Spring AI Alibaba 开源项目基于 Spring AI 构建,是阿里云通义系列模型及服务在 Java AI 应用开发领域的最佳实践,提供高层次的 AI API 抽象与云原生基础设施集成方案和企业级 AI 应用生态集成。
在用Spring AI搭建Java AI应用的时候,会碰到了各种让人头疼的配置动态管理的问题. 比如像调用算法模型的“API-KEY密钥”这类敏感配置.
还有想要模型的各类调用配置参数,以及Prompt Engineering里的Prompt Template如何可以在不发布重启应用的情况下,快速修改生效来响应业务需求.
Spring AI Alibaba 将结合Nacos来一一解决
并且老外的Spring AI框架对于像Open AI , 微软、亚马逊、谷歌 等大模型支持较好, 对于国产AI支持则不那么友好, 而Spring AI Alibaba 对于通义系列的大模型则是天生友好.
不过在学习这篇之前, 还是需要先了解一下Spring AI 框架. https://www.cnblogs.com/xjwhaha/p/19306045
以下是当前主流Java AI应用框架的对比
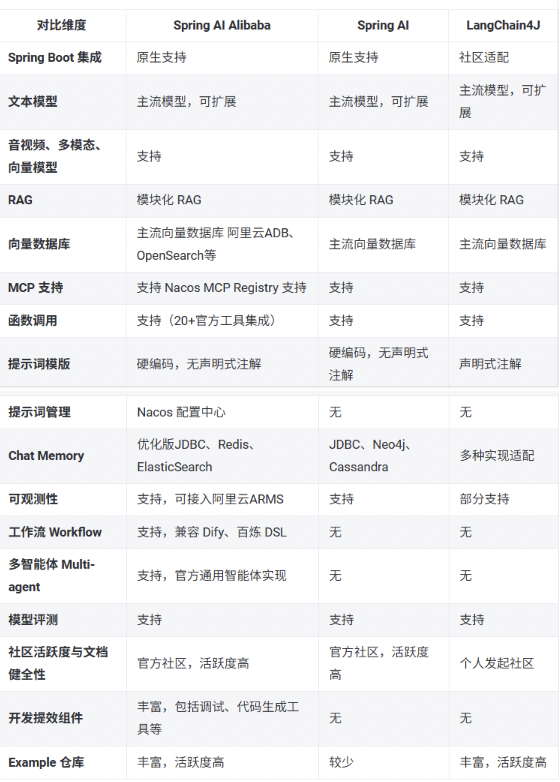
OpenAI Api 和 阿里的DashScope(灵积)Api的区别
OpenAI API 是 OpenAI 官方提供的一个 大模型接口平台,定义了开发者通过一套标准的 HTTP 调用模板来使用:
GPT 系列模型(GPT-4.1 / o3 / gpt-4.1-mini 等)
多模态模型(看图、语音)
Embeddings(向量)
文生图(DALL·E)
等等...
SpringAI框架就是使用这套API接口来进行调用, 同样模型的厂商也需要实现此接口, 双方通过达成一致,达到统一AI大模型访问的目的.
DashScope 是阿里云的 大模型 API 平台,提供“通义千问 + 多模态 + 向量 + 文生图 + 语音”的一站式接口,类似于国内版的 OpenAI API。同时,除了阿里自己的通义系列. 包括Deepseek和月之暗面等国内大模型, 也进行了封装, 也可以通过DashScopeAPI进行调用. SpringAIAlibaba 就支持使用DashScopeApi 来进行统一访问国产AI大模型的能力. 当然SpringAIAlibaba 也同样支持 OpenAIApi的访问方式,进行访问实现OpenAIAPI的大模型.例如OpenAI等等.
下面将实现一个天气预报的小助手功能, 来快速了解一下SAA的各个常用功能.
使用SpringAIAlibaba,先导入pom依赖:
这里优先使用了 DashScope的方式访大模型
com.alibaba.cloud.ai
spring-ai-alibaba-agent-framework
1.1.0.0-M5
com.alibaba.cloud.ai
spring-ai-alibaba-starter-dashscope
1.1.0.0-M5
application.yaml 配置:
指定apiKey,模型名称和访问路径. 注意apiKey生产环境建议配置在环境变量中
spring:
ai:
dashscope:
api-key: sk-********
base-url: https://dashscope.aliyunccnblogs.com
chat:
options:
model: qwen3-max
首先需要定义两个工具,一个用于获取当前用户的位置, 另外一个获取地方天气信息:
public record WeatherRequest(@ToolParam(description = "城市的名称") String location) {
}
// 天气查询工具
public static class WeatherForLocationTool implements BiFunction {
@Override
public String apply(
@ToolParam(description = "城市的名称") WeatherRequest city,
ToolContext toolContext) {
return StrUtil.equals("上海", city.location) ? "晴朗" : "小雨";
}
}
// 用户位置工具 - 使用上下文
public static class UserLocationTool implements BiFunction {
@Override
public String apply(
WeatherRequest query,
ToolContext toolContext) {
// 从上下文中获取用户信息
RunnableConfig config = (RunnableConfig) toolContext.getContext().get("_AGENT_CONFIG_");
String userId = (String) config.metadata("user_id").orElse(null);
if (userId == null) {
return "User ID not provided";
}
System.out.println("userId: " + userId);
return "1".equals(userId) ? "杭州" : "上海";
}
}
工具应该有良好的文档:它们的名称、描述和参数名称都会成为模型提示的一部分。
Spring AI 的 FunctionToolCallback 支持通过 @ToolParam 注解添加元数据,并支持通过 ToolContext 参数进行运行时注入。
构建ReactAgent, 用户访问大模型的类:
private final DashScopeChatModel chatModel;
public AgentConfiguration(DashScopeChatModel chatModel) {
this.chatModel = chatModel;
}
@Bean
public ReactAgent reactAgent() {
String SYSTEM_PROMPT = """
你是一位天气预报专家,说话比较幽默。
您可以访问两个工具:
- get_weather_for_location:使用它来获取指定位置的天气
— get_user_location:使用它来获取用户的当前位置
如果用户向你询问天气,你可以尝试分析他需要查询的位置。例如上海,杭州等.
但是如果用户没有指定位置,你需要调用get_user_location获取此用户的当前位置,查询此位置的天气
""";
return ReactAgent.builder()
.name("天气预报小助手")
.description("这是一个天气预报小助手智能体")
// 如果是简短,简单的系统提示可以用这个
// .systemPrompt(SYSTEM_PROMPT)
// 更详细的指令
.instruction(SYSTEM_PROMPT)
.tools(FunctionToolCallback.builder("weatherForLocationTool", new WeatherForLocationTool()).description("根据城市名称获取当前天气信息").inputType(WeatherRequest.class).build(),
FunctionToolCallback.builder("userLocationTool", new UserLocationTool()).description("获取用户当前位置").inputType(WeatherRequest.class).build()
)
// 基于内存的存储
.saver(new MemorySaver())
.outputType(ResponseFormat.class)
.model(chatModel)
.build();
}
下面是定义大模型返回的结构体
/**
* 使用 Java 类定义响应格式
*/
@Getter
@Setter
public class ResponseFormat {
/**
* 城市名称
*/
private String city;
/**
* 天气情况
*/
private String punnyResponse;
/**
* 关于该天气的一个有趣的浪漫的简语
*/
private String weatherConditions;
}
instruction方法,定义系统提示.引导大模型的执行方式.tools 方法注册创建的函数. 使大模型具有调用本地方法的能力saver方法注册一个用于存储历史记录的类,框架会自动读取当前指定的threadId来读取当前会话的历史记录, 使大模型调用具有历史记忆功能, 并且会自动将本次调用按threadId 为key存起来 ( 这里使用的MemorySaver 是基于内存, 生产需要使用基于持久化中间件的实现)outputType 方法定义大模型返回的数据结构为此对象的结构调用方式如下:
@RestController
@RequestMapping("/ai")
public class AiController {
@Resource
private ReactAgent reactAgent;
@GetMapping
public String ai(@RequestParam String question) throws Exception {
RunnableConfig runnableConfig = RunnableConfig.builder().threadId("threadId").addMetadata("user_id", "1").build();
return reactAgent.call(question, runnableConfig).getText();
}
}
threadId,相当于会话ID运行效果:
调用: http://127.0.0.1:8089/ai?question=上海天气怎么样
响应:
可以看到返回的数据为指定的json结构,并且自动读取问题中的城市信息,并调用了获取天气的方法.
再次调用: http://127.0.0.1:8089/ai?question=我这里呢
在没有询问城市时, 大模型自动调用了获取本地城市的方法,得到当前城市为杭州.
在上面的案例中, 我们实现了一个简单的天气查询工具类, 大模型具有调用本地方法的能力, 这背后的原理是什么样, ReactAgent 的执行流程是什么, 大模型是如何调用本地方法的?
什么是 ReactAgent?
这个循环使 Agent 能够:
而SAA框架中的ReactAgent是怎么完成这个工作的?
Spring AI Alibaba 中的ReactAgent 内容抽象了三个模块,由这三个模块相互配合完成
.model(chatModel)方法传入的大模型调用类)ReactAgent 的核心执行流程:
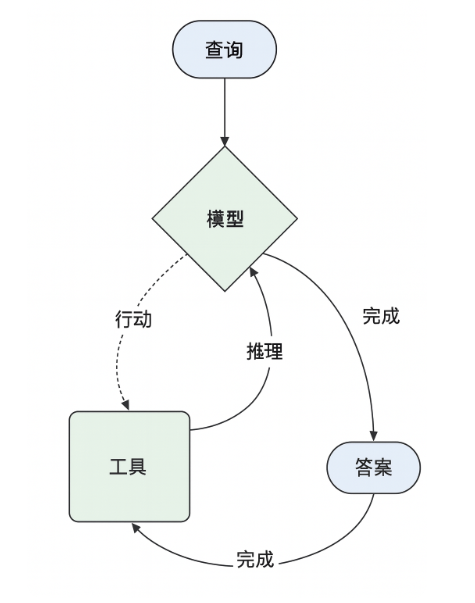
下面通过梳理上面天气小助手的执行流程来具体了解一下工作流程:
第一步: 发出提问
↓
第二步:SpringAI 构建一个 ChatRequest(包含tools和所有问题的上下文信息)
↓
第三步:序列化成 JSON
↓
第四步:通过 HTTP POST 调用大模型 API
↓
第五步:大模型进行判断推理,是否需要执行函数,执行哪个函数,在本案例中, 如果解析出城市名称, 则需要调用获取天气的函数, 如果没有,则需要调用获取用户位置的函数. 并返回执行函数的名称+入参
↓
第六步:ReactAgent解析返回JSON,进行推理是否是一次 function call
↓
第七步:如果是,则本地反射调用该方法,例如执行了获取用户位置的函数
↓
第八步:把该函数结果再封装成 JSON 发给大模型继续对话,大模型拿到此函数结果,继续分析推理,拿到位置后,大模型继续推理需要进行调用获取天气的函数,则继续返回客户 端调用
↓
第九步:ReactAgent继续解析返回JSON,执行获取天气的函数并返回
↓
第九步:最终返回结果给用户
在上面的流程中, 可以迅速的了解到上图的含义. 在模型和工具间循环,直到模型推理出最终结果为止.
也就是说,以ReactAgent为本体:
在上面关于ReactAgent的工作流程的介绍中, 除了Tool Node 和 Model Node 之外,还有一个组件为Hooks(钩子).
SAA框架在这些步骤的前后暴露了钩子点Hooks 和 拦截器Interceptors,允许你
框架中提供了四个抽象类供开发者实现,并在不同的节点调用
ModelHook: 在模型调用前后执行自定义逻辑
AgentHook: 在 Agent 一次问答整体执行的开始和结束时执行:
ModelInterceptor: 拦截和修改对模型的请求和响应
ToolInterceptor:拦截和修改工具调用
下面的示例,分别实现了这四个抽象类,可以快速了解其使用方式:
public class MyHooks {
private static final String CALL_COUNT_KEY = "_model_call_count_";
private static final String START_TIME_KEY = "_call_start_time_";
// 1. AgentHook - 在 Agent 开始/结束时执行,每次Agent调用只会运行一次
@HookPositions({HookPosition.BEFORE_AGENT, HookPosition.AFTER_AGENT})
public static class LoggingHook extends AgentHook {
@Override
public String getName() {
return "logging";
}
@Override
public CompletableFuture注册钩子:
ReactAgent.builder()
.name("天气预报小助手")
.description("这是一个天气预报小助手智能体")
// 如果是简短,简单的系统提示可以用这个
// .systemPrompt(SYSTEM_PROMPT)
// 更详细的指令
.instruction(SYSTEM_PROMPT)
.tools(FunctionToolCallback.builder("weatherForLocationTool", new WeatherForLocationTool()).description("根据城市名称获取当前天气信息").inputType(WeatherRequest.class).build(),
FunctionToolCallback.builder("userLocationTool", new UserLocationTool()).description("获取用户当前位置").inputType(WeatherRequest.class).build()
)
// 基于内存的存储
.saver(new MemorySaver())
.outputType(ResponseFormat.class)
// 注册钩子和拦截器
.hooks(new MyHooks.LoggingHook(), new MyHooks.MessageTrimmingHook())
.interceptors(new MyHooks.LoggingInterceptor(), new MyHooks.ToolMonitoringInterceptor())
.model(chatModel)
.build();
启动调用: http://127.0.0.1:8089/ai?question=杭州今天天气怎么样
控制台打印:
Agent 开始执行时间2025-12-09 15:36:11
第1次调用模型开始
发送请求到模型: 1 条消息
第1次调用模型结束
执行工具: weatherForLocationTool执行参数: {"location": "杭州"}
第2次调用模型开始
发送请求到模型: 3 条消息
第2次调用模型结束
Agent 执行完成,耗时:5084
Spring AI Alibaba 为常见用例提供了预构建的 Hooks 和 Interceptors 实现:模型调用限制(Model Call Limit),LLM Tool Selector(LLM 工具选择器) 等等.
Human-in-the-Loop(人机协同)
在调用指定的Tool时, 暂停 Agent 执行以获得人工批准、编辑或拒绝工具调用。
适用场景:
使用示例: 将模拟一个发送邮件的Agent, 每次发送邮件,都需要手动人为审批
Tool.当模型判断需要调用次方法时,会中断流程,并等待人工审批,再继续执行 public record EmailRequest(@ToolParam(description = "发送邮件的信息") String message) {
}
// 发送email
public static class SendEmailTool implements BiFunction {
@Override
public Boolean apply(
@ToolParam(description = "发送邮件的信息") EmailRequest message,
ToolContext toolContext) {
System.out.println("发送邮件: " + message.message);
return true;
}
}
Tool, 并传入一个humanInTheLoopHook 实例, 描述调用审批的节点, 注意,这里一定需要传入 saver 作为检查点, 因为中断后再次调用,需要依赖历史记录message,并携带上下文,才能使调用前后的流程衔接, 这里使用了测试用的实例MemorySaver,基于内存 @Bean
public ReactAgent emailReactAgent() {
String SYSTEM_PROMPT = """
你是一个工作平台的助手
您可以访问一个工具:
- sendEmailTool:使用该工具进行发送邮件的操作
如果用户有需要发送邮件,可以进行操作
""";
// 创建人工介入Hook
HumanInTheLoopHook humanInTheLoopHook = HumanInTheLoopHook.builder()
.approvalOn("sendEmailTool", ToolConfig.builder()
.description("发送邮件需要审批")
.build())
.build();
return ReactAgent.builder()
.name("工作助手")
.instruction(SYSTEM_PROMPT)
.tools(FunctionToolCallback.builder("sendEmailTool", new SendEmailTool()).description("进行发送邮件的操作").inputType(EmailRequest.class).build()
)
// 基于内存的存储
.saver(new MemorySaver())
.hooks(humanInTheLoopHook)
.model(chatModel)
.build();
}
@GetMapping
public String ai(@RequestParam String question) throws Exception {
RunnableConfig runnableConfig = RunnableConfig.builder().threadId("threadId").build();
Optional result = reactAgent.invokeAndGetOutput(question, runnableConfig);
if (result.isPresent() && result.get() instanceof InterruptionMetadata) {
System.out.println("检测到中断,需要人工审批");
interruptionMetadata = (InterruptionMetadata) result.get();
return "已发送审批中";
}
List list = (List) result.get().state().data().get("messages");
return list.get(list.size() - 1).getText();
}
@GetMapping("agree")
public void agree() throws Exception {
List toolFeedbacks =
interruptionMetadata.toolFeedbacks();
InterruptionMetadata.Builder feedbackBuilder = InterruptionMetadata.builder()
.nodeId(interruptionMetadata.node())
.state(interruptionMetadata.state());
toolFeedbacks.forEach(toolFeedback -> {
InterruptionMetadata.ToolFeedback approvedFeedback =
InterruptionMetadata.ToolFeedback.builder(toolFeedback)
.result(InterruptionMetadata.ToolFeedback.FeedbackResult.APPROVED)
.build();
feedbackBuilder.addToolFeedback(approvedFeedback);
});
InterruptionMetadata approvalMetadata = feedbackBuilder.build();
//第二次调用 - 使用人工反馈恢复执行, 需要指定同一个会话ID
RunnableConfig resumeConfig = RunnableConfig.builder()
.threadId("threadId")
.addMetadata(RunnableConfig.HUMAN_FEEDBACK_METADATA_KEY, approvalMetadata)
.build();
Optional finalResult = reactAgent.invokeAndGetOutput("", resumeConfig);
if (finalResult.isPresent()) {
System.out.println("执行完成");
System.out.println("最终结果: " + finalResult.get());
}
}
启动程序,进行测试 :
http://127.0.0.1:8089/ai?question=我要发送邮件响应: 请提供您要发送的邮件内容,包括具体的信息或主题,这样我才能帮您完成发送操作。
响应: 已发送审批中
http://127.0.0.1:8089/ai/agree大模型返回: 邮件已成功发送!, 并且发送邮件的方法打印日志 : 发送邮件: 测试一下邮件发送
整体流程如上
大型语言模型(LLM)虽然强大,但有两个关键限制:
检索通过在查询时获取相关的外部知识来解决这些问题。这是检索增强生成(RAG)的基础:使用特定上下文的信息来增强 LLM 的回答。
SAA的RAG 可以以多种方式实现,具体取决于你的系统需求。
在两步 RAG中,检索步骤总是在生成步骤之前执行。这种架构简单且可预测,适合许多应用,其中检索相关文档是生成答案的明确前提。
代码示例:
首先需要构建一个检索库,并指定一个向量模型(这里使用的仍然是通义的模型),,并从外部读取一个公司规章制度的文档,将其内容向量化, 作为AI的外部知识库. 并给Agent设置好提示词
@Bean
public VectorStore vectorStore(EmbeddingModel embeddingModel) {
SimpleVectorStore simpleVectorStore =
SimpleVectorStore.builder(embeddingModel).build();
// 1. 加载文档
Resource resource = new FileSystemResource("/Users/hehe/Downloads/text.txt");
TextReader textReader = new TextReader(resource);
List documents = textReader.get();
// 2. 分割文档为块
TokenTextSplitter splitter = new TokenTextSplitter();
List chunks = splitter.apply(documents);
//向量化存储
simpleVectorStore.add(chunks);
return simpleVectorStore;
}
@Bean
public ReactAgent ragReactAgent() {
String SYSTEM_PROMPT = """
你是一个公司内部智能助手,你需要根据公司规章制度文档,来回答公司员工的问题.
""";
return ReactAgent.builder()
.name("工作助手")
.instruction(SYSTEM_PROMPT)
// 基于内存的存储
.saver(new MemorySaver())
.model(chatModel)
.build();
}
公司规章制度如下:
考勤制度
一、为加强考勤管理,维护工作秩序,提高工作效率,特制定本制度。
二、公司员工必须自觉遵守劳动纪律,按时上下班,不迟到,不早退,工作时间不得擅自离开工作岗位,外出办理业务前,须经本部门负责人同意。
三、周一至周六为工作日,周日为休息日。公司机关周日和夜间值班由办公室统一安排,市场营销部、项目技术部、投资发展部、会议中心周日值班由各部门自行安排,报分管领导批准后执行。因工作需要周日或夜间加班的,由各部门负责人填写加班审批表,报分管领导批准后执行。节日值班由公司统一安排。
四、严格请、销假制度。员工因私事请假1天以内的(含1天),由部门负责人批准;3天以内的(含3天),由副总经理批准;3天以上的,报总经理批准。副总经理和部门负责人请假,一律由总经理批准。请假员工事毕向批准人销假。未经批准而擅离工作岗位的按旷工处理。
五、上班时间开始后5分钟至30分钟内到班者,按迟到论处;超过30分钟以上者,按旷工半天论处。提前30分钟以内下班者,按早退论处;超过30分钟者,按旷工半天论处。
六、1个月内迟到、早退累计达3次者,扣发5天的基本工资;累计达3次以上5次以下者,扣发10天的基本工资;累计达5次以上10次以下者,扣发当月15天的基本工资;累计达10次以上者,扣发当月的基本工资。
七、旷工半天者,扣发当天的基本工资、效益工资和奖金;每月累计旷工1天者,扣发5天的基本工资、效益工资和奖金,并给予一次警告处分;每月累计旷工2天者,扣发10天的基本工资、效益工资和奖金,并给予记过1次处分;每月累计旷工3天者,扣发当月基本工资、效益工资和奖金,并给予记大过1次处分;每月累计旷工3天以上,6天以下者,扣发当月基本工资、效益工资和奖金,第二个月起留用察看,发放基本工资;每月累计旷工6天以上者(含6天),予以辞退。
八、工作时间禁止打牌、下棋、串岗聊天等做与工作无关的事情。如有违反者当天按旷工1天处理;当月累计2次的,按旷工2天处理;当月累计3次的,按旷工3天处理。
九、参加公司组织的会议、培训、学习、考试或其他团队活动,如有事请假的,必须提前向组织者或带队者请假。在规定时间内未到或早退的,按照本制度第五条、第六条、第七条规定处理;未经批准擅自不参加的,视为旷工,按照本制度第七条规定处理。
十、员工按规定享受探亲假、婚假、产育假、结育手术假时,必须凭有关证明资料报总经理批准;未经批准者按旷工处理。员工病假期间只发给基本工资。
十一、经总经理或分管领导批准,决定假日加班工作或值班的每天补助20元;夜间加班或值班的,每个补助10元;节日值班每天补助40元。未经批准,值班人员不得空岗或迟到,如有空岗者,视为旷工,按照本制度第七条规定处理;如有迟到者,按本制度第五条、第六条规定处理。
十二、员工的考勤情况,由各部门负责人进行监督、检查,部门负责人对本部门的考勤要秉公办事,认真负责。如有弄虚作假、包庇袒护迟到、早退、旷工员工的,一经查实,按处罚员工的双倍予以处罚。凡是受到本制度第五条、第六条、第七条规定处理的员工,取消本年度先进个人的评比资格。
使用时,按照两步 RAG的使用方式, 需要先根据问题,在向量库中检索与问题相关的内容,并携带到问题的上下文中.
@GetMapping
public String ai(@RequestParam String question) throws Exception {
RunnableConfig runnableConfig = RunnableConfig.builder().threadId("threadId").build();
List messages = new ArrayList();
// 根据问题检索内容
List documents = vectorStore.similaritySearch(question);
if (CollectionUtil.isNotEmpty(documents)) {
// 构建上下文
String context = documents.stream()
.map(Document::getText)
.collect(Collectors.joining("""
"""));
Message contextMessage = new UserMessage("请根据以下上下文,回答问题:" + context);
messages.add(contextMessage);
}
messages.add(new UserMessage(question));
return reactAgent.call(messages, runnableConfig).getText();
}
启动调用:http://127.0.0.1:8089/ai?question=一个月可以迟到几次
响应:
根据所提供的《考勤制度》第六条规定: > 六、1个月内迟到、早退累计达3次者,扣发5天的基本工资;累计达3次以上5次以下者,扣发10天的基本工资;累计达5次以上10次以下者,扣发当月15天的基本工资;累计达10次以上者,扣发当月的基本工资。 从制度内容可以看出: - 公司并未规定“允许”迟到的具体次数,而是对迟到行为设定了逐级处罚措施。 - 即使迟到1次,也属于违纪行为(按第五条定义为“迟到”),只是在第6条中从累计达3次起开始经济处罚。 - 因此,理想情况下,一个月应迟到0次。 - 但若从“不被扣工资”的角度理解“可以迟到几次”,那么最多可迟到2次(因为第3次起就要扣工资)。 结论: 严格来说,公司不允许迟到;但从处罚起点看,一个月内迟到不超过2次不会触发第六条的工资扣罚,但依然属于违反考勤纪律的行为。
可以看到,大模型成功的回答出了他本身认知之外的问题, 读取了公司内部的文档
Agentic 检索增强生成(RAG)将检索增强生成的优势与基于 Agent 的推理相结合。Agent(由 LLM 驱动)不是在回答之前检索文档,而是逐步推理并决定在交互过程中何时以及如何检索信息。
示例:
同样需要构建一个存储库, 并加载文档. 再建一个Tool, 供Agent查询文档使用
@Bean
public VectorStore vectorStore(EmbeddingModel embeddingModel) {
SimpleVectorStore simpleVectorStore =
SimpleVectorStore.builder(embeddingModel).build();
// 1. 加载文档
Resource resource = new FileSystemResource("/Users/hehe/Downloads/text.txt");
TextReader textReader = new TextReader(resource);
List documents = textReader.get();
// 2. 分割文档为块
TokenTextSplitter splitter = new TokenTextSplitter();
List chunks = splitter.apply(documents);
//向量化存储
simpleVectorStore.add(chunks);
return simpleVectorStore;
}
public record SearchRequest(@ToolParam(description = "检索文档的问题") String question) {
}
// 可以检索公司文档
public static class SearchDocumentTool implements BiFunction {
@Override
public String apply(
@ToolParam(description = "检索文档的问题") SearchRequest question,
ToolContext toolContext) {
List documents = SpringUtil.getBean("vectorStore", VectorStore.class).similaritySearch(question.question);
if (documents.isEmpty()) {
return "没有找到相关的文档";
}
//返回检索到的数据
return documents.stream().map(Document::getText).collect(Collectors.joining("""
"""));
}
}
注册Tool,并指示模型调用
@Bean
public ReactAgent ragReactAgent() {
String SYSTEM_PROMPT = """
你是一个公司内部智能助手
你可以根据以下工具检索公司的文档,来提供上下文:
- searchDocumentTool: 通过该工具检索公司文档
你需要根据公司规章制度文档,来回答公司员工的问题.
""";
return ReactAgent.builder()
.name("工作助手")
.instruction(SYSTEM_PROMPT)
.tools(FunctionToolCallback.builder("searchDocumentTool", new SearchDocumentTool()).description("检索文档").inputType(SearchRequest.class).build())
// 基于内存的存储
.saver(new MemorySaver())
.model(chatModel)
.build();
}
使用方式:
@GetMapping
public String ai(@RequestParam String question) throws Exception {
RunnableConfig runnableConfig = RunnableConfig.builder().threadId("threadId").build();
return reactAgent.call(question, runnableConfig).getText();
}
启动调用: http://127.0.0.1:8089/ai?question=节假日上班补贴多少
返回响应:
根据提供的考勤制度,关于节假日上班的补贴标准如下: - 假日加班或值班:每天补助 20元。 - 夜间加班或值班:每个补助 10元。 - 节日值班:每天补助 40元。 需要注意的是,所有加班或值班必须经过总经理或分管领导批准,未经批准不得擅自离岗或迟到,否则将按旷工处理。
成功读取文档内容
混合 RAG 结合了两步 RAG 和 Agentic RAG 的特点。它引入了中间步骤,如查询预处理、检索验证和生成后检查。这些系统比固定管道提供更多灵活性,同时保持对执行的一定控制。
典型组件包括:
官网的概念性示例:
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.VectorStore;
import java.util.List;
import java.util.stream.Collectors;
class HybridRAGSystem {
private final ChatModel chatModel;
private final VectorStore vectorStore;
public HybridRAGSystem(ChatModel chatModel, VectorStore vectorStore) {
this.chatModel = chatModel;
this.vectorStore = vectorStore;
}
public String answer(String userQuestion) {
// 1. 查询增强
String enhancedQuery = enhanceQuery(userQuestion);
int maxAttempts = 3;
for (int attempt = 0; attempt docs = vectorStore.similaritySearch(enhancedQuery);
// 3. 检索验证
if (!isRetrievalSufficient(docs)) {
enhancedQuery = refineQuery(enhancedQuery, docs);
continue;
}
// 4. 生成答案
String answer = generateAnswer(userQuestion, docs);
// 5. 答案验证
ValidationResult validation = validateAnswer(answer, docs);
if (validation.isValid()) {
return answer;
}
// 6. 根据验证结果决定下一步
if (validation.shouldRetry()) {
enhancedQuery = refineBasedOnValidation(enhancedQuery, validation);
} else {
return answer; // 返回当前最佳答案
}
}
return "无法生成满意的答案";
}
private String enhanceQuery(String query) {
return query; // 实现查询增强逻辑
}
private boolean isRetrievalSufficient(List docs) {
return !docs.isEmpty() && calculateRelevanceScore(docs) > 0.7;
}
private double calculateRelevanceScore(List docs) {
return 0.8; // 实现相关性评分逻辑
}
private String refineQuery(String query, List docs) {
return query; // 实现查询优化逻辑
}
private String generateAnswer(String question, List docs) {
String context = docs.stream()
.map(Document::getText)
.collect(Collectors.joining("
"));
ChatClient client = ChatClient.builder(chatModel).build();
return client.prompt()
.system("基于以下上下文回答问题:
" + context)
.user(question)
.call()
.content();
}
private ValidationResult validateAnswer(String answer, List docs) {
// 实现答案验证逻辑
return new ValidationResult(true, false);
}
private String refineBasedOnValidation(String query, ValidationResult validation) {
return query; // 基于验证结果优化查询
}
class ValidationResult {
private boolean valid;
private boolean shouldRetry;
public ValidationResult(boolean valid, boolean shouldRetry) {
this.valid = valid;
this.shouldRetry = shouldRetry;
}
public boolean isValid() { return valid; }
public boolean shouldRetry() { return shouldRetry; }
}
}
 登录查看全部
登录查看全部
参与评论
手机查看
返回顶部