@
大型语言模型 (LLM) 是无状态的,这意味着它们不会保留先前交互的信息。
@Test
public void testChatOptions() {
String content = chatClient.prompt()
.user("我叫小兔子 ")
.call()
.content();
System.out.println(content);
System.out.println("--------------------------------------------------------------------------");
content = chatClient.prompt()
.user("我叫什么 ?")
.call()
.content();
System.out.println(content);
}

那我们平常跟一些大模型聊天是怎么记住我们对话的呢?实际上,每次对话都需要将之前的对话消息内置发送给大模型,这种方式称为多轮对话。
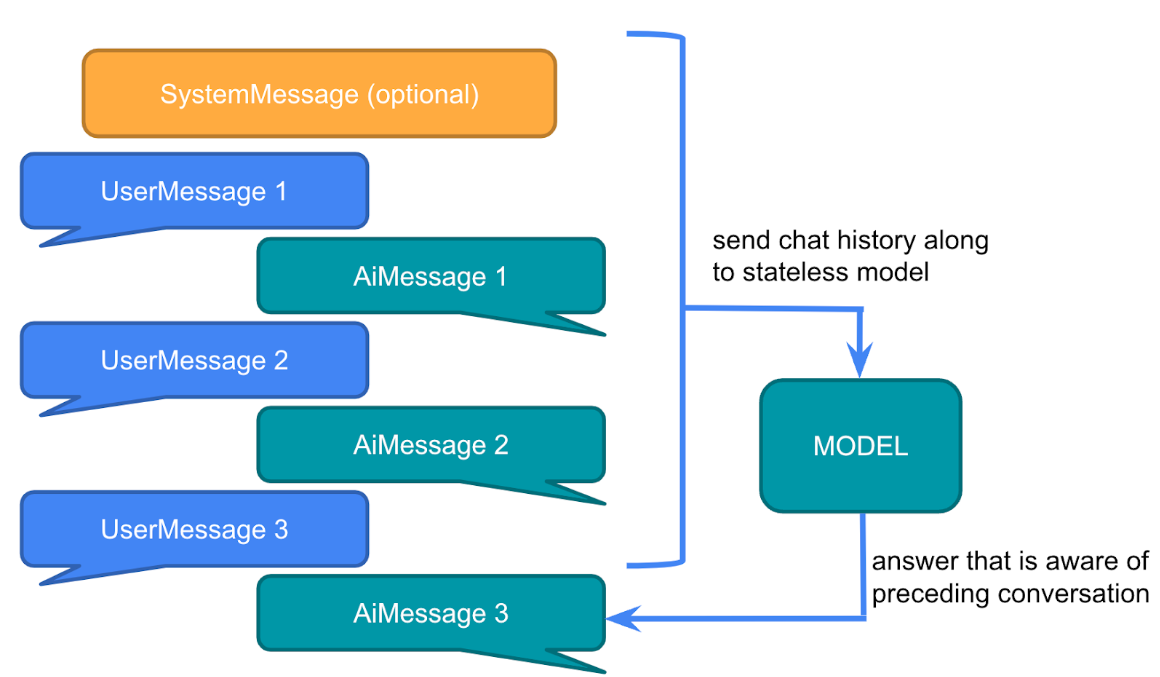
SpringAi提供了一个ChatMemory的组件用于存储聊天记录,允许您使用 LLM 跨多个交互存储和检索信息。并且可以为不同用户的多个交互之间维护上下文或状态。
可以在每次对话的时候把当前聊天信息和模型的响应存储到ChatMemory, 然后下一次对话把聊天记录取出来再发给大模型。
`
//输出 名字叫徐庶
但是这样做未免太麻烦! 能不能简化? 思考一下!
 用我们之前的Advisor对话拦截是不是就可以不用每次手动去维护了。 并且SpringAi早已体贴的为我提供了ChatMemoryAutoConfiguration自动配置类
用我们之前的Advisor对话拦截是不是就可以不用每次手动去维护了。 并且SpringAi早已体贴的为我提供了ChatMemoryAutoConfiguration自动配置类
org.springframework.ai
spring-ai-autoconfigure-model-chat-memory
@AutoConfiguration
@ConditionalOnClass({ ChatMemory.class, ChatMemoryRepository.class })
public class ChatMemoryAutoConfiguration {
@Bean
@ConditionalOnMissingBean
ChatMemoryRepository chatMemoryRepository() {
return new InMemoryChatMemoryRepository();
}
@Bean
@ConditionalOnMissingBean
ChatMemory chatMemory(ChatMemoryRepository chatMemoryRepository) {
return MessageWindowChatMemory.builder().chatMemoryRepository(chatMemoryRepository).build();
}
}
所以我们可以这样用:
SpringAi提供了 PromptChatMemoryAdvisor 专门用于对话记忆的拦截
@SpringBootTest
public class ChatMemoryTest {
ChatClient chatClient;
@BeforeEach
public void init(@Autowired
DeepSeekChatModel chatModel,
@Autowired
ChatMemory chatMemory) {
chatClient = ChatClient
.builder(chatModel)
.defaultAdvisors(
// PromptChatMemoryAdvisor拦截器 就会自动将我们与大模型的历史对话记录下来
PromptChatMemoryAdvisor.builder(chatMemory).build()
)
.build();
}
@Test
public void testChatOptions() {
String content = chatClient.prompt()
.user("我叫徐庶 ?")
//
.advisors(new ReReadingAdvisor())
.call()
.content();
System.out.println(content);
System.out.println("--------------------------------------------------------------------------");
content = chatClient.prompt()
.user("我叫什么 ?")
.advisors(new ReReadingAdvisor())
.call()
.content();
System.out.println(content);
}
}
你要知道, 我们把聊天记录发给大模型, 都是算token计数的。
大模型的token是有上限了, 如果你发送过多聊天记录,可能就会导致token过长。
如下是大模型存储的 token 历史条数上限。
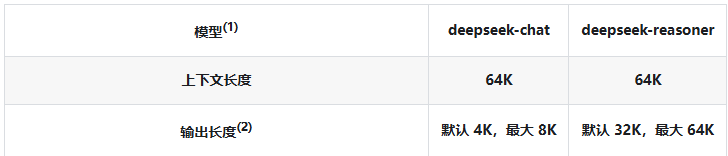
并且更多的token也意味更多的费用, 更久的解析时间. 所以不建议太长
(DEFAULT_MAX_MESSAGES默认20即10次对话)
一旦超出DEFAULT_MAX_MESSAGES只会存最后面N条(可以理解为先进先出),参考MessageWindowChatMemory源码
@Bean
ChatMemory chatMemory(@Autowired ChatMemoryRepository chatMemoryRepository) {
// MessageWindowChatMemory 创建一个历史对话存储的配置,
return MessageWindowChatMemory
.builder()
.maxMessages(10) // 设置最大存储 10 条
.chatMemoryRepository(chatMemoryRepository).build();
}
如果有多个用户在进行对话, 肯定不能将对话记录混在一起, 不同的用户的对话记忆需要隔离
@Test
public void testChatOptions() {
String content = chatClient.prompt()
.user("我叫徐庶 ?")
// 注意:这里要先构建一个 ChatMemory的 Bean,和上面类似,这里我们设置历史对话的用户ID
.advisors(advisorSpec -> advisorSpec.param(ChatMemory.CONVERSATION_ID,"1"))
.call()
.content();
System.out.println(content);
System.out.println("--------------------------------------------------------------------------");
content = chatClient.prompt()
.user("我叫什么 ?")
.advisors(advisorSpec -> advisorSpec.param(ChatMemory.CONVERSATION_ID,"1"))
.call()
.content();
System.out.println(content);
System.out.println("--------------------------------------------------------------------------");
content = chatClient.prompt()
.user("我叫什么 ?")
.advisors(advisorSpec -> advisorSpec.param(ChatMemory.CONVERSATION_ID,"2"))
.call()
.content();
System.out.println(content);
}
会发现, 不同的CONVERSATION_ID,会有不同的记忆

主要有前置存储
MessageWindowChatMemory
具体存储实现
ChatMemoryRepository
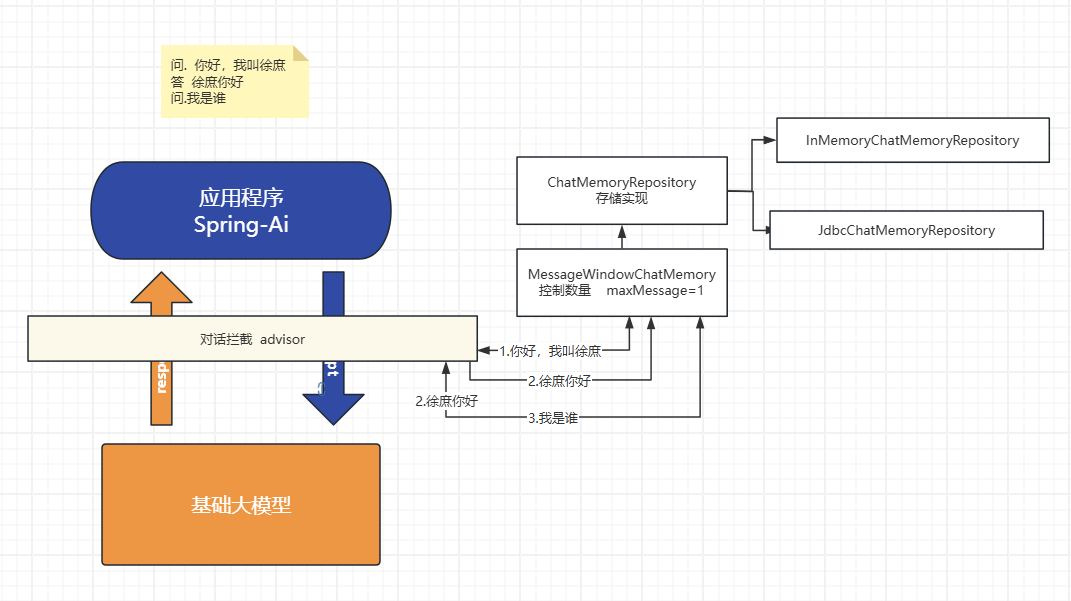
默认情况, 对话内容会存在jvm内存会导致:
springAi内置提供了以下几种方式(例如 Cassandra、JDBC 或 Neo4j), 这里演示下JDBC方式
org.springframework.ai
spring-ai-starter-model-chat-memory-repository-jdbc
org.springframework.boot
spring-boot-starter-jdbc
com.mysql
mysql-connector-j
runtime
spring.ai.chat.memory.repository.jdbc.initialize-schema=always
spring.ai.chat.memory.repository.jdbc.schema=classpath:/schema-mysql.sql
如下是 MySQL 的配置:
spring:
datasource:
username: root
password: 123456
url: jdbc:mysql://localhost:3306/springai?characterEncoding=utf8&useSSL=false&serverTimezone=UTC&
driver-class-name: com.mysql.cj.jdbc.Driver
@Configuration
public class ChatMemoryConfig {
@Bean // JdbcChatMemoryRepository 是已经被封装好自动装配好了,就可以使用
ChatMemory chatMemory(@Autowired JdbcChatMemoryRepository chatMemoryRepository) {
return MessageWindowChatMemory
.builder()
.maxMessages(1) // 设置存储为上面我们传的变量的 jdbc 的存储方式
.chatMemoryRepository(chatMemoryRepository).build();
}
}
CREATE TABLE IF NOT EXISTS SPRING_AI_CHAT_MEMORY (
`conversation_id` VARCHAR(36) NOT NULL,
`content` TEXT NOT NULL,
`type` VARCHAR(10) NOT NULL,
`timestamp` TIMESTAMP NOT NULL,
INDEX `SPRING_AI_CHAT_MEMORY_CONVERSATION_ID_TIMESTAMP_IDX` (`conversation_id`, `timestamp`)
);
@SpringBootTest
public class ChatMemoryTest {
ChatClient chatClient;
@BeforeEach
public void init(@Autowired
DeepSeekChatModel chatModel,
@Autowired
ChatMemory chatMemory) {
chatClient = ChatClient
.builder(chatModel)
.defaultAdvisors(
PromptChatMemoryAdvisor.builder(chatMemory).build()
)
.build();
}
@Test
public void testChatOptions() {
String content = chatClient.prompt()
.user("你好,我叫徐庶!")
.advisors(new ReReadingAdvisor())
.advisors(advisorSpec -> advisorSpec.param(ChatMemory.CONVERSATION_ID,"1"))
.call()
.content();
System.out.println(content);
System.out.println("--------------------------------------------------------------------------");
content = chatClient.prompt()
.user("我叫什么 ?")
.advisors(new ReReadingAdvisor())
.advisors(advisorSpec -> advisorSpec.param(ChatMemory.CONVERSATION_ID,"1"))
.call()
.content();
System.out.println(content);
}
}
可以看到由于我设置.maxMessages(1)数据库只存一条

扩展:其实我可以让其存储到我们的所有历史对话,因为数据库就是存储数据的吗,而且存储起来的数据可能还是可以用于我们分析测试用户的对话的。那我们取数据库的时候,可以获取最新一条的数据即可。
如果你想用redis , 你需要自己实现ChatMemoryRepository接口(自己实现增、删、查)
Redis 存储更快,我们如果一般就是仅仅只是临时存储用户的 100 条记录什么的,就存到 Redis 当中就好了,超过了 100 条记录,也是会存储到用户最新的那 100 条记录,后续的内容也不用持久化了,丢了就丢了,反正都是用户的一个临时历史对话记录而已。性能也是比 MySQL 更快的。
但是alibaba-ai有现成的实现:(还包括ES)
https://github.com/alibaba/spring-ai-alibaba/tree/main/community/memories
5.2.0
com.alibaba.cloud.ai
spring-ai-alibaba-starter-memory-redis
redis.clients
jedis
${jedis.version}
spring:
ai:
memory:
redis:
host: localhost
port: 6379
timeout: 5000
password:
@Configuration
public class RedisMemoryConfig {
@Value("${spring.ai.memory.redis.host}")
private String redisHost;
@Value("${spring.ai.memory.redis.port}")
private int redisPort;
@Value("${spring.ai.memory.redis.password}")
private String redisPassword;
@Value("${spring.ai.memory.redis.timeout}")
private int redisTimeout;
@Bean
public RedisChatMemoryRepository redisChatMemoryRepository() {
return RedisChatMemoryRepository._builder_()
.host(redisHost)
.port(redisPort)
// 若没有设置密码则注释该项
// .password(redisPassword)
.timeout(redisTimeout)
.build();
}
@Bean // RedisChatMemoryRepository 被我们上面 Bean 注入了
ChatMemory chatMemory(@Autowired RedisChatMemoryRepository redisMemoryRepository) {
return MessageWindowChatMemory
.builder()
.maxMessages(1) // 设置存储为上面我们传的变量的 jdbc 的存储方式
.chatMemoryRepository(redisMemoryRepository).build();
}
}
记忆多=聪明(大模型记录了多了用户的历史对话记录,就更加能够理解我们,实现我们的需求了), 但是记忆多会触发 token 上限(每个大模型的 token 是有上限的,不可以无限的存储。)
要知道, 无论你用什么存储对话以及, 也只能保证服务端的存储性能。
但是一旦聊天记录多了依然会超过token上限, 但是有时候我们依然希望存储更多的聊天记录,这样才能保证整个对话更像“人”。
多层次记忆架构(模仿人类)
以Boolean为例 , 在 agent 中可以用于判定用于的内容2个分支, 不同的分支走不同的逻辑
ChatClient chatClient;
@BeforeEach
public void init(@Autowired
DashScopeChatModel chatModel) {
chatClient = ChatClient.builder(chatModel).build();
}
@Test
public void testBoolOut() {
Boolean isComplain = chatClient
.prompt()
.system("""
请判断用户信息是否表达了投诉意图?
只能用 true 或 false 回答,不要输出多余内容
""")
.user("你们家的快递迟迟不到,我要退货!")
.call()
.entity(Boolean.class); // 结构化输出,让大模型输出 Boolean.class java当中的布尔值类型
// 分支逻辑
if (Boolean.TRUE.equals(isComplain)) {
System.out.println("用户是投诉,转接人工客服!");
} else {
System.out.println("用户不是投诉,自动流转客服机器人。");
// todo 继续调用 客服ChatClient进行对话
}
}
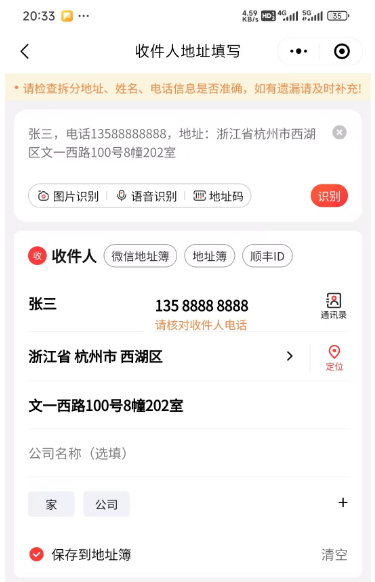
用购物APP应该见过复制一个地址, 自动为你填入每个输入框。 用大模型轻松完成!
public record Address(
String name, // 收件人姓名
String phone, // 联系电话
String province, // 省
String city, // 市
String district, // 区/县
String detail // 详细地址
) {}
@Test
public void testEntityOut() {
Address address = chatClient.prompt()
// .systemshi 是一个系统提示词,优先级更高
.system("""
请从下面这条文本中提取收货信息
""")
.user("收货人:张三,电话13588888888,地址:浙江省杭州市西湖区文一西路100号8幢202室")
.call()
.entity(Address.class); // 大模型会根据文本内容,将其中的用户的对话信息识别存储到我们的 Address的对象类
System.out.println(address);
}
public record Address(
String name, // 收件人姓名
String phone, // 联系电话
String province, // 省
String city, // 市
String district, // 区/县
String detail // 详细地址
) {}
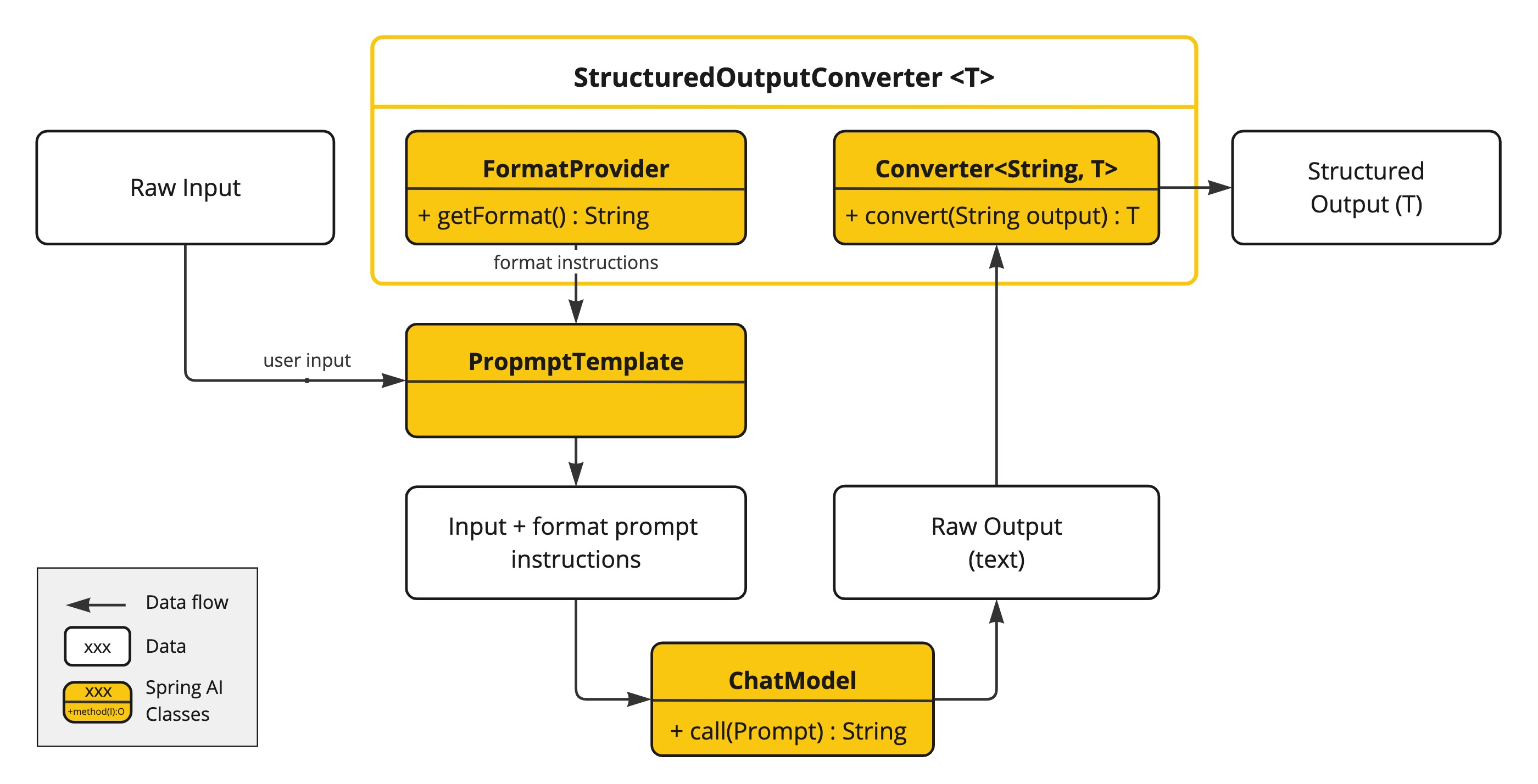
ChatModel或者直接使用低级API:
@Test
public void testLowEntityOut(
@Autowired DashScopeChatModel chatModel) {
// BeanOutputConverter 转换器
BeanOutputConverter beanOutputConverter =
new BeanOutputConverter(ActorsFilms.class);
String format = beanOutputConverter.getFormat();
String actor = "周星驰";
String template = """
提供5部{actor}导演的电影.
{format}
""";
PromptTemplate promptTemplate = PromptTemplate.builder().template(template).variables(Map.of("actor", actor, "format", format)).build();
ChatResponse response = chatModel.call(
promptTemplate.create()
);
ActorsFilms actorsFilms = beanOutputConverter.convert(response.getResult().getOutput().getText());
System.out.println(actorsFilms);
}
“在这个最后的篇章中,我要表达我对每一位读者的感激之情。你们的关注和回复是我创作的动力源泉,我从你们身上吸取了无尽的灵感与勇气。我会将你们的鼓励留在心底,继续在其他的领域奋斗。感谢你们,我们总会在某个时刻再次相遇。”
 登录查看全部
登录查看全部
参与评论
手机查看
返回顶部
