| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 120 | 100 |
| · Estimate | · 估计这个任务需要多少时间 | 480 | 600 |
| Development | 开发 | 180 | 240 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 240 |
| · Design Spec | · 生成设计文档 | 60 | 50 |
| · Design Review | · 设计复审 | 30 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 10 |
| · Design | · 具体设计 | 90 | 120 |
| · Coding | · 具体编码 | 40 | 40 |
| · Code Review | · 代码复审 | 30 | 40 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 210 |
| Reporting | 报告 | 30 | 50 |
| · Test Repor | · 测试报告 | 20 | 15 |
| · Size Measurement | · 计算工作量 | 20 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 35 |
| · 合计 | 480 | 600 |
本文使用SimHash和海明距离计算文章重复率,原理参考自:https://blog.csdn.net/wxgxgp/article/details/104106867
在分词与权重计算部分参考自jieba库的Github:https://github.com/fxsjy/jieba
stopWords = [' ', '!', ',', '.', '?', '!', '?', ',', '。', 'n', 't', 'b', '"', '“', '”', ':', '《', '》', '']
splitWords = jieba.lcut(source)
splitWords = del_stopWords(splitWords, stopWords)
#删除停用词
def del_stopWords(split_sentence, stopWords):
i = 0
while (len(split_sentence) != 0):
if (i >= len(split_sentence)):
break
#匹配停用词
tmp = False
for n in stopWords:
if (split_sentence[i] == n):
tmp = True
break
if (tmp):
split_sentence.pop(i)
continue
i += 1
return split_sentence
# 哈希函数,输入单个分词
def string_hash(source):
if source == "":
return 0
else:
x = ord(source[0]) #合并加权后的哈希值,输入加权哈希值列表
def mergeHash(list_weightPluse):
mergeHash_list = [0] * 64
for index in range(len(list_weightPluse)):
mergeHash_list = np.add(mergeHash_list, list_weightPluse[index])
return mergeHash_list
#降维,大于0的输出1,小于等于0的输出0
def reduction(mergeHash_list):
reduction_list = list()
for index in range(len(mergeHash_list)):
if (mergeHash_list[index] > 0):
reduction_list.append(1)
else:
reduction_list.append(0)
return reduction_list
#海明距离
def getDistance(list_1, list_2):
distance = 0
for index in range(len(list_1)):
if (list_1[index] ^ list_2[index] == 1):
distance += 1
return distance
#将汉明距离转换为相似度
similarity = round((64 - hanmingDistance) / 64 * 100, 2)
address_orig = sys.argv[1]
address_copy = sys.argv[2]
address_out = sys.argv[3]
#读入并计算源文件的simhash
file_1 = open(address_orig, encoding= 'UTF-8')
s1 = file_1.read()
list_1 = simhash(s1, stopWords)
#print(list_1)
file_1.close()
#将相似度写入新建文件
file_3 = open(address_out, 'w', encoding= 'UTF-8')
file_3.write(str(similarity))
file_3.close()
尝试输出结果
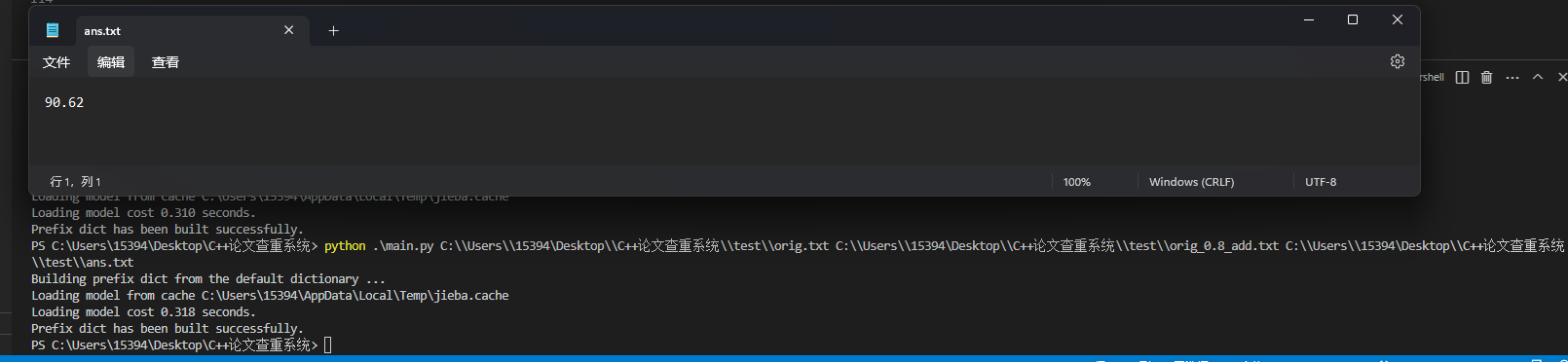
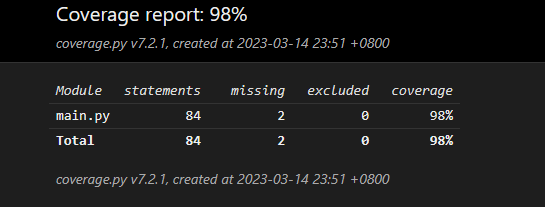
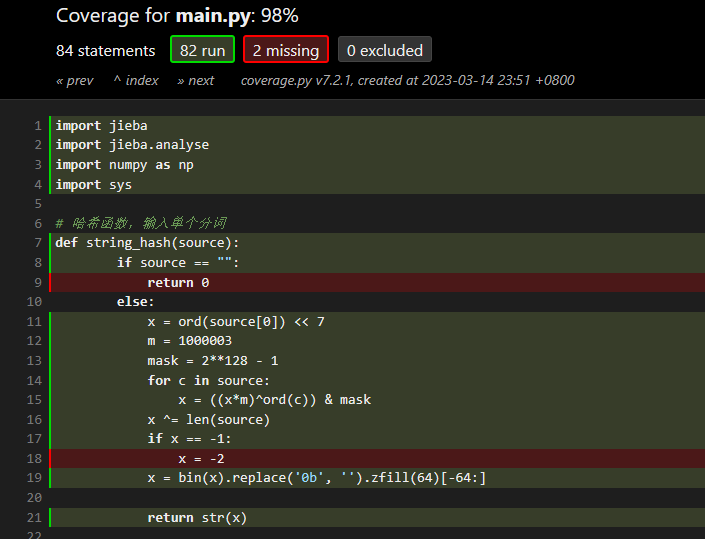
因为分词的准确性直接关系到最后输出结果过的准确性,所以这次我主要测试分词功能是否完善
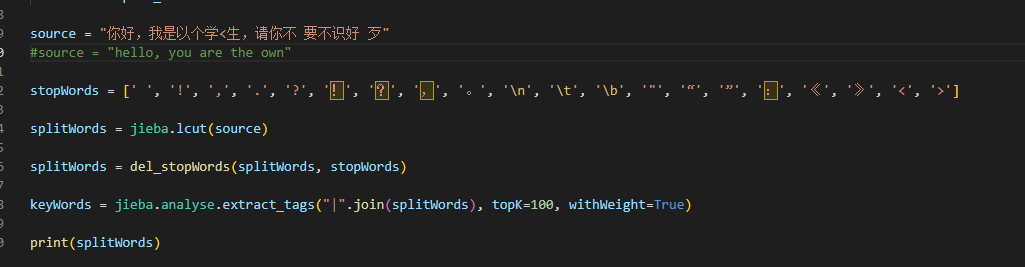

可见,当完整的词语被空格或者其它符号打断时,jieba库似乎不能很好的检测出来,如果是一些比较重要的词出现增删改的情况,很有可能会影响相似度的计算。
如果考虑在分词前将停用词去除,如果处理的文章里有英文,则会导致单词粘连的情况而无法正确识别英文单词。
也许有更好的方法解决这个问题,比如区分各种情况,再根据不同情况用不同的方法去除干扰词。
 登录查看全部
登录查看全部
参与评论
手机查看
返回顶部