首先看一下KL的基础公式
KL1:
大模型的KL一般是反向的:
(xsimpi_theta(cdot|o_{
KL3(GRPO使用的无偏,低方差KL1估计) http://joschu.net/blog/kl-approx.html:
[KL(pi_theta||pi_{ref}) = mathbb{E}_{xsimpi_theta(cdot|o_{ 因此,在大语言模型和生成任务中,反向KL通常更受青睐。 对于q的第(i)个sample的第(t)个token的loss: (loss_{i,t}=pg_loss_{i,t}+entropy_loss_{i, t}+kl_loss_{i,t}) 再对一个batch中所有的token loss (loss_{i,t})做聚合agg,得到这个batch的整体loss,可用于后续的反向传播和模型更新。 优化目标: [J = mathbb{E}_{osimpi_{old}}frac{1}{|o|}sum_{i=1}^{|o|} [min(frac{pi_{theta}(o_i|o_{ 优势: GAE [begin{aligned}
A_t &= (r_t+gamma V_{t+1}-V_t)+gamma A_{t+1}\
A_t &= sum_{i=t}^T gamma ^{i-t}(r_t+gamma V_{t+1}-V_t)\
A_t &= r_t+gamma r_{t+1}+gamma^2 r_{t+2}+...+gamma^{T-t}r_T-V_t\
end{aligned}
] 奖励: [r_t=begin{cases}-KL(pi_{old}||pi_{ref}), &tneq T \ -KL(pi_{old}||pi_{ref})+RM(q,o_i), &t=T end{cases}
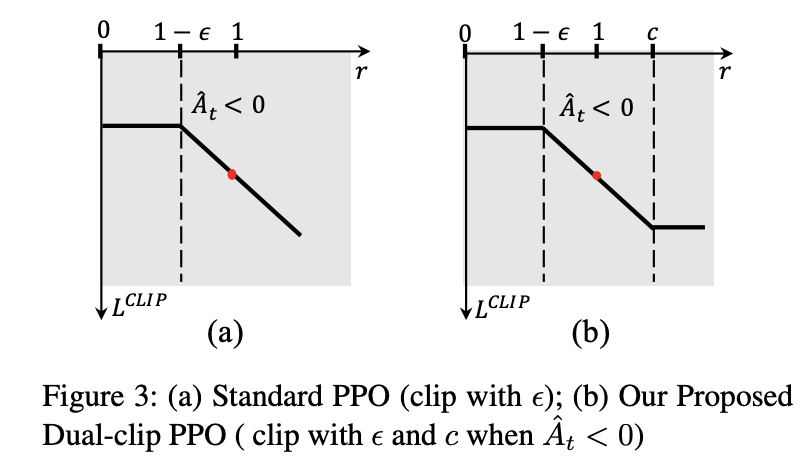
] KL [KL(pi_{old}||pi_{ref}) = log(frac{pi_{old}(o_t|q, o_{ PPO的KL散度是old到ref的 PPO的代码实现详见下面的Dual-clip PPO(PPO的改进版) https://arxiv.org/pdf/1912.09729:对A
论文发现当A是负无穷,这会导致训练不稳定(梯度爆炸)的现象,因此在ppo的clip上,对于A
[mathrm{per token objection} = begin{cases}
min(IS*A, clip(IS, 1-epsilon, 1+epsilon)*A), &Ageq0\
max(min(IS*A, clip(IS, 1-epsilon, 1+epsilon)*A), clip_ratio_c*A), &A 代码: 整体的ppo_loss是由pg_loss + kl_loss + entropy_loss构成,不同的RL方法pg_loss, kl_loss的计算方法是不同的。 咱们继续看几种token loss的agg mode。不同RL方法,loss agg mode也是不同的 优化目标: [J= mathbb{E}_{{o_i}_{i=1}^Gsimpi_{old}(cdot|q)} frac{1}{|G|} sum_{i=1}^{|G|}frac{1}{|o|}sum_{t=1}^{|o_i|}{min[frac{pi_{theta}(o_{i,t}|q, o_{i, 优势: [A_{i,t} = frac{r_i-mean(r)}{std(r)}
] KL3 [mathbb{D}_{KL}(pi_{theta}||pi_{ref}) =frac{pi_{ref}(o_{i, t}|q,o_{i, KL3的方差比KL1小,且是KL1的无偏估计 证明 [begin{aligned}
mathbb{D3}_{KL}(P||Q) &= sum_{xsim_{P}}P(x) [frac{Q(x)}{P(x)} - log(frac{P(x)}{Q(x)})-1]\
&= sum_{xsim P}Q(x)+P(x)log(frac{P(x)}{Q(x)})-P(x)\
&=sum_{xsim P}Q(x) -sum_{xsim P}P(x)+mathbb{D1}_{KL}(P||Q) \
&=mathbb{D1}_{KL}(P||Q)+sum_{xsim P}Q(x)-1 当P所有采样在Q中的概率和为1时(vocab一样的话)\
&=mathbb{D_1}_{KL}(P||Q)
end{aligned}
] seq-level 优化目标: [J= mathbb{E}_{{o_i}_{i=1}^Gsimpi_{old}(cdot|q)} frac{1}{|G|} sum_{i=1}^{|G|}min[(frac{pi_{theta}(o_{i}|q)}{pi_{old}(o_{i}|q)})^{frac{1}{|o_i|}}A_{i}, clip((frac{pi_{theta}(o_{i}|q)}{pi_{old}(o_{i}|q)})^{frac{1}{|o_i|}}, 1-epsilon, 1+epsilon)A_{i}]
] [frac{pi_{theta}(o_i|q)}{pi_{old}(o_i|q)} = frac{Pi_{t=1}^{|o_i|} pi_{theta}(o_{i,t}|q, o_{i, token-level 优化目标: [J = mathbb{E}_{{o_i}_{i=1}^Gsim pi_{old}(cdot|q)}frac{1}{G}sum_{i=1}^Gfrac{1}{|o_i|}sum_{t=1}^{|o_i|} min(s_{i,t}A_{i,t}, clip(s_{i,t}, 1-epsilon,1+epsilon)A_{i,t})\
hat{s}_{i,t} = sg[(frac{pi_{theta}(o_i|q)}{pi_{old}(o_i|q)})^{frac{1}{|o_i|}}]* frac{pi_{theta}(o_{i,t}|q,o_{i, 可以发现的是 (sg[s_{i,t}]=sg[s_{i}],s_{i}=(frac{pi_{theta}(o_i|q)}{pi_{old}(o_i|q)})^{frac{1}{|o_i|}}),但是在方向上不同 通过证明,可以发现,当(A_{i,t}=A_i)时,seq-level和token-level在前向传播和反向传播上是一样的 优化目标: [mathcal{J} = mathbb{E}_{(q,a)sim mathcal{D}, {o_i}_{i=1}^Gsim pi_{old}(cdot|q)} [frac{1}{sum_{i=1}^G|o_i|}sum_{i=1}^Gsum_{t=1}^{|o_i|}min(r_{i,t}(theta)A_{i, t}, clip(r_{i,t}(theta),1-epsilon_{low}, 1+epsilon_{high})A_{i,t})]\
s.t. 0 其中 [r_{i,t}(theta)=frac{pi_{theta}(o_{i,t}|q,o_{i, 其loss agg mode是token-mean。
不同RL算法 loss的计算
每个token的loss
(pg_loss_{i,t})
(kl_loss_{i,t})
loss agg mode
PPO
(max(IS_{i,t}*-A_{i,t},clip(IS_{i,t})*-A_{i,t}))
(r_t=-mathbb{D1}_{KL}(pi_{old}||pi_{ref})+r_t)
(frac{1}{G}sum_{i=1}^Gfrac{1}{|o_i|}sum_{t=1}^{|o_i|}loss_{i,t})
seq-mean-token-mean
Dual-clip PPO
for A(min(max(IS_{i,t}*-A_{i,t},clip(IS_{i,t})*-A), clip_c*-A))
(r_t=-mathbb{D1}_{KL}(pi_{old}||pi_{ref})+r_t)
(frac{1}{G}sum_{i=1}^Gfrac{1}{|o_i|}sum_{t=1}^{|o_i|}loss_{i,t})
seq-mean-token-mean
GRPO
(max(IS_{i,t}*-A_{i,t},clip(IS_{i,t})*-A_{i,t}))
(beta*mathbb{D3}_{KL}(pi_{theta}||pi_{ref}))
(frac{1}{G}sum_{i=1}^Gfrac{1}{|o_i|}sum_{t=1}^{|o_i|}loss_{i,t})
seq-mean-token-mean
GSPO
(IS_{i,t} = sg[frac{pi_{theta}(o_i|q)}{pi_{old}(o_i|q)}]*frac{pi_theta(o_{i,t}|q,o_{i,
(max(IS_{i,t}*-A_{i,t},clip(IS_{i,t})*-A_{i,t}))(beta*mathbb{D3}_{KL}(pi_{theta}||pi_{ref}))
(frac{1}{G}sum_{i=1}^Gfrac{1}{|o_i|}sum_{t=1}^{|o_i|}loss_{i,t})
seq-mean-token-mean
DAPO
(max(IS_{i,t}*-A_{i,t},clip(IS_{i,t})*-A_{i,t}))
(beta*mathbb{D3}_{KL}(pi_{theta}||pi_{ref}))
(frac{1}{sum_{i=1}^G|o_i|}sum_{i=1}^Gsum_{t=1}^{|o_i|}loss_{i,t})
token-meanPPO
递推公式,t步的累积优势=t步的优势+ t+1步的累积优势=t步及之后 每一步的优势=t步及之后所有的奖励-第t步的预计奖励verl/trainer/ppo/ray_trainer.py verl | 如何在奖励中添加KL惩罚项?###################################################
# 将KL惩罚loss应用到reward中。原始的reward是[0, 0, 0, ..., RM(q,o_i)]
# return KL(pi_old||pi_{ref}) + reward
###################################################
def apply_kl_penalty(data: DataProto, kl_ctrl: core_algos.AdaptiveKLController, kl_penalty="kl"):
"""Apply KL penalty to the token-level rewards.
This function computes the KL divergence between the reference policy and current policy,
then applies a penalty to the token-level rewards based on this divergence.
Args:
data (DataProto): The data containing batched model outputs and inputs.
kl_ctrl (core_algos.AdaptiveKLController): Controller for adaptive KL penalty.
kl_penalty (str, optional): Type of KL penalty to apply. Defaults to "kl".
Returns:
tuple: A tuple containing:
- The updated data with token-level rewards adjusted by KL penalty
- A dictionary of metrics related to the KL penalty
"""
response_mask = data.batch["response_mask"]
token_level_scores = data.batch["token_level_scores"]
batch_size = data.batch.batch_size[0]
# compute kl between ref_policy and current policy
# When apply_kl_penalty, algorithm.use_kl_in_reward=True, so the reference model has been enabled.
kld = core_algos.kl_penalty(
data.batch["old_log_probs"], data.batch["ref_log_prob"], kl_penalty=kl_penalty
) # (batch_size, response_length)
kld = kld * response_mask
beta = kl_ctrl.value
token_level_rewards = token_level_scores - beta * kld
Dual-clip PPO
verl/trainer/ppo/core_algos.py(我将在dual-clip ppo和gspo部分介绍对应的pg_loss代码)。verl/trainer/ppo/core_algos.py(我将会在grpo部分介绍具体的low_var_kl代码)。verl/verl/workers/roles/utils/losses.py: ppo_loss的计算######################################################
# 此函数用于计算整体的actor loss
######################################################
def ppo_loss(config: ActorConfig, model_output, data: TensorDict, dp_group=None):
log_prob = model_output["log_probs"]
entropy = model_output.get("entropy", None)
log_prob = no_padding_2_padding(log_prob, data) # (bsz, response_length)
if entropy is not None:
entropy = no_padding_2_padding(entropy, data) # (bsz, response_length)
metrics = {}
response_mask = data["response_mask"].to(bool)
# compute policy loss
old_log_prob = data["old_log_probs"]
advantages = data["advantages"]
loss_agg_mode = config.loss_agg_mode
loss_mode = config.policy_loss.get("loss_mode", "vanilla")
policy_loss_fn = get_policy_loss_fn(loss_mode)
# 调用下面的计算pg_loss的代码框
pg_loss, pg_clipfrac, ppo_kl, pg_clipfrac_lower = policy_loss_fn(
old_log_prob=old_log_prob,
log_prob=log_prob,
advantages=advantages,
response_mask=response_mask,
loss_agg_mode=loss_agg_mode,
config=config,
)
metrics.update(
{
"pg_loss": pg_loss.detach().item(),
"pg_clipfrac": pg_clipfrac.detach().item(),
"ppo_kl": ppo_kl.detach().item(),
"pg_clipfrac_lower": pg_clipfrac_lower.detach().item(),
}
)
policy_loss = pg_loss
# 是否使用entropy loss
# add entropy loss
if entropy is not None:
entropy_loss = agg_loss(loss_mat=entropy, loss_mask=response_mask, loss_agg_mode=loss_agg_mode)
entropy_coeff = config.entropy_coeff
# token的entropy越大越好,而loss是越小越好,因此是 减去 entropy
policy_loss -= entropy_coeff * entropy_loss
# 是否使用KL loss(grpo/gspo使用,ppo/dapo不使用)
# add kl loss
if config.use_kl_loss:
ref_log_prob = data["ref_log_prob"]
# compute kl loss
kld = kl_penalty(logprob=log_prob, ref_logprob=ref_log_prob, kl_penalty=config.kl_loss_type)
kl_loss = agg_loss(loss_mat=kld, loss_mask=response_mask, loss_agg_mode=config.loss_agg_mode)
policy_loss += kl_loss * config.kl_loss_coef
metrics["kl_loss"] = kl_loss.detach().item()
metrics["kl_coef"] = config.kl_loss_coef
return policy_loss, metrics
verl/trainer/ppo/core_algos.py不同的RL方法计算pg_loss是不同的,这里的是ppo的pg_loss,后面还会介绍gspo的pg_loss的实现。######################################################
# 此函数用于计算pg_loss,并不计算KL惩罚项
######################################################
@register_policy_loss("vanilla") # type: ignore[arg-type]
def compute_policy_loss_vanilla(
old_log_prob: torch.Tensor,
log_prob: torch.Tensor,
advantages: torch.Tensor,
response_mask: torch.Tensor,
loss_agg_mode: str = "token-mean",
config: Optional[DictConfig | AlgoConfig] = None,
rollout_is_weights: torch.Tensor | None = None,
) -> tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:
"""
Compute the clipped policy objective and related metrics for PPO.
Adapted from
https://github.com/huggingface/trl/blob/main/trl/trainer/ppo_trainer.py#L1122
Args:
old_log_prob (torch.Tensor):
Log-probabilities of actions under the old policy, shape (batch_size, response_length).
log_prob (torch.Tensor):
Log-probabilities of actions under the current policy, shape (batch_size, response_length).
advantages (torch.Tensor):
Advantage estimates for each action, shape (batch_size, response_length).
response_mask (torch.Tensor):
Mask indicating which tokens to include in the loss, shape (batch_size, response_length).
loss_agg_mode (str, optional):
Aggregation mode for `agg_loss`. Defaults to "token-mean".
config: `(verl.trainer.config.ActorConfig)`:
config for the actor.
rollout_log_probs: `(torch.Tensor)`:
log probabilities of actions under the rollout policy, shape (batch_size, response_length).
"""
assert config is not None
assert not isinstance(config, AlgoConfig)
clip_ratio = config.clip_ratio # Clipping parameter ε for standard PPO. See https://arxiv.org/abs/1707.06347.
clip_ratio_low = config.clip_ratio_low if config.clip_ratio_low is not None else clip_ratio
clip_ratio_high = config.clip_ratio_high if config.clip_ratio_high is not None else clip_ratio
clip_ratio_c = config.get( # Lower bound of the ratio for dual-clip PPO. See https://arxiv.org/pdf/1912.09729.
"clip_ratio_c", 3.0
)
cliprange = clip_ratio
cliprange_low = clip_ratio_low
cliprange_high = clip_ratio_high
assert clip_ratio_c > 1.0, (
"The lower bound of the clip_ratio_c for dual-clip PPO should be greater than 1.0,"
+ f" but get the value: {clip_ratio_c}."
)
# 计算每一个token的重要性采样的比值的log
# log(pi_{theta}(o_{i,t}|q,o_{i,verl/trainer/ppo/core_algos.pydef agg_loss(loss_mat: torch.Tensor, loss_mask: torch.Tensor, loss_agg_mode: str):
"""
Aggregate the loss matrix into a scalar.
Args:
loss_mat: `(torch.Tensor)`:
shape: (bs, response_length)
loss_mask: `(torch.Tensor)`:
shape: (bs, response_length)
loss_agg_mode: (str) choices:
method to aggregate the loss matrix into a scalar.
Returns:
loss: `a scalar torch.Tensor`
aggregated loss
"""
if loss_agg_mode == "token-mean":
loss = verl_F.masked_mean(loss_mat, loss_mask)
elif loss_agg_mode == "seq-mean-token-sum":
seq_losses = torch.sum(loss_mat * loss_mask, dim=-1) # token-sum
loss = torch.mean(seq_losses) # seq-mean
elif loss_agg_mode == "seq-mean-token-mean":
seq_losses = torch.sum(loss_mat * loss_mask, dim=-1) / torch.sum(loss_mask, dim=-1) # token-mean
loss = torch.mean(seq_losses) # seq-mean
elif loss_agg_mode == "seq-mean-token-sum-norm":
seq_losses = torch.sum(loss_mat * loss_mask, dim=-1)
loss = torch.sum(seq_losses) / loss_mask.shape[-1] # The divisor
# (loss_mask.shape[-1]) should ideally be constant
# throughout training to well-replicate the DrGRPO paper.
# TODO: Perhaps add user-defined normalizer argument to
# agg_loss to ensure divisor stays constant throughout.
else:
raise ValueError(f"Invalid loss_agg_mode: {loss_agg_mode}")
return loss
GRPO
verl/trainer/ppo/core_algos.py 下面是verl对kl_loss的实现:def kl_penalty_forward(logprob: torch.FloatTensor, ref_logprob: torch.FloatTensor, kl_penalty) -> torch.FloatTensor:
"""Compute KL divergence given logprob and ref_logprob.
Copied from https://github.com/huggingface/trl/blob/main/trl/trainer/ppo_trainer.py#L1104
See more description in http://joschu.net/blog/kl-approx.html
Args:
logprob:
ref_logprob:
Returns:
kl_estimate
"""
if kl_penalty in ("kl", "k1"):
return logprob - ref_logprob
if kl_penalty == "abs":
return (logprob - ref_logprob).abs()
if kl_penalty in ("mse", "k2"):
return 0.5 * (logprob - ref_logprob).square()
##############################################################
# 这里的low_var_kl与上述的grpo的KL计算公式相同
##############################################################
# J. Schulman. Approximating kl divergence, 2020.
# # URL http://joschu.net/blog/kl-approx.html.
if kl_penalty in ("low_var_kl", "k3"):
kl = ref_logprob - logprob
# For numerical stability
kl = torch.clamp(kl, min=-20, max=20)
ratio = torch.exp(kl)
kld = (ratio - kl - 1).contiguous()
return torch.clamp(kld, min=-10, max=10)
if kl_penalty == "full":
# so, here logprob and ref_logprob should contain the logits for every token in vocabulary
raise NotImplementedError
raise NotImplementedError
GSPO
token-level 可以更好地扩展 同sample不同token的A的灵活度(每个token的A可以不相同)verl/trainer/ppo/core_algos.py##########################################################
# 计算gspo的pg_loss,重点关注IS的计算
##########################################################
@register_policy_loss("gspo")
def compute_policy_loss_gspo(
old_log_prob: torch.Tensor,
log_prob: torch.Tensor,
advantages: torch.Tensor,
response_mask: torch.Tensor,
loss_agg_mode: str = "seq-mean-token-mean",
config: Optional[DictConfig | ActorConfig] = None,
rollout_is_weights: torch.Tensor | None = None,
) -> tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:
"""
Compute the clipped policy objective and related metrics for GSPO.
See https://arxiv.org/pdf/2507.18071 for more details.
Args:
old_log_prob (torch.Tensor):
Log-probabilities of actions under the old policy, shape (batch_size, response_length).
log_prob (torch.Tensor):
Log-probabilities of actions under the current policy, shape (batch_size, response_length).
advantages (torch.Tensor):
Advantage estimates for each action, shape (batch_size, response_length).
response_mask (torch.Tensor):
Mask indicating which tokens to include in the loss, shape (batch_size, response_length).
loss_agg_mode (str, optional):
Aggregation mode for `agg_loss`. For GSPO, it is recommended to use "seq-mean-token-mean".
"""
assert config is not None
assert isinstance(config, ActorConfig)
clip_ratio_low = config.clip_ratio_low if config.clip_ratio_low is not None else config.clip_ratio
clip_ratio_high = config.clip_ratio_high if config.clip_ratio_high is not None else config.clip_ratio
negative_approx_kl = log_prob - old_log_prob
# compute sequence-level importance ratio:
# si(θ) = (π_θ(yi|x)/π_θold(yi|x))^(1/|yi|) =
# exp [(1/|y_i|) * Σ_t log(π_θ(y_i,t|x,y_i,DAPO
 登录查看全部
登录查看全部
参与评论
手机查看
返回顶部