在人工智能技术从理论突破走向工程落地的进程中,一篇篇里程碑式的论文如同灯塔,照亮了技术演进的关键路径。为帮助大家吃透 AI 核心技术的底层逻辑、理清行业发展脉络,博主推出「AI 十大核心论文解读系列」,每篇聚焦一篇关键论文的问题背景、核心创新与行业影响。本篇博客解读《Attention Is All You Need》论文。
@
在人工智能工程的发展史上,有一批论文如同“灯塔”,照亮了技术突破的方向。“AI工程领域十大核心论文”覆盖模型架构、微调技术、检索增强、智能体等关键方向,而2017年谷歌团队发表的《Attention Is All You Need》,无疑是其中最具“奠基性”的一篇——它彻底脱离前人的序列模型框架,以全新的“自注意力机制”重构了自然语言处理(NLP)乃至整个深度学习的技术路径。
如果说GPT、BERT、LLaMA等大模型是AI时代的“高楼大厦”,那《Attention Is All You Need》就是搭建这些大厦的“钢筋骨架”。如今几乎所有现代大型语言模型(LLM)的设计,都离不开这篇论文提出的Transformer架构。无论是AI工程师面试必问的“并行计算原理”,还是日常开发依赖的“上下文理解能力”,其技术根源都能追溯到这篇仅11页的论文。今天,我们就来深度拆解这篇改变AI格局的经典之作。
论文链接:https://arxiv.org/abs/1706.03762
2017年之前,NLP领域的主流技术方案是循环神经网络(RNN) 和卷积神经网络(CNN),但这两种模型存在难以突破的瓶颈,直接限制了AI处理复杂文本的能力。
RNN的核心逻辑是“逐句、逐词处理文本”——分析一句话时,模型必须先处理第一个词,再基于其结果处理第二个词,以此类推。这种串行模式如同人逐字读文章,无法同时处理多个词汇,导致训练速度极慢。对于长文本,RNN的训练时间会呈指数级增长,根本无法支撑大规模数据训练。
RNN存在“短期记忆”缺陷。比如处理“小明昨天去超市买了苹果,他今天把____吃了”这句话时,RNN很难将“他”与前文的“小明”、“____”与前文的“苹果”关联起来。随着文本长度增加,早期词汇的信息会逐渐衰减,模型无法有效捕捉远距离词汇的语义联系。即便后续出现LSTM、GRU等改进模型,也只是缓解问题,并未从根本上解决。
当时AI训练已开始依赖多GPU集群提升效率,但RNN和CNN几乎无法支持高效并行。RNN的串行逻辑决定了“下一个词的计算必须依赖上一个词”,无法拆分任务到多个GPU同时执行;CNN虽能并行处理局部特征,但对长文本的全局语义理解能力弱,且并行粒度有限。这种“并行困境”导致模型规模难以扩大——扩大参数规模只能依赖单GPU硬扛,成本和时间都难以承受。
正是在这样的技术瓶颈下,《Attention Is All You Need》的出现如同一场“技术革命”,用全新思路解决了上述所有问题。
这篇论文的核心贡献只有一个:提出Transformer架构,用“自注意力机制”取代传统的序列处理逻辑。整个架构围绕“高效处理文本、支持并行计算、捕捉全局语义”三个目标设计,可从“核心机制”“架构细节”和“核心优势”三方面拆解。
专业定义:自注意力是将查询(Q)、键(K)、值(V)三组向量映射为输出的函数,输出是V的加权和,权重由Q与K的相似度计算得出。其核心是通过可学习的参数,为每个位置的token生成“全局依赖表征”,即每个token的最终向量都融合了所有其他token的语义信息。
通俗类比:把处理句子比作“班级自我介绍”——以前的RNN是“按座位顺序逐个发言,只能记住前一个人的名字”;自注意力是“所有人同时站起来,每个人手里举着自己的‘关键词牌’(K)和‘详细介绍’(V),你(当前token)拿着自己的‘需求牌’(Q),快速和所有人比对:和你需求越匹配的人,你越认真听他的介绍,最后把所有人的介绍按‘认真程度’加权整合,形成自己的最终印象”。
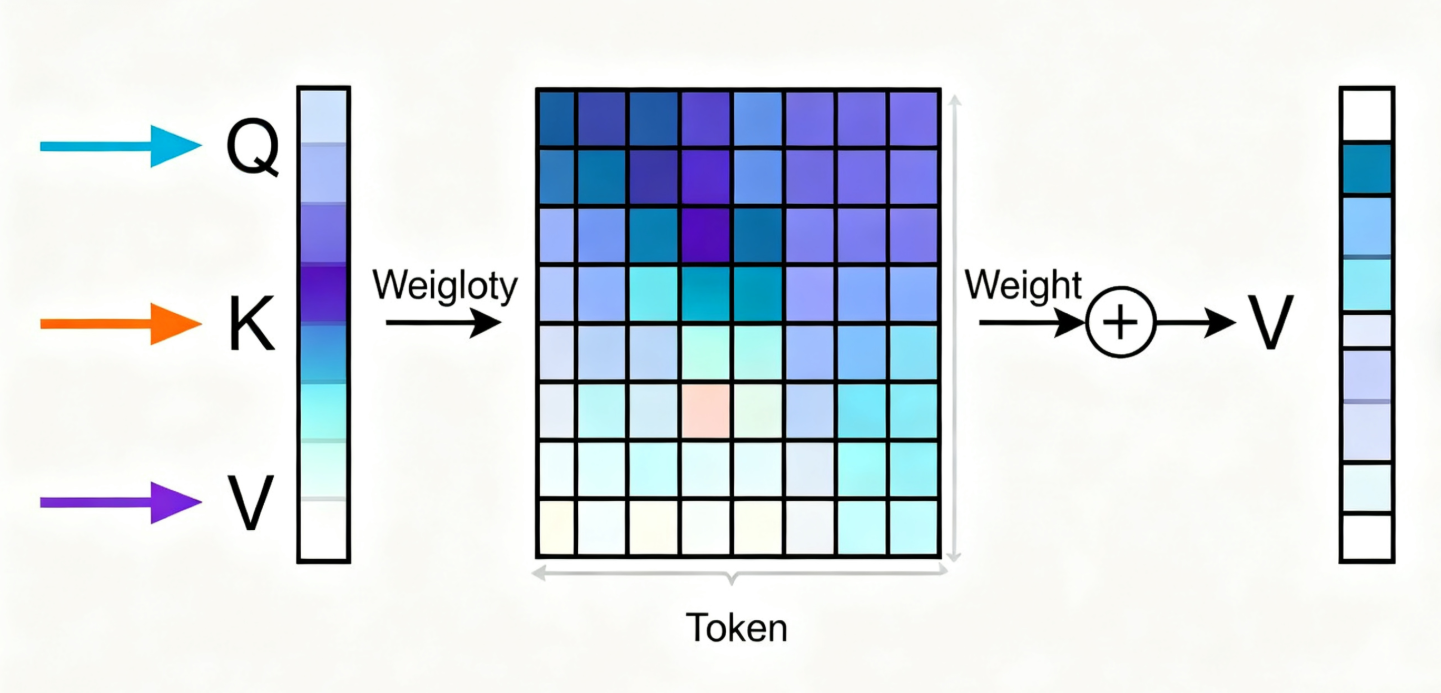
论文关键细节补充:
专业解释:为什么需要缩放?假设Q和K的每个元素都是均值为0、方差为1的独立随机变量,它们的点积$q·k=sum_{i=1}^{d_k}q_ik_i$的均值为0、方差为$d_k$。当$d_k$较大(如$d_k=512$)时,点积结果的数值会非常大,导致softmax函数的输入值落在“梯度接近0”的区域(softmax在输入值极大时,输出趋近于one-hot,导数几乎为0),模型无法更新参数。 缩放的作用:除以$sqrt{d_k}$后,点积的方差被归一化为1,避免softmax陷入“梯度消失陷阱”。
通俗类比:比如$d_k=64$时,$sqrt{d_k}=8$。如果不缩放,Q和K的点积可能达到几十甚至上百,softmax会“偏爱”分数最高的那个token,其他token的权重几乎为0(相当于“只看一个词,忽略其他所有”);缩放后,分数被“压缩”到合理范围(比如原来100分变成12.5分),softmax能更均衡地分配权重,模型能关注到多个相关token。

专业解释:核心操作是将Q、K、V通过8组独立的线性投影($W_iQ∈mathbb{R}×d_k}$,$W_iK∈mathbb{R}×d_k}$,$W_iV∈mathbb{R}×d_v}$)拆分为8个“子空间”(h=8,论文固定设置),每个子空间独立执行缩放点积注意力,得到8个$d_v$维的输出($d_v=64$),最后将8个输出拼接,通过一个线性投影$WO∈mathbb{R}{h d_v×d_{model}}$得到最终结果。参数约束:$h×d_k=d_{model}=512$,确保总计算量与“单头注意力($d_k=512$)”相当($O(n^2 d_{model})$),不增加额外计算负担。
通俗类比:多头注意力就像“8个不同的专家同时分析一句话”——有的专家专门关注“语法依赖”(比如“它”指代哪个名词),有的关注“语义关联”(比如“making”和“difficult”的因果关系),有的关注“逻辑连接”(比如“but”前后的转折)。最后把8个专家的分析结果整合,得到比单个专家更全面的理解。
论文实证支持:论文附录的注意力可视化(图3-5)显示,不同头确实学习到了不同依赖:比如某个头专门捕捉“making”与“more difficult”的长距离关联(完成“making...more difficult”短语),另两个头负责指代消解(“its”指向“Law”),验证了多头设计的有效性。
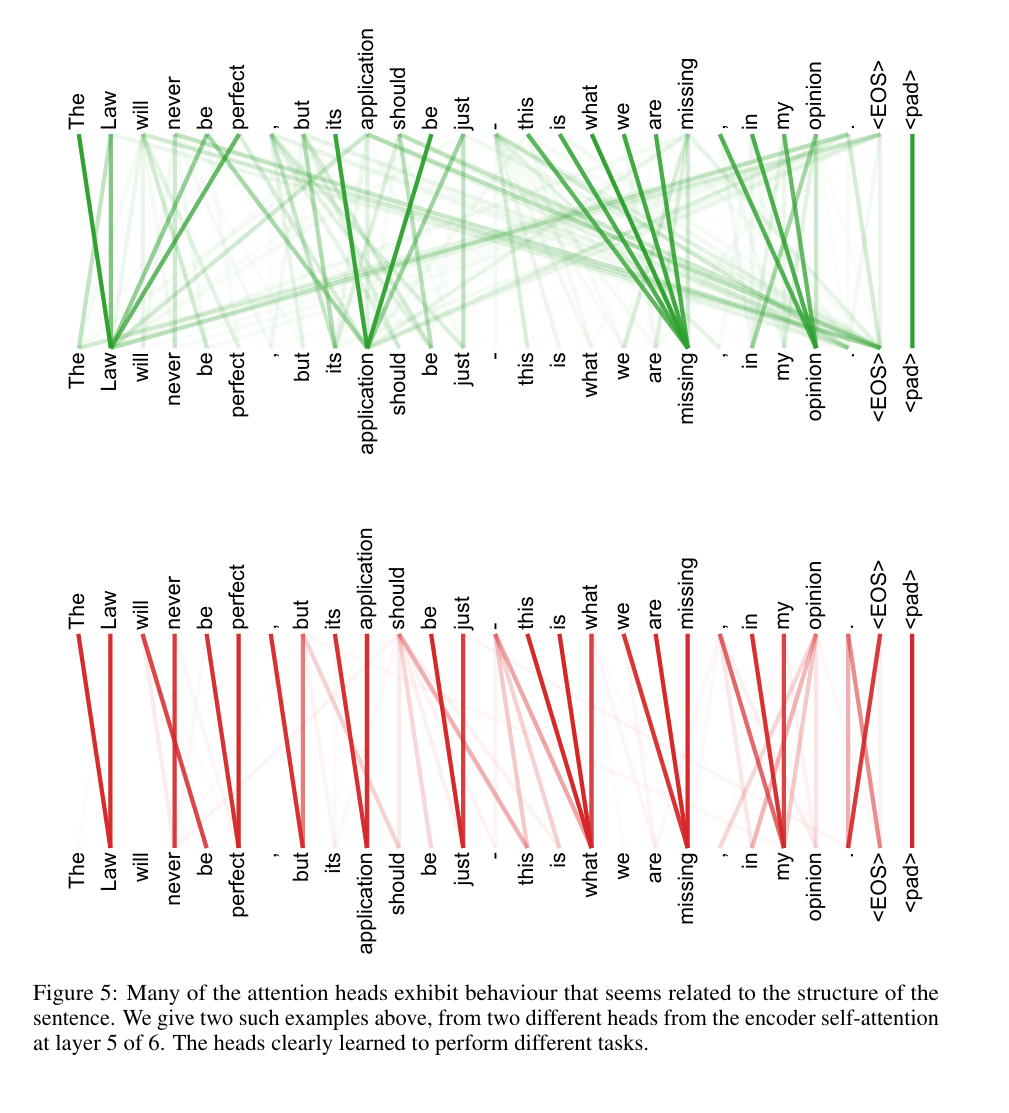
“许多注意力头表现出与句子结构相关的行为。我们在上面给出了两个这样的例子,它们来自 6 层编码器自注意力机制中第 5 层的两个不同注意力头。这些注意力头显然学会了执行不同的任务。”
论文节详细描述了架构细节,核心是“6层堆叠+残差连接+层归一化”,每个组件都有明确的设计目标,下面结合参数和原理双向解读:
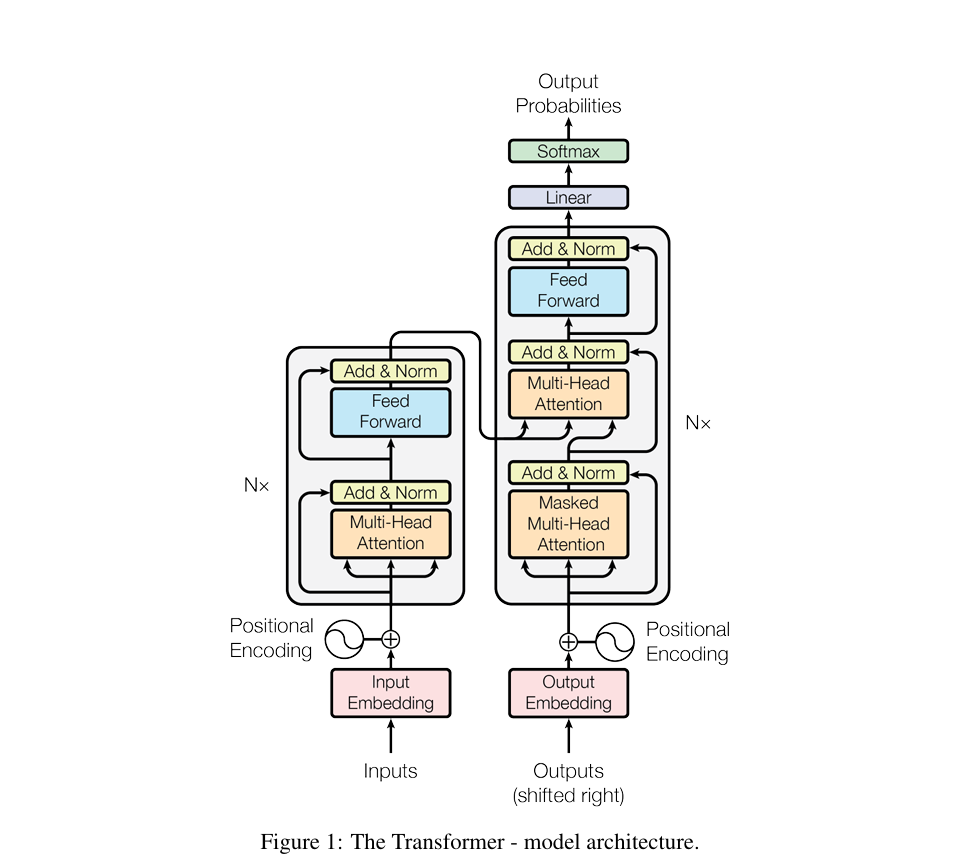
专业结构拆解:
通俗类比:编码器就像“阅读理解做题步骤”——
专业结构拆解:
通俗类比:解码器就像“写作文”——
专业解释:
通俗类比:位置编码就像“给排队的人贴编号”——每个token都有一个唯一的“位置标签”,标签的设计很巧妙:不仅能看出“谁在第1位、谁在第10位”(绝对位置),还能通过标签计算“两人之间差几个位置”(相对位置),而且不管队伍多长(序列多长),都能快速生成新的编号。
论文通过理论分析(表1)和实验结果(表2-4),论证了Transformer的三大优势,下面结合“专业数据+通俗解读”展开:

“表 1:不同层类型的最大路径长度、每层复杂度及最小顺序操作数注:n 为序列长度,d 为表示维度,k 为卷积核大小,r 为受限自注意力中的邻域大小”
专业分析(论文表1):
论文实验数据:Transformer(big)在8个P100 GPU上训练3.5天(300,000步),而之前的SOTA模型GNMT训练需1.1×10²¹ FLOPs(是Transformer的~48倍),却只达到41.16 BLEU,Transformer则达到41.8 BLEU。
通俗解读:
专业分析(论文表1“最大路径长度”):
论文实证支持:注意力可视化图3显示,编码器第5层的多个头能直接捕捉“making”(第8个token)与“difficult”(第14个token)的长距离关联,形成“making the registration process more difficult”的完整短语,而RNN需要逐次传递才能建立这种关联,容易丢失信息。
通俗解读:
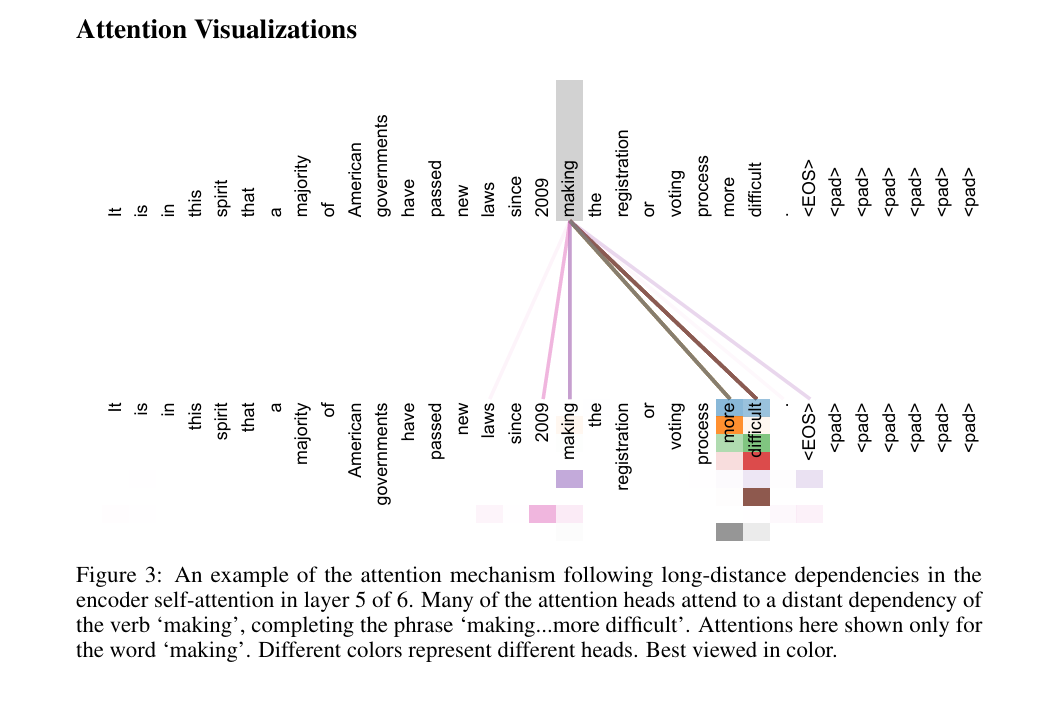
“图 3:6 层编码器自注意力中第 5 层的注意力机制捕捉长距离依赖的示例。许多注意力头会关注动词 “making” 的远距离依赖,以补全短语 “making...more difficult”。此处仅展示针对单词 “making” 的注意力情况。不同颜色代表不同的注意力头。建议以彩色查看。”
专业分析:
论文实验数据:表3显示,当$d_{model}=1024$、$d_{ff}=4096$时,模型的困惑度(PPL)从4.92降至4.33,BLEU从25.8提升到26.4,验证了规模扩展的有效性。
通俗解读:
$beta_2$接近1,说明对历史梯度平方的衰减较慢,适合稀疏梯度场景;“模型学习时既重视近期的梯度(当前数据的规律),也不忽视远期的梯度(之前数据的规律),避免学了新的忘了旧的”。
前4000步线性升温(warmup),避免初始学习率过大导致模型震荡;之后按步长的-0.5次方衰减,确保后期稳定收敛
降低模型对“正确标签”的过度自信,提升泛化性。
句法分析要求模型捕捉严格的结构依赖(如“定语从句修饰哪个名词”),且输出长度远大于输入(短语结构树的节点数是token数的2-3倍),Transformer能在该任务上取得好成绩,证明其注意力机制的“结构建模能力”,而非仅适用于翻译。Transformer不仅能“做好翻译”,还能“学好语法分析”,说明它掌握的是“语言的通用规律”,而非“翻译的专属技巧”,为后续迁移到文本生成、摘要、问答等任务奠定了基础。
《Attention Is All You Need》之所以成为AI工程领域的“里程碑”,不仅在于它解决了当时的技术瓶颈,更在于它为后续十年的AI发展奠定了基础:
如果说AI的发展是一条漫长的道路,那《Attention Is All You Need》就是这条路上的“关键路标”——它不仅回答了“如何高效处理文本”的问题,更开启了“用注意力机制构建智能系统”的全新思路。直到今天,这篇论文的思想仍在影响AI前沿研究(如视觉Transformer(ViT)、多模态Transformer),足以证明其不朽的价值。
对于想要深入AI领域的朋友,建议直接阅读论文原文(篇幅仅11页,逻辑清晰、公式简洁)——理解它,你就理解了现代大模型的“技术原点”。 论文链接如下 https://arxiv.org/abs/1706.03762

 登录查看全部
登录查看全部
参与评论
手机查看
返回顶部