系代数的列裁剪等,后者通过统计信息和基于成本的优化器,对执行计划的成本进行估算,并选择整体成本最小的物理执行计划。
- execute 阶段:时间消耗视情况,先等待全局唯一的时间戳 TSO,之后执行器根据执行计划中算子涉及的 Key 范围,构建出 TiKV 的 API 请求,分发到 TiKV。execute 时间包含 TSO 等待时间、KV 请求的时间和 TiDB 执行器本身处理数据的时间。
如果应用统一使用 query 或者 StmtExecute MySQL 命令接口,可以使用以下公式来定位平均延迟的瓶颈。
avg Query Duration = avg Get Token + avg Parse Duration + avg Compile Duration + avg Execute Duration
通常 execute 阶段会占 query 延迟的主要部分,在以下情况下,parse 和 compile 阶段也会占比明显。
- parse 阶段延迟占比明显:比如 query 语句很长,文本解析消耗大量的 CPU。
- compile 阶段延迟占比明显:如果应用没有使用执行计划缓存,每个语句都需要生成执行计划。compile 阶段的延迟可能达到几毫秒或者几十毫秒。如果无法命中执行计划缓存,compile 阶段需要进行逻辑优化和物理优化,这将消耗大量的 CPU 和内存,并给 Go Runtime 带来压力(因为 TiDB 是
Go编写的),进一步影响 TiDB 其他组件的性能。这说明,OLTP 负载在 TiDB 中是否能高效运行,执行计划缓扮演了重要的角色。
示例 1:数据库瓶颈在 compile 阶段

此图中 parse、compile 和 execute 阶段的平均时间分别为 17.1 us、729 us 和 681 us。因为应用使用 query 命令接口,无法使用执行计划缓存,所以 compile 阶段延迟高。
示例 2:数据库瓶颈在 execute 阶段

在此 TPC-C 负载中,parse、compile 和 execute 阶段的平均时间分别为 7.39us、38.1us 和 12.8ms。query 延迟的瓶颈在于 execute 阶段。
KV 和 TSO Request Duration
在 execute 阶段,TiDB 会跟 PD 和 TiKV 进行交互。如下图所示,当 TiDB 处理 SQL 语句请求时,在进行 parse 和 compile 之前,如果需要获取 TSO,会先请求生成 TSO。PD Client 不会阻塞调用者,而是直接返回一个 TSFuture,并在后台异步处理 TSO 请求的收发,一旦完成立即返回给 TSFuture,TSFuture 的持有者则需要调用 Wait 方法来获得最终的 TSO 结果。当 TiDB 完成 parse 和 compile 之后, 进入 execute 阶段,此时存在两个情况:
- 如果 TSO 请求已经完成,Wait 方法会立刻返回一个可用的 TSO 或 error
- 如果 TSO 请求还未完成,Wait 方法会 block 住等待一个可用的 TSO 或 error(说明 gRPC 请求已发送但尚未收到返回结果,网络延迟较高)
TSO 等待的时间记录为 TSO WAIT,TSO 请求的网络时间记录为 TSO RPC。TiDB TSO 等待完成之后,执行过程中通常需要和 TiKV 进行读写交互:
- 读的 KV 请求常见类型:Get、BatchGet 和 Cop
- 写的 KV 请求常见类型:PessimisticLock,二阶段提交的 Prewrite 和 Commit
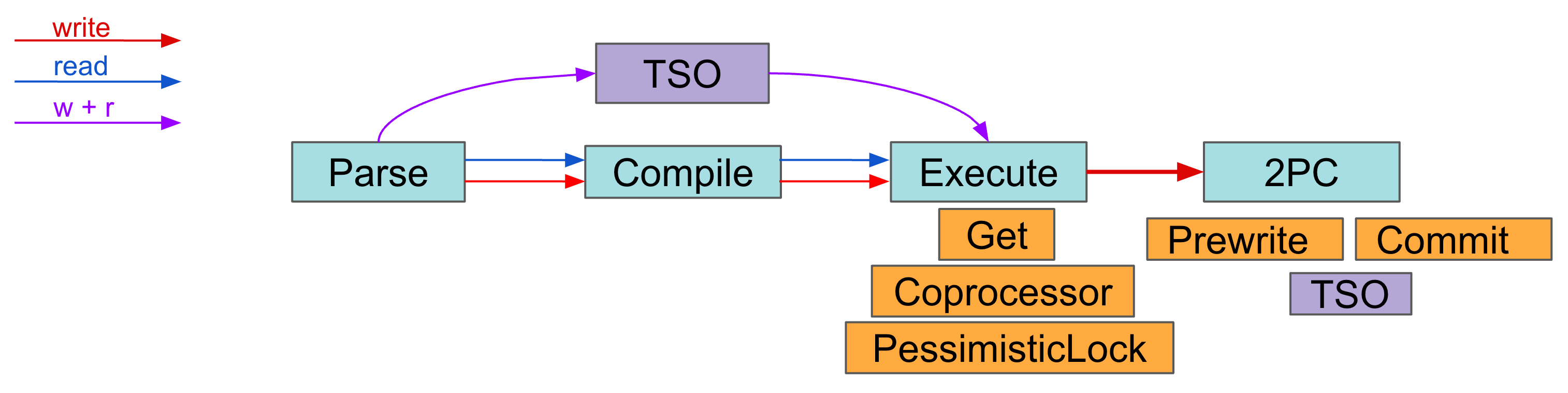
这一部分的指标对应以下三个面板:
- Avg TiDB KV Request Duration:TiDB 测量的 KV 请求的平均延迟
- Avg TiKV GRPC Duration:TiKV 内部 GRPC 消息处理的平均延迟
- PD TSO Wait/RPC Duration:TiDB 执行器等待 TSO 延迟 (wait) 和 TSO 请求的网络延迟(rpc)。
其中,Avg TiDB KV Request Duration 和 Avg TiKV GRPC Duration 的关系如下
Avg TiDB KV Request Duration = Avg TiKV GRPC Duration + TiDB 与 TiKV 之间的网络延迟 + TiKV GRPC 处理时间 + TiDB GRPC 处理时间和调度延迟。
Avg TiDB KV Request Duration 和 Avg TiKV GRPC Duration 的差值跟网络流量和延迟,TiDB 和 TiKV 的资源使用情况密切相关。
- 同一个机房内,Avg TiDB KV Request Duration 和 Avg TiKV GRPC Duration 的差值通常应该小于 2 毫秒。
- 同一地区的不同可用区,Avg TiDB KV Request Duration 和 Avg TiKV GRPC Duration 的差值通常应该小于 5 毫秒。
示例 1:同机器低负载的集群

在此负载中,TiDB 侧平均 Prewrite 请求延迟为 925 us,TiKV 内部 kv_prewrite 平均处理延迟为 720 us,相差 200 us 左右,是同机房内正常的延迟。TSO wait 平均延迟 206 us,rpc 时间为 144 us。
示例 2:公有云集群,负载正常

在此示例中,TiDB 集群部署在同一个地区的不同机房。TiDB 侧平均 Commit 请求延迟为 12.7 ms,TiKV 内部 kv_commit 平均处理延迟为 10.2ms,相差 2.5ms 左右。TSO wait 平均延迟为 3.12ms,rpc 时间为 693us。
示例 3:公有云集群,资源严重过载

在此示例中,TiDB 集群部署在同一个地区的不同机房,TiDB 网络和 CPU 资源严重过载。TiDB 侧平均 BatchGet 请求延迟为 38.6 ms,TiKV 内部 kv_batch_get 平均处理延迟为 6.15 ms,相差超过 32 ms,远高于正常值。TSO wait 平均延迟为 9.45ms,rpc 时间为 14.3ms。
Storage Async Write Duration、Store Duration 和 Apply Duration
TiKV 对于写请求的处理流程如下图
-
scheduler worker会先处理写请求,进行事务一致性检查,并把写请求转化成键值对,发送到raftstore模块。 -
raftstore为 TiKV 的共识模块,使用 Raft 共识算法,使多个 TiKV 组成的存储层可以容错。Raftstore 分为 store 线程和 apply 线程。:
- store 线程负载处理 Raft 消息和新的
proposals。 当收到新的proposals时,leader 节点的 store 线程会写入本地 Raft DB,并将消息复制到多个 follower 节点。当这个proposals在多数实例持久化成功之后,proposals成功被提交。 - apply 线程会负载将提交的内容写入到 KV DB 中。当写操作的内容被成功的写入 KV 数据库中,apply 线程会通知外层请求写请求已经完成。
- store 线程负载处理 Raft 消息和新的
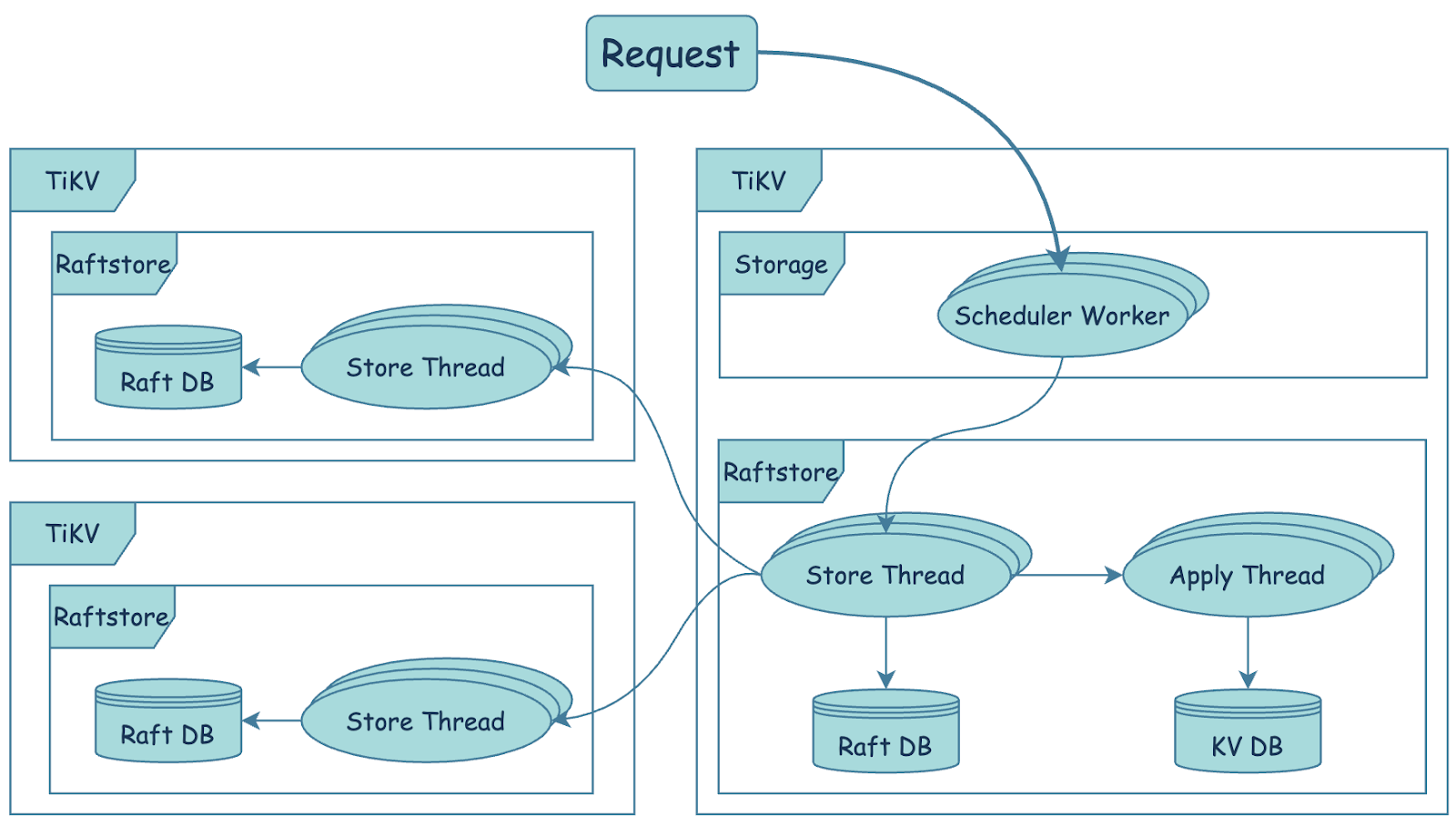
Storage Async Write Duration 指标记录写请求进入 raftstore 之后的延迟,采集的粒度具体到每个请求的级别。
Storage Async Write Duration 分为 Store Duration 和 Apply Duration。你可以通过以下公式定位写请求的瓶颈主要是 在 Store 还是 Apply 步骤。
avg Storage Async Write Duration = avg Store Duration + avg Apply Duration
注意
Store Duration 和 Apply Duration 从 v5.3.0 版本开始支持。
示例 1:同一个 OLTP 负载在 v5.3.0 和 v5.4.0 版本的对比
v5.4.0 版本,一个写密集的 OLTP 负载 QPS 比 v5.3.0 提升了 14%。应用以上公式
- v5.3.0:24.4 ms ~= 17.7 ms + 6.59 ms
- v5.4.0:21.4 ms ~= 14.0 ms + 7.33 ms
因为 v5.4.0 版本中,TiKV 对 gRPC 模块进行了优化,优化了 Raft 日志复制速度, 相比 v5.3.0 降低了 Store Duration。
v5.3.0:

v5.4.0:

示例 2:Store Duration 瓶颈明显
应用以上公式:10.1 ms ~= 9.81 ms + 0.304 ms,说明写请求的延迟瓶颈在 Store Duration。

Commit Log Duration、Append Log Duration 和 Apply Log Duration
Commit Log Duration、Append Log Duration 和 Apply Log Duration 这三个延迟是 raftstore 内部关键操作的延迟记录。这些记录采集的粒度是 batch 操作级别的,每个操作会把多个写请求合并在一起,因此不能直接对应上文的 Store Duration 和 Apply Duration。
- Commit Log Duration 和 Append Log Duration 均为 store 线程的操作。Commit Log Duration 包含复制 Raft 日志到其他 TiKV 节点,保证 raft-log 的持久化。一般包含两次 Append Log Duration,一次 leader,一次 follower 的。Commit Log Duration 延迟通常会明显高于 Append Log Duration,因为包含了通过网络复制 Raft 日志到其他 TiKV 的时间。
- Apply Log Duration 记录了 apply 线程 apply Raft 日志的延迟。
Commit Log Duration 慢的常见场景:
- TiKV CPU 资源存在瓶颈,调度延迟高
raftstore.store-pool-size设置过小或者过大(过大也可能导致性能下降)- IO 延迟高,导致 Append Log Duration 延迟高
- TiKV 之间的网络延迟比较高
- TiKV 的 gRPC 线程数设置过小或者多个 gRPC CPU 资源使用不均衡
Apply Log Duration 慢的常见场景:
- TiKV CPU 资源存在瓶颈,调度延迟高
raftstore.apply-pool-size设置过小或者过大(过大也可能导致性能下降)- IO 延迟比较高
示例 1:同一个 OLTP 负载在 v5.3.0 和 v5.4.0 版本的对比
v5.4.0 版本,一个写密集的 OLTP 负载 QPS 比 v5.3.0 提升了 14%。 对比这三个关键延迟:
| Avg Duration | v5.3.0(ms) | v5.4.0(ms) |
|---|---|---|
| Append Log Duration | 0.27 | 0.303 |
| Commit Log Duration | 13 | 8.68 |
| Apply Log Duration | 0.457 | 0.514 |
因为 v5.4.0 版本中,TiKV 对 gRPC 模块进行了优化,优化了 Raft 日志复制速度, 相比 v5.3.0 降低了 Commit Log Duration 和 Store Duration。
v5.3.0:

v5.4.0:

示例 2:Commit Log Duration 瓶颈明显的例子

- 平均 Append Log Duration = 4.38 ms
- 平均 Commit Log Duration = 7.92 ms
- 平均 Apply Log Duration = 172 us
Store 线程的 Commit Log Duration 明显比 Apply Log Duration 高,并且 Append Log Duration 比 Apply Log Duration 明显的高,说明 Store 线程在 CPU 和 IO 都可能都存在瓶颈。可能降低 Commit Log Duration 和 Append Log Duration 的方式如下:
- 如果 TiKV CPU 资源充足,考虑增加 Store 线程,即
raftstore.store-pool-size。 - 如果 TiDB 为 v5.4.0 及之后的版本,考虑启用
Raft Engine,Raft Engine 具有更轻量的执行路径,在一些场景下显著减少 IO 写入量和写入请求的长尾延迟,启用方式为设置:raft-engine.enable: true - 如果 TiKV CPU 资源充足,且 TiDB 为 v5.3.0 及之后的版本,考虑启用
StoreWriter。启用方式:raftstore.store-io-pool-size: 1。
低于 v6.1.0 的 TiDB 版本如何使用 Performance overview 面板
从 v6.1.0 起,TiDB Grafana 组件默认内置了 Performance Overview 面板。Performance overview 面板兼容 TiDB v4.x 和 v5.x 版本。如果你的 TiDB 版本低于 v6.1.0,需要手动导入 performance_overview.json。
导入方法如图所示: