在第3章中概述了内核提供的一些顶级磁盘设备。本章将详细讨论如何在Linux系统中使用磁盘。你将学习如何对磁盘进行分区、创建和维护磁盘分区中的文件系统,以及如何使用交换空间。
磁盘设备的名称如/dev/sda,即第一个SCSI子系统磁盘。这种块设备代表整个磁盘,但磁盘内部有许多不同的组件和层。
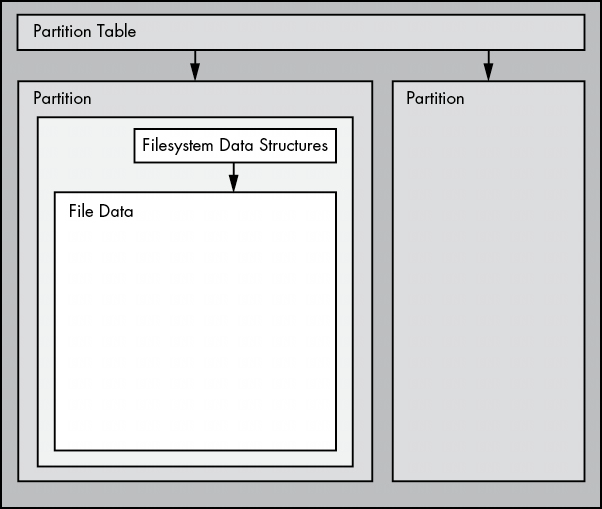
图4-1展示了简单 Linux 磁盘的示意图(注意,该图未按比例绘制)。通过本章的学习,你将了解每个部件的位置。
分区是整个磁盘的细分。在Linux中,它们在整个块设备后面用数字表示,因此它们的名称是/dev/sda1和/dev/sdb3。内核会将每个分区显示为一个块设备,就像显示整个磁盘一样。分区定义在磁盘的一小块区域上,称为分区表(也称为磁盘标签)。
在大型磁盘系统中,多个数据分区曾经很常见,因为老式PC只能从磁盘的某些部分启动。此外,管理员还使用分区为操作系统区域保留一定的空间;例如,他们不希望用户将整个系统占满,导致关键服务无法运行。这种做法并非Unix独有,你仍然会发现许多新的Windows系统在单个磁盘上设置了多个分区。此外,大多数系统都有单独的交换分区。
内核允许你同时访问整个磁盘和其中的一个分区,但除非你要复制整个磁盘,否则通常不会这样做。
Linux逻辑卷管理器(LVM Logical Volume Manager)为传统的磁盘设备和分区增加了更多灵活性,目前已在许多系统中使用。我们将在第4.4节介绍LVM。
分区的下一层是文件系统,也就是用户空间中常用的文件和目录数据库。我们将在第4.2节探讨文件系统。
如图4-1所示,如果要访问文件中的数据,需要使用分区表中相应的分区位置,然后在该分区的文件系统数据库中搜索所需的文件数据。
要访问磁盘上的数据,Linux内核使用图4-2所示的分层系统。SCSI子系统和第3.6节中描述的所有其他系统都用一个方框表示。请注意,你可以通过文件系统或直接通过磁盘设备来处理磁盘。本章将介绍这两种方法的工作原理。为了简化操作,图4-2中没有显示 LVM,但它在块设备接口中包含一些组件,在用户空间中包含一些管理组件。
要了解一切是如何组合在一起的,让我们从最底层的分区开始。
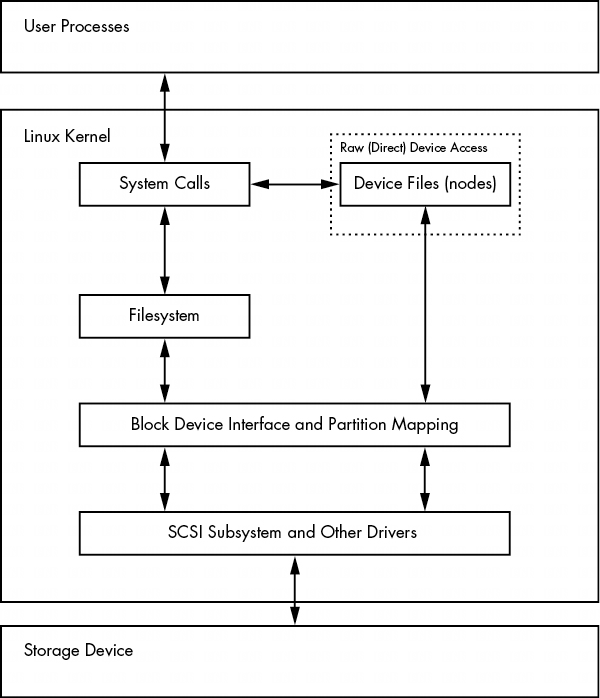
图 4-2: 用于磁盘访问的内核示意图
分区表有很多种。分区表并没有什么特别之处--它只是一堆说明磁盘块划分方式的数据。
传统的分区表可追溯到PC时代,是主引导记录 (MBR Master Boot Record) 中的分区表,它有很多局限性。大多数较新的系统使用全局唯一标识符分区表(GPT Globally Unique Identifier Partition Table GUID 分区表)。
下面介绍几种Linux分区工具:
由于fdisk已经支持MBR和GPT有一段时间了,而且运行单一命令即可轻松获取分区标签,因此我们将使用parted来显示分区表。不过,在创建和更改分区表时,我们将使用fdisk。这将说明这两种界面,以及为什么许多人更喜欢fdisk界面,因为它具有交互性,而且在你查看之前,它不会对磁盘进行任何更改(我们稍后将讨论这一点)。
注意:分区操作和文件系统操作之间有一个重要区别:分区表定义了磁盘上的简单边界,而文件系统是一个涉及面更广的数据系统。因此,我们将使用不同的工具来分区和创建文件系统(参见第 4.2.2 节)。
可以使用parted -l查看系统的分区表。此示例输出显示了两个磁盘设备的两种不同分区表:
# parted -l
Model: ATA KINGSTON SM2280S (scsi)
1 Disk /dev/sda: 240GB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 1049kB 223GB 223GB primary ext4 boot
2 223GB 240GB 17.0GB extended
5 223GB 240GB 17.0GB logical linux-swap(v1)
Model: Generic Flash Disk (scsi)
2 Disk /dev/sdf: 4284MB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
1 1049kB 1050MB 1049MB myfirst
2 1050MB 4284MB 3235MB mysecond
第一个设备(/dev/sda)使用传统的MBR分区表(parted将其称为msdos),第二个设备(/dev/sdf)包含 GPT。请注意,这两种表类型存储了不同的参数集。特别是MBR表没有 Namecolumn,因为在该方案下不存在名称。(我在 GPT 中随意选择了 myfirst 和 mysecond 这两个名称)。
注意:读取分区表时要注意单位大小。parted的输出会根据parted认为最容易读取的单位显示近似大小。另一方面,fdisk -l显示的是精确数字,但在大多数情况下,单位是512字节的"扇区",这可能会造成混淆,因为看起来你的磁盘和分区的实际大小是原来的两倍。仔细查看fdisk分区表视图也会发现扇区大小信息。
本例中的MBR表包含主分区、扩展分区和逻辑分区。主分区是对磁盘的正常细分,分区1就是一个例子。基本MBR有四个主分区的限制,因此如果想要超过四个,就必须指定一个作为扩展分区。扩展分区可细分为逻辑分区,操作系统可以像使用其他分区一样使用这些逻辑分区。在本例中,分区2是包含逻辑分区5的扩展分区。
注意:分区列出的文件系统类型不一定与MBR条目中的系统ID字段相同。MBR系统ID只是一个标识分区类型的数字;例如83是Linux分区,82是Linux交换分区。不过,parted 会自行判断该分区上的文件系统类型,从而提供更多信息。如果一定要知道MBR的系统ID,请使用 fdisk -l。
查看分区表时,如果看到标有LVM(Logical Volume Manager)的分区(分区类型代码为8e)、名为/dev/dm-*的设备或"设备映射器"的引用,则说明系统使用了LVM。我们将从传统的直接磁盘分区开始讨论,它与使用LVM的系统上的分区略有不同。
为了让大家心中有数,让我们快速浏览一下使用LVM的系统(在VirtualBox上使用LVM新安装的Ubuntu)的 parted -l 输出示例。首先是实际分区表的描述,除了lvm 标志外,它看起来与你想象的基本一致:
Model: ATA VBOX HARDDISK (scsi)
Disk /dev/sda: 10.7GB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 1049kB 10.7GB 10.7GB primary boot, lvm
还有一些设备看起来应该是分区,但却被称为磁盘:
Model: Linux device-mapper (linear) (dm)
Disk /dev/mapper/ubuntu--vg-swap_1: 1023MB
Sector size (logical/physical): 512B/512B
Partition Table: loop
Disk Flags:
Number Start End Size File system Flags
1 0.00B 1023MB 1023MB linux-swap(v1)
Model: Linux device-mapper (linear) (dm)
Disk /dev/mapper/ubuntu--vg-root: 9672MB
Sector size (logical/physical): 512B/512B
Partition Table: loop
Disk Flags:
Number Start End Size File system Flags
1 0.00B 9672MB 9672MB ext4
简单的理解方式是,分区已经以某种方式从分区表中分离出来。你将在第 4.4 节看到实际情况。
注意使用fdisk -l,你将获得更少的详细输出;在前一种情况下,除了一个LVM标签的物理分区外,你将看不到其他任何东西。
初始内核读取:初始读取MBR表时,Linux内核会产生如下调试输出(记住,可以用journalctl -k查看):
sda: sda1 sda2
输出中的 sda2 部分表明 /dev/sda2 是一个扩展分区,包含一个逻辑分区 /dev/sda5。你通常会忽略扩展分区本身,因为你通常只关心访问它所包含的逻辑分区。
查看分区表是一项相对简单且无害的操作。更改分区表也相对简单,但对磁盘进行此类更改存在风险。请牢记以下几点:
准备就绪后,选择分区程序。如果你想使用 parted,可以使用命令行 parted 实用程序或图形界面,如 gparted;fdisk 在命令行下相当容易操作。这些实用程序都有在线帮助,很容易上手。(如果没有备用磁盘,可以尝试在闪存设备或类似设备上使用它们)。
不过,fdisk 和 parted 的工作方式有很大不同。使用 fdisk,你可以在对磁盘进行实际更改之前设计新的分区表,而且只有在你退出程序时才会进行更改。但使用 parted 时,分区会在你发出命令时创建、修改和删除。在更改之前,你没有机会查看分区表。
这些差异也是理解这两个工具如何与内核交互的关键。fdisk 和 parted 都完全在用户空间修改分区;不需要内核支持重写分区表,因为用户空间可以读取和修改所有块设备。
但在某些时候,内核必须读取分区表,以便将分区显示为块设备,从而可以使用它们。fdisk 实用程序使用一种相对简单的方法。在修改分区表后,fdisk 会发出一个系统调用,告诉内核应该重新读取磁盘的分区表(你很快就会看到如何与 fdisk 交互的示例)。然后内核会生成调试输出,你可以用 journalctl -k 查看。例如,如果在 /dev/sdf 上创建了两个分区,就会看到下面的内容:
sdf: sdf1 sdf2
分区工具不使用这种全磁盘系统调用,而是在改变单个分区时向内核发出信号。处理单个分区更改后,内核不会产生前面的调试输出。
有几种方法可以查看分区变化:
如果绝对必须确认对分区表的修改,可以使用 blockdev 命令来执行 fdisk 发出的旧式系统调用。例如,要强制内核重新加载 /dev/sdf 上的分区表,请执行以下命令:
# blockdev --rereadpt /dev/sdf
让我们在新的空磁盘上创建一个新的分区表,将刚才学到的知识运用到实际操作中。本示例显示以下情况:
4GB 磁盘(未使用的小型 USB 闪存设备;如果您想效仿本示例,请使用手头任何大小的设备), MBR类型的分区表。打算用 ext4填充的两个分区:200MB 和 3.8GB。磁盘设备位于/dev/sdd;你需要用 lsblk 查找自己的设备位置。
你将使用 fdisk 来完成这项工作。请注意,这是一个交互式命令,因此在确保磁盘上没有任何东西被挂载后,你将在命令提示符下输入设备名称:
# fdisk /dev/sdd
Command (m for help):
Command (m for help): p
Disk /dev/sdd: 4 GiB, 4284481536 bytes, 8368128 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x88f290cc
Device Boot Start End Sectors Size Id Type
/dev/sdd1 2048 8368127 8366080 4G c W95 FAT32 (LBA)
大多数设备已经包含一个FAT类型的分区,如/dev/sdd1中的这个分区。因为你想为Linux创建新的分区(当然,你肯定不需要这里的任何东西),你可以像这样删除现有的分区:
Command (m for help): d
Selected partition 1
Partition 1 has been deleted.
在你明确写入分区表之前,fdisk 不会进行更改,因此你还没有修改磁盘。如果你犯了无法挽回的错误,使用 q 命令退出 fdisk,而不写入更改。现在使用 n 命令创建第一个 200MB 分区:
Command (m for help): n
Partition type
p primary (0 primary, 0 extended, 4 free)
e extended (container for logical partitions)
Select (default p): p
Partition number (1-4, default 1): 1
First sector (2048-8368127, default 2048): 2048
Last sector, +sectors or +size{K,M,G,T,P} (2048-8368127, default 8368127): +200M
Created a new partition 1 of type 'Linux' and of size 200 MiB.
在这里,fdisk 会提示你选择 MBR 分区样式、分区编号、分区起始和结束(或大小)。默认值通常就是你想要的。这里唯一改变的是分区结束/大小,使用 + 语法指定大小和单位。
创建第二个分区的方法与此相同,但您将使用所有默认值,因此我们不再赘述。完成分区布局后,使用 p(打印)命令查看:
Command (m for help): p
[--snip--]
Device Boot Start End Sectors Size Id Type
/dev/sdd1 2048 411647 409600 200M 83 Linux
/dev/sdd2 411648 8368127 7956480 3.8G 83 Linux
Command (m for help): w
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.
如果你对其他诊断信息感兴趣,可以使用 journalctl -k 查看前面提到的内核读取信息,但要记住,只有使用 fdisk 时才能看到这些信息。
至此,你已经掌握了开始分区磁盘的所有基础知识,但如果你想了解有关磁盘的更多细节,请继续阅读。否则,请跳至第 4.2 节,了解如何在磁盘上安装文件系统。
任何带有移动部件的设备都会给软件系统带来复杂性,因为有些物理元素是无法抽象的。硬盘也不例外;尽管可以将硬盘视为可随机访问任意块的块设备,但如果系统不注意如何在磁盘上布局数据,就会对性能造成严重影响。
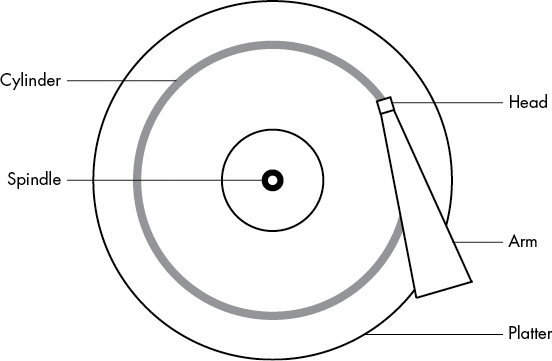
磁盘由主轴上的旋转盘片和连接到移动臂上的磁头组成,移动臂可横扫磁盘的半径。磁盘在磁头下方旋转时,磁头读取数据。当臂处于一个位置时,磁头只能从一个固定的圆读取数据。这个圆被称为圆柱体,因为较大的磁盘有多个盘片,所有盘片都堆叠在一起,围绕同一主轴旋转。每个盘片可以有一个或两个磁头,分别位于盘片的顶部和/或底部,所有磁头都连接在同一个臂上,并协同移动。由于磁臂会移动,因此磁盘上会有许多圆柱体,从围绕中心的小圆柱体到围绕磁盘外围的大圆柱体。最后,还可以将圆柱体划分为称为扇区的片段。这种考虑磁盘几何形状的方法称为 CHS,即圆柱体-磁头-扇区;在较早的系统中,只要使用这三个参数寻址,就能找到磁盘的任何部分。
注意:磁道是单个磁头访问的圆柱体部分,因此在图4-3中,圆柱体也是一个磁道。你不需要担心磁道。
内核和各种分区程序可以告诉你磁盘报告的磁道数。不过,在任何半路出家的新硬盘上,报告的数值都是虚构的!使用 CHS 的传统寻址方案无法与现代磁盘硬件相匹配,也无法解释外层磁盘比内层磁盘能容纳更多数据的事实。磁盘硬件支持逻辑块寻址 (LBA),通过块编号来寻址磁盘上的位置(这是一个更直接的接口),但 CHS 的残余仍然存在。例如,MBR 分区表包含 CHS 信息和 LBA 等价物,一些引导加载程序仍然愚蠢地相信 CHS 值(别担心,大多数 Linux 引导加载程序使用 LBA 值)。
注意:扇区一词容易引起混淆,因为 Linux 分区程序可能用它表示不同的值。
柱面的概念曾经对分区至关重要,因为柱面是分区的理想边界。从圆柱体读取数据流的速度非常快,因为磁头可以在磁盘旋转时不断拾取数据。由一组相邻的磁盘分区组成的分区也可以实现快速的连续数据访问,因为磁头不需要在磁盘分区之间移动太远。
虽然磁盘的外观与以往大致相同,但精确分区对齐的概念已经过时。一些旧的分区程序会抱怨,如果你不把分区精确地放在磁盘分区边界上。请忽略这一点;你能做的不多,因为现代磁盘报告的 CHS 值并不真实。磁盘的 LBA 方案以及较新的分区实用程序中更好的逻辑可确保分区以合理的方式布局。
固态磁盘(SSD)等无移动部件的存储设备在访问特性方面与旋转磁盘截然不同。
对它们来说,随机存取不是问题,因为没有磁头在盘片上扫描,但某些特性会改变固态硬盘的性能。
影响固态硬盘性能的最重要因素之一是分区对齐。从固态硬盘读取数据时,数据是以块(称为页,不要与虚拟内存页混淆)为单位读取的,例如每次读取 4,096 或 8,192 字节,而且读取必须以该大小的倍数开始。这意味着,如果你的分区及其数据不在一个边界上,你可能需要进行两次读取,而不是进行一次小的普通操作,比如读取一个目录的内容。较新版本的分区工具包含将新创建分区置于磁盘开头适当偏移位置的逻辑,因此你可能不需要担心分区对齐不当的问题。目前的分区工具不做任何计算,而只是将分区对齐到 1MB 边界上,或者更准确地说,对齐到 2,048 个 512 字节的块上。这是一种相当保守的方法,因为边界对齐的页面大小为 4,096、8,192 等,一直到 1,048,576。
不过,如果你好奇或想确保你的分区从边界开始,你可以很容易地在 /sys/block 目录中找到这些信息。下面是分区 /dev/sdf2 的示例:
$ cat /sys/block/sdf/sdf2/start
1953126
这里的输出是分区从设备起点开始的偏移量,单位为 512 字节(Linux 系统又把它称为扇区,令人困惑)。如果该固态硬盘使用 4,096 字节的页面,那么一个页面中有 8 个这样的扇区。你所要做的就是看看能否将分区偏移量平均除以 8。在这种情况下,你做不到,所以分区无法达到最佳性能。
内核与磁盘的用户空间之间的最后一环通常是文件系统;这就是你在运行 ls 和 cd 等命令时习惯与之交互的系统。如前所述,文件系统是一种数据库形式;它提供了一种结构,将简单的块设备转变为用户可以理解的复杂的文件和子目录层次结构。
曾几何时,所有文件系统都存在于专门用于数据存储的磁盘和其他物理介质中。不过,文件系统的树状目录结构和 I/O 接口非常灵活,因此文件系统现在可以执行多种任务,例如你在 /sys 和 /proc 中看到的系统接口。文件系统传统上是在内核中实现的,但 Plan 9 的 9P 创新(https://en.wikipedia.org/wiki/9P_(protocol))激发了用户空间文件系统的发展。用户空间文件系统(FUSE)功能允许在 Linux 中使用用户空间文件系统。
虚拟文件系统(VFS)抽象层完善了文件系统的实现。正如 SCSI 子系统将不同设备类型和内核控制命令之间的通信标准化一样,VFS 确保所有文件系统实现都支持标准接口,以便用户空间应用程序以相同的方式访问文件和目录。对 VFS 的支持使 Linux 能够支持大量的文件系统。
Linux 文件系统支持包括为 Linux 优化的本地设计、外来类型(如 Windows FAT 系列)、通用文件系统(如 ISO 9660)以及许多其他类型。下面列出了最常见的数据存储文件系统类型。Linux 识别的类型名称在文件系统名称旁边的括号中。
第四扩展文件系统(ext4)是 Linux 原生文件系统的最新版本。第二扩展文件系统(ext2)是 Linux 系统长期以来的默认设置,其灵感来源于传统的 Unix 文件系统,如 Unix 文件系统(UFS)和快速文件系统(FFS)。第三扩展文件系统(ext3)增加了日志功能(正常文件系统数据结构之外的小型缓存),以增强数据完整性并加快启动速度。ext4 文件系统是一种渐进式改进,支持比 ext2 或 ext3 更大的文件以及更多的子目录。
扩展文件系统系列具有一定的向后兼容性。例如,你可以将 ext2 和 ext3 文件系统相互挂载,也可以将 ext2 和 ext3 文件系统挂载为 ext4,但不能将 ext4 挂载为 ext2 或 ext3。
Btrfs或B树文件系统(btrfs)是Linux原生的一种较新的文件系统,其扩展能力超过了ext4。
FAT文件系统(msdos、vfat、exfat)与微软系统有关。
简单的msdos 类型支持 MS-DOS 系统中非常原始的单例。大多数可移动闪存介质(如 SD 卡和 USB 驱动器)默认包含 vfat(最大 4GB)或 exfat(4GB 及以上)分区。Windows 系统可以使用基于 FAT 的文件系统或更先进的 NT 文件系统(ntfs)。
XFS 是一种高性能文件系统,某些发行版(如 Red Hat Enterprise Linux 7.0 及更高版本)默认使用 XFS。
HFS+ (hfsplus) 是大多数 Macintosh 系统使用的苹果标准。
ISO 9660 (iso9660) 是一种光盘标准。大多数光盘都使用某种不同的 ISO 9660 标准。
长期以来,扩展文件系统系列完全可以为大多数用户所接受,而且它一直是事实上的标准,这不仅证明了它的实用性,也证明了它的适应性。Linux 开发社区倾向于完全替换不能满足当前需求的组件,但每次 Extended 文件系统出现问题时,都会有人对其进行升级。尽管如此,文件系统技术还是取得了许多进步,而由于向后兼容性的要求,即使是 ext4 也无法利用这些进步。这些进步主要体现在与大量文件、大文件和类似情况有关的可扩展性增强方面。
在撰写本文时,Btrfs 已成为一个主要 Linux 发行版的默认设置。如果这证明是成功的,那么 Btrfs 很可能会取代 Extended 系列。
如果你正在准备一个新的存储设备,一旦完成了第 4.1 节所述的分区过程,就可以创建文件系统了。与分区一样,创建文件系统也要在用户空间进行,因为用户空间进程可以直接访问和操作块设备。
mkfs实用程序可以创建多种文件系统。例如,你可以用这条命令在/dev/sdf2上创建一个ext4 分区:
# mkfs -t ext4 /dev/sdf2
mkfs 程序会自动确定设备中的块数,并设置一些合理的默认值。除非你真的知道自己在做什么,并想详细阅读文档,否则不要更改它们。
创建文件系统时,mkfs 会在运行过程中打印诊断输出,包括与超级块相关的输出。超级块是文件系统数据库顶层的关键组件,它非常重要,因此 mkfs 会创建大量备份,以防原始数据被破坏。考虑在运行 mkfs 时记录一些超级块的备份编号,以防磁盘发生故障时需要恢复超级块(参见第 4.2.11 节)。
创建文件系统只能在添加新磁盘或重新分区旧磁盘后进行。对于每个没有预先存在的数据(或有要删除的数据)的新分区,只需创建一次文件系统。在现有文件系统上创建新文件系统会有效地破坏旧数据。
原来,mkfs 只是一系列文件系统创建程序 mkfs.fs 的前端,其中 fs 是一种文件系统类型。因此,当你运行 mkfs -t ext4 时,mkfs 会反过来运行 mkfs.ext4。
还有更多的间接操作。检查命令后面的 mkfs.* 文件,你会看到下面的内容:
$ ls -l /sbin/mkfs.*
-rwxr-xr-x 1 root root 18592 Apr 9 23:32 /sbin/mkfs.bfs
-rwxr-xr-x 1 root root 482248 Feb 25 2022 /sbin/mkfs.btrfs
-rwxr-xr-x 1 root root 26728 Apr 9 23:32 /sbin/mkfs.cramfs
lrwxrwxrwx 1 root root 6 Jun 2 2022 /sbin/mkfs.ext2 -> mke2fs
lrwxrwxrwx 1 root root 6 Jun 2 2022 /sbin/mkfs.ext3 -> mke2fs
lrwxrwxrwx 1 root root 6 Jun 2 2022 /sbin/mkfs.ext4 -> mke2fs
-rwxr-xr-x 1 root root 47704 Mar 23 2022 /sbin/mkfs.fat
-rwxr-xr-x 1 root root 39088 Apr 9 23:32 /sbin/mkfs.minix
lrwxrwxrwx 1 root root 8 Mar 23 2022 /sbin/mkfs.msdos -> mkfs.fat
lrwxrwxrwx 1 root root 6 Nov 1 2022 /sbin/mkfs.ntfs -> mkntfs
lrwxrwxrwx 1 root root 8 Mar 23 2022 /sbin/mkfs.vfat -> mkfs.fat
-rwxr-xr-x 1 root root 371016 Feb 9 2022 /sbin/mkfs.xfs
正如你所见,mkfs.ext4 只是 mke2fs 的一个符号链接。如果你遇到的系统没有特定的 mkfs 命令,或者在查找特定文件系统的文档时,记住这一点很重要。每个文件系统的创建工具都有自己的手册页面,比如 mke2fs(8)。这在大多数系统上都不成问题,因为访问 mkfs.ext4(8) 手册页面会跳转到 mke2fs(8) 手册页面,但请记住这一点。
在Unix中,将文件系统附加到运行系统的过程称为挂载。系统启动时,内核会读取一些配置数据,并根据配置数据挂载 root (/)。
要挂载文件系统,必须了解以下信息:
挂载文件系统的常用术语是 “在挂载点上挂载设备”。要了解系统当前的文件系统状态,可以运行 mount。输出结果(可能很长)应该是这样的:
$ mount
sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime)
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
udev on /dev type devtmpfs (rw,nosuid,relatime,size=131517904k,nr_inodes=32879476,mode=755,inode64)
devpts on /dev/pts type devpts (rw,nosuid,noexec,relatime,gid=5,mode=620,ptmxmode=000)
tmpfs on /run type tmpfs (rw,nosuid,nodev,noexec,relatime,size=26318024k,mode=755,inode64)
efivarfs on /sys/firmware/efi/efivars type efivarfs (rw,nosuid,nodev,noexec,relatime)
/dev/mapper/ubuntu--vg-ubuntu--lv on / type ext4 (rw,relatime,stripe=16)
securityfs on /sys/kernel/security type securityfs (rw,nosuid,nodev,noexec,relatime)
tmpfs on /dev/shm type tmpfs (rw,nosuid,nodev,inode64)
tmpfs on /run/lock type tmpfs (rw,nosuid,nodev,noexec,relatime,size=5120k,inode64)
cgroup2 on /sys/fs/cgroup type cgroup2 (rw,nosuid,nodev,noexec,relatime,nsdelegate,memory_recursiveprot)
pstore on /sys/fs/pstore type pstore (rw,nosuid,nodev,noexec,relatime)
bpf on /sys/fs/bpf type bpf (rw,nosuid,nodev,noexec,relatime,mode=700)
systemd-1 on /proc/sys/fs/binfmt_misc type autofs (rw,relatime,fd=29,pgrp=1,timeout=0,minproto=5,maxproto=5,direct,pipe_ino=111116)
hugetlbfs on /dev/hugepages type hugetlbfs (rw,relatime,pagesize=2M)
mqueue on /dev/mqueue type mqueue (rw,nosuid,nodev,noexec,relatime)
debugfs on /sys/kernel/debug type debugfs (rw,nosuid,nodev,noexec,relatime)
tracefs on /sys/kernel/tracing type tracefs (rw,nosuid,nodev,noexec,relatime)
fusectl on /sys/fs/fuse/connections type fusectl (rw,nosuid,nodev,noexec,relatime)
configfs on /sys/kernel/config type configfs (rw,nosuid,nodev,noexec,relatime)
none on /run/credentials/systemd-sysusers.service type ramfs (ro,nosuid,nodev,noexec,relatime,mode=700)
tmpfs on /run/qemu type tmpfs (rw,nosuid,nodev,relatime,mode=755,inode64)
/var/lib/snapd/snaps/core20_2267.snap on /snap/core20/2267 type squashfs (ro,nodev,relatime,errors=continue,x-gdu.hide)
/var/lib/snapd/snaps/core20_2321.snap on /snap/core20/2321 type squashfs (ro,nodev,relatime,errors=continue,x-gdu.hide)
/var/lib/snapd/snaps/lxd_27950.snap on /snap/lxd/27950 type squashfs (ro,nodev,relatime,errors=continue,x-gdu.hide)
/var/lib/snapd/snaps/lxd_28384.snap on /snap/lxd/28384 type squashfs (ro,nodev,relatime,errors=continue,x-gdu.hide)
/var/lib/snapd/snaps/snapd_21467.snap on /snap/snapd/21467 type squashfs (ro,nodev,relatime,errors=continue,x-gdu.hide)
/dev/sda2 on /boot type ext4 (rw,relatime,stripe=16)
/dev/sda1 on /boot/efi type vfat (rw,relatime,fmask=0022,dmask=0022,codepage=437,iocharset=iso8859-1,shortname=mixed,errors=remount-ro)
binfmt_misc on /proc/sys/fs/binfmt_misc type binfmt_misc (rw,nosuid,nodev,noexec,relatime)
tmpfs on /run/snapd/ns type tmpfs (rw,nosuid,nodev,noexec,relatime,size=26318024k,mode=755,inode64)
nsfs on /run/snapd/ns/lxd.mnt type nsfs (rw)
tmpfs on /run/user/0 type tmpfs (rw,nosuid,nodev,relatime,size=26318020k,nr_inodes=6579505,mode=700,inode64)
/var/lib/snapd/snaps/snapd_21761.snap on /snap/snapd/21761 type squashfs (ro,nodev,relatime,errors=continue,x-gdu.hide)
tracefs on /sys/kernel/debug/tracing type tracefs (rw,nosuid,nodev,noexec,relatime)
/var/lib/snapd/snaps/core_17201.snap on /snap/core/17201 type squashfs (ro,nodev,relatime,errors=continue,x-gdu.hide)
/var/lib/snapd/snaps/unixbench_27.snap on /snap/unixbench/27 type squashfs (ro,nodev,relatime,errors=continue,x-gdu.hide)
每一行对应一个当前已挂载的文件系统,项目按以下顺序排列:
要手动挂载文件系统,请使用如下挂载命令,并输入文件系统类型、设备和所需的挂载点:
# mount -t type device mountpoint
例如,要挂载在 /home/extra 上设备 /dev/sdf2 上的第四扩展文件系统,请使用此命令:
# mount -t ext4 /dev/sdf2 /home/extra
通常情况下,你不需要提供 -t 类型选项,因为 mount 通常会为你计算出来。不过,有时有必要区分两种相似的类型,例如各种 FAT 类型的文件系统。
要卸载(分离)文件系统,请使用如下 umount 命令:
# umount mountpoint
也可以使用文件系统的设备而不是挂载点卸载文件系统。
几乎所有 Linux 系统都包含一个临时挂载点 /mnt,通常用于测试。在试验系统时可以随意使用它,但如果你打算长期挂载文件系统,请寻找或制作另一个挂载点。
上一节讨论的挂载文件系统的方法取决于设备名称。然而,设备名称可能会改变,因为它们取决于内核查找设备的顺序。为了解决这个问题,你可以通过通用唯一标识符(UUID)来识别和挂载文件系统,UUID 是识别计算机系统中对象的唯一 “序列号 ”的行业标准。像 mke2fs 这样的文件系统创建程序会在初始化文件系统数据结构时生成一个 UUID。
要查看设备列表以及系统中相应的文件系统和 UUID,请使用 blkid(块 ID)程序:
# blkid
/dev/mapper/ubuntu--vg-ubuntu--lv: UUID="175bf7f1-cbce-408e-9acc-960ae03c2346" BLOCK_SIZE="4096" TYPE="ext4"
/dev/sda2: UUID="31ee66ca-70e9-469c-958c-c78a9c51443b" BLOCK_SIZE="4096" TYPE="ext4" PARTUUID="2dafe15f-abd2-4d2e-80a6-8afa7913253a"
/dev/sda3: UUID="405c0N-VEVy-eIe5-0Rj5-m9dm-FIAU-NBed6S" TYPE="LVM2_member" PARTUUID="a82236e6-bd79-4ae4-bdde-714db1a4d406"
/dev/sda1: UUID="28B0-F691" BLOCK_SIZE="512" TYPE="vfat" PARTUUID="3f328243-1a89-4b61-a0cb-acf6071f5e36"
/dev/loop1: TYPE="squashfs"
/dev/loop6: TYPE="squashfs"
/dev/loop4: TYPE="squashfs"
/dev/loop2: TYPE="squashfs"
/dev/loop0: TYPE="squashfs"
/dev/loop7: TYPE="squashfs"
/dev/loop5: TYPE="squashfs"
/dev/loop3: TYPE="squashfs"
在本例中,blkid 发现了四个带有数据的分区:两个带有 ext4 文件系统,一个带有交换空间签名(见第 4.3 节),一个带有基于 FAT 的文件系统。Linux 本地分区都有标准 UUID,但 FAT 分区没有。你可以用 FAT 卷序号(本例中为 4859-EFEA)来引用 FAT 分区。
要通过 UUID 挂载文件系统,请使用 UUID 挂载选项。例如,要将前面列表中的第一个文件系统挂载到 /home/extra 上,请输入
# mount UUID=b600fe63-d2e9-461c-a5cd-d3b373a5e1d2 /home/extra
通常情况下,你不会像这样通过 UUID 手动挂载文件系统,因为你通常知道设备,而且通过设备名挂载比通过疯狂的 UUID 要容易得多。不过,了解 UUID 还是很重要的。首先,UUID 是启动时在 /etc/fstab 中自动挂载非 LVM 文件系统的首选方式(参见第 4.2.8 节)。此外,许多发行版会在插入可移动媒体时使用 UUID 作为挂载点。在上例中,FAT 文件系统位于闪存卡上。有人登录的 Ubuntu 系统会在插入时将该分区挂载到 /media/user/4859-EFEA。第 3 章所述的 udevd 守护进程会处理设备插入的初始事件。
如有必要,你可以更改文件系统的 UUID(例如,如果你从其他地方复制了完整的文件系统,现在需要将其与原始文件系统区分开来)。有关如何在 ext2/ext3/ext4 文件系统上执行此操作,请参阅 tune2fs(8) 手册。
与其他 Unix 变种一样,Linux 也会对写入磁盘的数据进行缓冲。这意味着当进程请求更改时,内核通常不会立即将更改写入文件系统。相反,它会将这些更改存储在 RAM 中,直到内核确定将它们实际写入磁盘的好时机。这种缓冲系统对用户是透明的,并能带来非常显著的性能提升。
使用umount卸载文件系统时,内核会自动与磁盘同步,将缓冲区中的更改写入磁盘。你也可以在任何时候通过运行 sync 命令强制内核这样做,该命令默认情况下会同步系统中的所有磁盘。如果由于某些原因无法在关闭系统前卸载文件系统,请务必先运行同步。
此外,内核使用 RAM 来缓存从磁盘读取的数据块。因此,如果一个或多个进程重复访问一个文件,内核不必一次又一次地访问磁盘,只需从缓存中读取即可,从而节省了时间和资源。
改变挂载命令行为的方法有很多,在处理可移动媒体或执行系统维护时,你经常需要这样做。事实上,mount 选项的总数是惊人的。内容丰富的 mount(8) 手册页面是一个很好的参考,但很难知道从哪里开始,哪些可以安全地忽略。本节将介绍最有用的选项。
选项大致分为两类:常规选项和文件系统特定选项。一般选项通常适用于所有文件系统类型,包括用于指定文件系统类型的 -t,如前所述。相比之下,文件系统专用选项只适用于特定的文件系统类型。
要激活文件系统选项,请使用 -o 开关,后面跟上选项。例如,-o remount,rw 会将已挂载为只读的文件系统重新挂载为读写模式。
常规选项的语法很简短。最重要的有
-r -r 选项以只读模式挂载文件系统。这有很多用途,从写保护到引导。访问只读设备(如 CD-ROM)时不需要指定该选项,系统会帮你完成(还会告诉你只读状态)。
-n -n 选项确保 mount 不会尝试更新系统运行时挂载数据库 /etc/mtab。默认情况下,mount 操作在无法写入该文件时会失败,因此该选项在启动时非常重要,因为根分区(包括系统挂载数据库)一开始是只读的。在单用户模式下尝试修复系统问题时,你也会发现这个选项很方便,因为系统挂载数据库当时可能不可用。
-t 类型选项指定文件系统类型。
长选项
对于不断增加的挂载选项来说,像 -r 这样的短选项过于有限;字母表中的字母太少,无法容纳所有可能的选项。短选项也很麻烦,因为很难根据单个字母确定选项的含义。许多常规选项和所有文件系统特定选项都使用更长、更灵活的选项格式。
要在命令行中使用挂载长选项,以 -o 开头,后面用逗号分隔相应的关键字。下面是一个完整的示例,长选项位于 -o 之后:
# mount -t vfat /dev/sde1 /dos -o ro,uid=1000
这里的两个长选项是ro和uid=1000。ro选项指定只读模式,与-r短选项相同。uid=1000选项告诉内核将文件系统中的所有文件视作所有者为用户 ID 1000。
最有用的长选项是
有时需要更改当前已挂载文件系统的挂载选项;最常见的情况是需要在崩溃恢复期间使只读文件系统可写。在这种情况下,你需要在同一挂载点重新挂载文件系统。
以下命令以读写模式重新挂载根目录(需要使用 -n 选项,因为当根目录为只读时,挂载命令无法写入系统挂载数据库):
# mount -n -o remount /
该命令假定 /etc/fstab 中有正确的 / 设备列表(如下一节所述)。如果没有,则必须作为附加选项指定设备。
为了在启动时挂载文件系统并省去挂载命令的繁琐工作,Linux 系统在 /etc/fstab 中保存了文件系统和选项的永久列表。这是一个格式非常简单的纯文本文件,如清单 4-1 所示。
UUID=70ccd6e7-6ae6-44f6-812c-51aab8036d29 / ext4 errors=remount-ro 0 1
UUID=592dcfd1-58da-4769-9ea8-5f412a896980 none swap sw 0 0
/dev/sr0 /cdrom iso9660 ro,user,nosuid,noauto 0 0
每行对应一个文件系统,分为六个字段。这些字段从左到右依次为
使用mount时,如果要处理的文件系统位于/etc/fstab 中,则可以采取一些快捷方式。例如,如果使用清单 4-1 挂载CD-ROM,只需运行 mount /cdrom。
你也可以尝试用这条命令同时挂载 /etc/fstab 中不包含 noauto 选项的所有条目:
# mount -a
清单 4-1 引入了一些新选项,即 errors、noauto 和 user,因为它们不适用于 /etc/fstab 文件之外。此外,你还会经常在这里看到 defaults 选项。这些选项的定义如下:
虽然 /etc/fstab 文件是表示文件系统及其挂载点的传统方法,但也有两种替代方法。第一种是 /etc/fstab.d,它包含单独的文件系统配置文件(每个文件系统一个文件)。这种思路与本书中的许多其他配置目录非常相似。
第二种方法是为文件系统配置 systemd 单元。有关 systemd 及其单元的更多信息,请参见第 6 章。不过,systemd 单元配置通常由 /etc/fstab 文件生成(或基于 /etc/fstab 文件),因此在你的系统中可能会发现一些重叠。
要查看当前挂载文件系统的大小和使用情况,请使用 df 命令。输出可能非常广泛(而且由于文件系统的专业化,输出会越来越长),但其中应包括实际存储设备的信息。
$ df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/sda1 214234312 127989560 75339204 63% /
/dev/sdd2 3043836 4632 2864872 1% /media/user/uuid
如果无法在df输出中找到与特定目录对应的正确行,请运行df dir命令,其中dir是要检查的目录。这会将输出限制在该目录的文件系统中。一个非常常用的命令是df .,它将输出限制在保存当前目录的设备上。
不难看出,这里的两个文件系统的大小分别为 215GB 和 3GB。不过,容量数字看起来可能有点奇怪,因为 127,989,560 加上 75,339,204 不等于 214,234,312 ,而 127,989,560 也不是 214,234,312 的 63%。在这两种情况下,总容量的 5% 都没有计算在内。事实上,这些空间是存在的,只是隐藏在预留块中。当文件系统开始填满时,只有超级用户才能使用预留块。这项功能可以防止系统服务器在磁盘空间耗尽时立即瘫痪。
如果你的磁盘已满,需要知道那些占用空间的媒体文件都在哪里,可以使用 du 命令。在没有参数的情况下,du 会从当前工作目录开始,打印目录层次结构中每个目录的磁盘使用情况。(这可能是一个很长的列表;如果你想看一个例子,只需运行 cd /; du 即可。无聊时按 CTRL-C)。du -s 命令打开摘要模式,只打印总计。要评估特定目录中的所有内容(文件和子目录),请切换到该目录并运行 du -s *,注意可能有一些点目录是该命令无法捕捉到的。
POSIX 标准定义块大小为 512 字节。不过,这种大小较难读取,因此大多数 Linux 发行版的 df 和 du 输出默认为 1,024 字节的块。如果坚持以 512 字节块显示数字,请设置 POSIXLY_CORRECT 环境变量。要明确指定 1,024 字节的数据块,请使用 -k 选项(这两个工具都支持)。df 和 du 程序还有一个 -m 选项,用于列出以 1MB 块为单位的容量,以及一个 -h 选项,用于根据文件系统的总体大小,猜测最容易被人读取的容量。
Unix文件系统提供的优化功能得益于复杂的数据库机制。要使文件系统无缝运行,内核必须相信挂载的文件系统没有错误,并且硬件能可靠地存储数据。如果存在错误,可能会导致数据丢失和系统崩溃。
除了硬件问题,文件系统错误通常是由于用户以粗鲁的方式关闭系统(例如拔掉电源线)造成的。在这种情况下,内存中以前的文件系统缓存可能与磁盘上的数据不匹配,当你碰巧踢了电脑一脚时,系统也可能正在更改文件系统。虽然许多文件系统都支持日志,使文件系统损坏的发生率大大降低,但你始终应该正确关闭系统。无论使用哪种文件系统,都有必要不时检查文件系统,以确保一切正常。
检查文件系统的工具是 fsck。与 mkfs 程序一样,Linux 支持的每种文件系统类型都有不同版本的 fsck。例如,在扩展文件系统系列(ext2/ext3/ext4)上运行时,fsck 会识别文件系统类型并启动 e2fsck 工具。因此,除非 fsck 无法识别文件系统类型或你正在查找 e2fsck 手册页面,否则一般不需要键入 e2fsck。
本节介绍的信息专门针对扩展文件系统系列和 e2fsck。
要在交互式手动模式下运行 fsck,请将设备或挂载点(如 /etc/fstab 中所列)作为参数。例如
# fsck /dev/sdb1
切勿在已挂载的文件系统上使用 fsck--内核可能会在运行检查时更改磁盘数据,导致运行时不匹配,从而使系统崩溃并损坏文件。只有一个例外:如果在单用户模式下只读挂载根分区,则可以使用 fsck。
在手动模式下,fsck 会在通过时打印详细的状态报告,如果没有问题,报告应该如下所示:
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
/dev/sdb1: 11/1976 files (0.0% non-contiguous), 265/7891 blocks
如果 fsck 在手动模式下发现问题,它会停止并提出与解决问题相关的问题。这些问题涉及文件系统的内部结构,例如重新连接松散的 inodes 和清除块(inodes 是文件系统的构建块;你将在第 4.6 节中看到它们是如何工作的)。当 fsck 要求你重新连接一个 inode 时,它发现了一个似乎没有名称的文件。重新连接此类文件时,fsck 会将文件放到文件系统中的 lost+found 目录中,并用数字作为文件名。如果出现这种情况,你需要根据文件内容猜测文件名;原始文件名很可能已经不存在了。
一般来说,如果你刚刚不干净地关闭了系统,那么就没有必要继续等待 fsck 修复过程了,因为 fsck 可能有很多小错误需要修复。幸运的是,e2fsck 有一个 -p 选项,它可以在不询问的情况下自动修复普通问题,并在出现严重错误时中止。事实上,Linux 发行版都会在启动时运行 fsck -p 的变种。(你可能还会看到 fsck -a,它也做同样的事情)。
如果你怀疑你的系统发生了重大灾难,比如硬件故障或设备配置错误,你需要决定采取什么行动,因为 fsck 真的会把有更大问题的文件系统搞得一团糟。(如果 fsck 在手动模式下提出很多问题,这就是系统出现严重问题的一个信号)。
如果你认为发生了非常糟糕的事情,可以尝试运行 fsck -n 来检查文件系统,但不要修改任何内容。如果设备配置中存在你认为可以修复的问题(如线缆松动或分区表中的块数不正确),请在真正运行 fsck 之前修复,否则很可能丢失大量数据。
如果你怀疑只有超级块损坏了(例如,因为有人写入了磁盘分区的开头),你也许可以用 mkfs 创建的超级块备份之一来恢复文件系统。使用 fsck -b num 将已损坏的超级块替换为区块编号为 num 的备用块,并期待最好的结果。
如果不知道在哪里可以找到备份超级块,可以在设备上运行 mkfs -n 查看超级块备份编号列表,而不会破坏数据。(再次提醒,确保使用 -n,否则会破坏文件系统)。
通常不需要手动检查 ext3 和 ext4 文件系统,因为日志可以确保数据完整性(请记住,日志是一个尚未写入文件系统特定位置的小型数据缓存)。如果你没有干净利落地关闭系统,就会发现日志中包含一些数据。要将 ext3 或 ext4 文件系统中的日志刷新为常规文件系统数据库,请按以下步骤运行 e2fsck:
# e2fsck -fy /dev/disk_device
不过,你可能希望在 ext2 模式下挂载已损坏的 ext3 或 ext4 文件系统,因为内核不会挂载日志不为空的 ext3 或 ext4 文件系统。
磁盘问题更严重时,你的选择就更少了:
在前两种情况下,你仍然需要在挂载前修复文件系统,除非你想手动拾取原始数据。如果你愿意,可以输入 fsck -y,选择对所有 fsck 问题的回答都是 “y”,但这是不得已而为之,因为在修复过程中可能会出现你更愿意手动处理的问题。
debugfs 工具允许你查看文件系统中的文件,并将它们复制到其他地方。默认情况下,它以只读模式打开文件系统。如果你正在恢复数据,保持文件完好无损可能是个好主意,以免把事情搞得一团糟。
现在,如果你真的走投无路了--比如磁盘发生了灾难性故障而又没有备份--除了希望专业服务能 “刮掉盘片 ”之外,你能做的并不多。
并非所有文件系统都代表物理介质上的存储。大多数 Unix 版本都有作为系统接口的文件系统。也就是说,文件系统不仅是在设备上存储数据的工具,还能代表系统信息,如进程 ID 和内核诊断。这个想法可以追溯到 /dev 机制,它是使用文件作为 I/O 接口的早期模型。/proc 的想法来源于第八版的研究型 Unix,由 Tom J. Killian 实现,并在贝尔实验室(包括许多最初的 Unix 设计者)创建 Plan 9 时得到加速--Plan 9 是一个将文件系统抽象提升到全新水平的研究型操作系统 (https://en.wikipedia.org/wiki/Plan_9_from_Bell_Labs)。
Linux 上常用的一些特殊文件系统类型包括
磁盘上并非每个分区都包含文件系统。也可以用磁盘空间来增加机器上的内存。如果实际内存不足,Linux 虚拟内存系统会自动将内存碎片移入或移出磁盘存储空间。这就是所谓的 “交换”(swapping),因为闲置程序的片段会被交换到磁盘上,以换取磁盘上的活动片段。用于存储内存页的磁盘区域称为交换空间(或简称交换)。
free 命令的输出包括以千字节为单位的当前交换使用情况,如下所示:
$ free
total used free
--snip--
Swap: 514072 189804 324268
要将整个磁盘分区用作交换空间,请按以下步骤操作:
创建交换分区后,你可以在/etc/fstab文件中加入一个新的交换条目,让系统在机器启动后立即使用交换空间。下面是一个使用 /dev/sda5 作为交换分区的示例条目:
/dev/sda5 none swap sw 0 0
交换签名有 UUID,因此请记住,现在许多系统都使用 UUID 代替原始设备名。
如果被迫重新分区磁盘以创建交换分区,你可以使用普通文件作为交换空间。这样做不会有任何问题。
使用以下命令创建一个空文件,将其初始化为交换文件,并将其添加到交换池中:
# dd if=/dev/zero of=swap_file bs=1024k count=num_mb
# mkswap swap_file
# swapon swap_file
这里,swap_file 是新交换文件的名称,num_mb 是所需大小(以兆字节为单位)。
要从内核的活动池中删除交换分区或文件,请使用 swapoff 命令。系统必须有足够的剩余内存(实际内存和交换内存的总和)来容纳要移除的交换池中的任何活动页面。
曾几何时,Unix 的传统智慧认为,你应该保留至少两倍于实际内存的交换空间。如今,不仅巨大的磁盘和内存容量给这个问题蒙上了阴影,我们使用系统的方式也发生了变化。一方面,磁盘空间如此充裕,分配超过两倍的内存空间很有诱惑力。另一方面,由于实际内存太大,你可能根本用不上交换空间。
双倍实际内存 "规则源于多用户登录一台机器的时代。但并不是所有用户都处于活动状态,因此,当活动用户需要更多内存时,可以交换掉非活动用户的内存,这样就很方便了。
对于单用户机器来说,这一点可能仍然适用。如果你正在运行许多进程,交换掉非活动进程的部分内存,甚至是活动进程的非活动内存,一般都不会有问题。但是,如果你经常访问交换空间,因为许多活动进程都想同时使用内存,你就会遇到严重的性能问题,因为磁盘 I/O(即使是固态硬盘)太慢了,跟不上系统其他部分的速度。唯一的解决办法就是购买更多内存、终止某些进程或抱怨。
有时,Linux 内核可能会选择交换进程,以获得更多的磁盘缓存。为了防止这种行为,一些管理员会将某些系统配置为完全没有交换空间。例如,高性能服务器绝不应占用交换空间,并应尽可能避免磁盘访问。
在通用机器上配置无交换空间是很危险的。如果机器的实际内存和交换空间都完全耗尽,Linux 内核会调用内存不足(OOM)杀手杀死一个进程,以释放一些内存。你显然不希望这种情况发生在桌面应用程序上。另一方面,高性能服务器包括复杂的监控、冗余和负载平衡系统,以确保它们永远不会到达危险区域。
第 8 章将详细介绍内存系统的工作原理。
到目前为止,我们已经通过分区了解了磁盘的直接管理和使用,指定了存储设备上某些数据的确切位置。我们知道,访问像 /dev/sda1 这样的块设备时,会根据 /dev/sda 上的分区表找到特定设备上的某个位置,即使具体位置可能由硬件决定。
这种方法通常效果不错,但也有一些缺点,尤其是在安装后对磁盘进行更改时。例如,如果要升级磁盘,就必须安装新磁盘、分区、添加文件系统,可能还要更改引导加载器和执行其他任务,最后才能切换到新磁盘。这个过程很容易出错,而且需要多次重启。当你想安装额外的磁盘以获得更大的容量时,情况可能更糟--在这种情况下,你必须为该磁盘上的文件系统选择一个新的挂载点,并希望能在新旧磁盘之间手动分配数据。
LVM 通过在物理块设备和文件系统之间添加另一层来解决这些问题。其原理是,选择一组物理卷(通常只是块设备,如磁盘分区),将其纳入一个卷组,作为一种通用数据池。然后再从卷组中划分出逻辑卷。
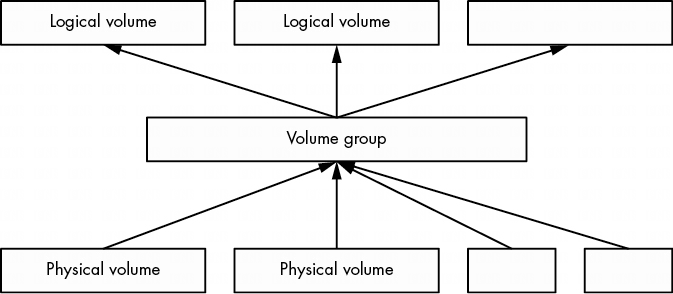
上图显示了一个卷组的组合示意图。图中显示了多个物理卷和逻辑卷,但许多基于 LVM 的系统只有一个物理卷和两个逻辑卷(根目录和交换卷)。
逻辑卷只是块设备,通常包含文件系统或交换签名,因此可以认为卷组与其逻辑卷之间的关系类似于磁盘与其分区之间的关系。最重要的区别在于,你通常不需要定义逻辑卷在卷组中的布局,LVM 会完成所有这些工作。
LVM 允许进行一些功能强大且极其有用的操作,例如
我们将对 LVM 进行适度详细的探讨。首先,我们将了解如何与逻辑卷及其组件进行交互和操作,然后我们将仔细研究 LVM 是如何工作的,以及它所基于的内核驱动程序。不过,这里的讨论对于理解本书的其他内容并不重要,所以如果你觉得太枯燥,可以跳到第 5 章。
LVM 有许多管理卷和卷群的用户空间工具。这些工具大多基于 lvm 命令,它是一个交互式通用工具。还有一些单独的命令(只是 LVM 的符号链接)用于执行特定任务。例如,vgs 命令与在交互式 lvm 工具的 lvm> 提示符下键入 vgs 的效果相同,而且你会发现 vgs(通常在 /sbin)是 lvm 的符号链接。我们将在本书中使用这些命令。
在接下来的几节中,我们将介绍使用逻辑卷的系统组件。最初的示例来自使用 LVM 分区选项的标准 Ubuntu 安装,因此许多名称都包含 Ubuntu 字样。不过,这些技术细节都不是该发行版所特有的。
列出并理解卷组
刚才提到的 vgs 命令显示了系统当前配置的卷组。输出相当简洁。下面是在我们的 LVM 安装示例中可能看到的内容:
# vgs
VG #PV #LV #SN Attr VSize VFree
ubuntu-vg 1 2 0 wz--n- 第一行是标题,每一行代表一个卷组。列数如下
这个卷组概要足以满足大多数目的。如果想更深入地了解某个卷组,可以使用 vgdisplay 命令,它对了解卷组的属性非常有用。下面是使用 vgdisplay 显示的同一个卷组:
你以前看到过其中的一些内容,但还有一些新项目值得注意:
~# vgdisplay
--- Volume group ---
VG Name ubuntu-vg
System ID
Format lvm2
Metadata Areas 1
Metadata Sequence No 3
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 1
Open LV 1
Max PV 0
Cur PV 1
Act PV 1
VG Size 890.08 GiB
PE Size 4.00 MiB
Total PE 227861
Alloc PE / Size 227861 / 890.08 GiB
Free PE / Size 0 / 0
VG UUID 2h4MuD-CKO0-nsoF-R6Ks-uMtm-Eqjz-tPhf5a
物理范围(在 vgdisplay 输出中缩写为 PE)是物理卷的一部分,与块很相似,但规模更大。在本例中,PE 大小为 4MB。可以看到,该卷组上的大部分 PE 都在使用中,但这并不值得大惊小怪。这只是为逻辑分区(本例中为文件系统和交换空间)分配的卷组空间大小,并不反映文件系统的实际使用情况。
与卷组类似,列出逻辑卷的命令是 lvs(简短列出)和 lvdisplay(详细显示)。下面是 lvs 的示例:
# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
ubuntu-lv ubuntu-vg -wi-ao---- 890.08g
在基本的 LVM 配置中,只有前四列需要了解,其余列可能是空的,这里就是这种情况(我们将不介绍这些列)。这里的相关列是
运行更详细的 lvdisplay 可以帮助了解逻辑卷在系统中的位置。下面是一个逻辑卷的输出结果:
# lvdisplay /dev/ubuntu-vg/ubuntu-lv
--- Logical volume ---
LV Path /dev/ubuntu-vg/ubuntu-lv
LV Name ubuntu-lv
VG Name ubuntu-vg
LV UUID 7cEznr-0SRd-PMhD-Yojp-bw5R-DxbL-q0aYUB
LV Write Access read/write
LV Creation host, time ubuntu-server, 2024-04-09 16:55:44 +0800
LV Status available
# open 1
LV Size 890.08 GiB
Current LE 227861
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 253:0
这里有很多有趣的内容,而且大部分内容不言自明(注意逻辑卷的 UUID 与卷组的 UUID 不同)。也许你还没有看到的最重要的东西是第一项: LV 路径,即逻辑加密卷的设备路径。有些系统(但不是所有系统)将其用作文件系统或交换空间的挂载点(在 systemd 挂载单元或 /etc/fstab 中)。
虽然你可以看到逻辑卷块设备的主设备号和次设备号(这里是 253 和 0),以及一些看起来像设备路径的东西,但它实际上并不是内核使用的路径。快速查看/dev/ubuntu-vg/root就会发现另有隐情:
# ls -l /dev/ubuntu-vg/ubuntu-lv
lrwxrwxrwx 1 root root 7 Jul 10 16:27 /dev/ubuntu-vg/ubuntu-lv -> ../dm-0
如你所见,这只是一个指向 /dev/dm-0 的符号链接。让我们来简单了解一下。
LVM 在系统上完成设置工作后,逻辑卷块设备就可以在 /dev/dm-0 和 /dev/dm-1 等位置上使用,而且可以按任意顺序排列。由于这些设备名称的不可预测性,LVM 还会根据卷组和逻辑卷名称创建符号链接,指向具有稳定名称的设备。在上一节的 /dev/ubuntu-vg/root 中,我们已经看到了这一点。
在大多数实现中,符号链接还有一个额外的位置: /dev/mapper。这里的名称格式也是基于卷组和逻辑卷,但没有目录层次结构;相反,链接的名称就像 ubuntu--vg-root 一样。在这里,udev 将卷组中的单破折号转换为双破折号,然后用单破折号分隔卷组和逻辑卷名称。
许多系统在 /etc/fstab、systemd 和引导加载器配置中使用 /dev/mapper 中的链接,以便将系统指向用于文件系统和交换空间的逻辑卷。
无论如何,这些符号链接都指向逻辑卷的块设备,你可以像使用其他块设备一样与它们交互:创建文件系统、创建交换分区等。
在 /dev/mapper 附近,你还会看到一个名为 control 的文件。你可能会对这个文件感到奇怪,为什么真正的块设备文件都以 dm- 开头;这是否与 /dev/mapper 有某种巧合?我们将在本章结尾讨论这些问题。
LVM 的最后一个主要部分是物理卷(PV)。一个卷组由一个或多个 PV 组成。虽然 PV 看起来像是 LVM 系统的一个简单部分,但它包含的信息比我们看到的要多一些。与卷组和逻辑卷一样,查看 PV 的 LVM 命令是 pvs(查看简短列表)和 pvdisplay(查看更深入的信息)。下面是我们示例系统的 pvs 显示:
# pvs
PV VG Fmt Attr PSize PFree
/dev/sda1 ubuntu-vg lvm2 a-- 通过前面对卷组和逻辑卷的讨论,你应该可以理解大部分输出结果。下面是一些注意事项:
除块设备外,PV 没有特殊名称。逻辑卷所需的所有名称都在卷组及以上级别。不过,PV 确实有一个 UUID,这是组成卷组所必需的。
在这种情况下,PE 的数量与卷组中的使用量相匹配(我们在前面已经看到),因为这是卷组中唯一的 PV。
有一小部分空间被 LVM 标为不可用,因为它不足以填满一个完整的 PE。
pvs 输出属性中的 a 与 pvdisplay 输出中的 Allocatable 相对应,它简单地表示如果要为卷组中的逻辑卷分配空间,LVM 可以选择使用这个 PV。不过,在本例中,只有 9 个未分配的 PE(总计 36MB),因此可用于新逻辑卷的空间并不多。
如前所述,PV 所包含的信息不仅仅是它们各自对卷组的贡献。每个 PV 都包含物理卷元数据、卷组及其逻辑卷的大量信息。我们稍后将探讨 PV 元数据,但首先让我们亲身体验一下,看看我们所学到的知识是如何融会贯通的。
让我们来看一个例子,看看如何用两个磁盘设备创建一个新卷组和一些逻辑卷。我们将把两个容量分别为 5GB 和 15GB 的磁盘设备合并为一个卷组,然后将该空间划分为两个容量各为 10GB 的逻辑卷--如果没有 LVM,这几乎是不可能完成的任务。这里显示的示例使用的是 VirtualBox 磁盘。虽然这些容量在任何现代系统上都很小,但足以说明问题。
图 4-5 显示了卷示意图。新磁盘位于 /dev/sdb 和 /dev/sdc,新卷组名为 myvg,两个新逻辑卷名为 mylv1 和 mylv2。
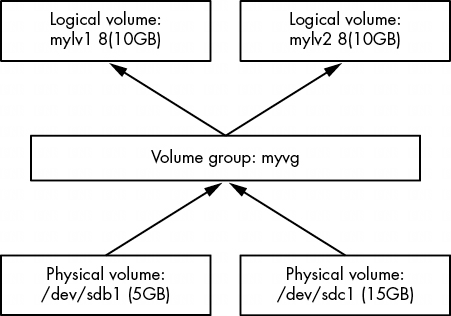
第一项任务是在每个磁盘上创建一个分区,并为 LVM 贴上标签。使用分区类型 ID 8e,用分区程序(见第 4.1.2 节)完成这项工作,这样分区表看起来就像这样:
不一定要对磁盘进行分区才能使其成为 PV。PV 可以是任何块设备,甚至是整个磁盘设备,如 /dev/sdb。不过,分区可以从磁盘启动,还提供了将块设备识别为 LVM 物理卷的方法。
有了 /dev/sdb1 和 /dev/sdc1 这两个新分区,使用 LVM 的第一步就是将其中一个分区指定为 PV,并将其分配给一个新卷组。只需一条命令 vgcreate 就能完成这项任务。下面是创建名为 myvg 的卷组的方法,初始 PV 为 /dev/sdb1:
# vgcreate myvg /dev/sdb1
Physical volume "/dev/sdb1" successfully created.
Volume group "myvg" successfully created
您也可以使用 pvcreate 命令在单独步骤中首先创建一个 PV。不过,如果当前没有任何分区,vgcreate 会在分区上执行此步骤。
此时,大多数系统会自动检测到新的卷组;请运行 vgs 等命令进行验证(请注意,除了您刚刚创建的卷组外,系统上可能还会显示其他现有的卷组):
# vgs
VG #PV #LV #SN Attr VSize VFree
myvg 1 0 0 wz--n- 如果看不到新的卷组,请先尝试运行 pvscan。如果系统不能自动检测 LVM 的更改,那么每次更改时都需要运行 pvscan。
现在,你可以使用 vgextend 命令将位于 /dev/sdc1 的第二个 PV 添加到卷组中:
# vgextend myvg /dev/sdc1
Physical volume "/dev/sdc1" successfully created.
Volume group "myvg" successfully extended
现在运行 vgs 会显示两个 PV,大小是两个分区的总和:
# vgs
VG #PV #LV #SN Attr VSize VFree
myvg 2 0 0 wz--n- 块设备级的最后一步是创建逻辑卷。如前所述,我们将创建两个各 10GB 的逻辑卷,但也可以尝试其他可能性,如创建一个大逻辑卷或多个小逻辑卷。
lvcreate 命令在卷组中分配一个新的逻辑卷。创建简单逻辑卷的唯一复杂之处在于,当每个卷组不止一个逻辑卷时,如何确定逻辑卷的大小,以及指定逻辑卷的类型。请记住,PV 被划分为扩展;可用 PE 的数量可能与您所需的大小不完全一致。如果你是第一次使用 LVM,就不必太在意 PE。
使用 lvcreate 时,可以使用 --size 选项以字节为单位的数字容量指定逻辑卷的大小,也可以使用 --extents 选项以 PE 的数量指定逻辑卷的大小。
因此,为了了解其工作原理,并完成图 4-5 中的 LVM 原理图,我们将使用 --size 创建名为 mylv1 和 mylv2 的逻辑卷:
# lvcreate --size 10g --type linear -n mylv1 myvg
Logical volume "mylv1" created.
# lvcreate --size 10g --type linear -n mylv2 myvg
Logical volume "mylv2" created.
这里的类型是线性映射,是不需要冗余或其他特殊功能时最简单的类型(我们在本书中不会使用其他类型)。在这种情况下,--type linear 是可选的,因为它是默认映射。
运行这些命令后,使用 lvs 命令验证逻辑卷是否存在,然后使用 vgdisplay 仔细查看卷组的当前状态:
# vgdisplay myvg
--- Volume group ---
VG Name myvg
System ID
Format lvm2
Metadata Areas 2
Metadata Sequence No 4
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 2
Open LV 0
Max PV 0
Cur PV 2
Act PV 2
VG Size 20.16 GiB
PE Size 4.00 MiB
Total PE 5162
Alloc PE / Size 5120 / 20.00 GiB
Free PE / Size 42 / 168.00 MiB
VG UUID 1pHrOe-e5zy-TUtK-5gnN-SpDY-shM8-Cbokf3
请注意有 42 个空闲 PE,因为我们为逻辑卷选择的大小并没有占用卷组中的所有可用扩展。
有了新的逻辑卷,现在就可以像其他普通磁盘分区一样,在设备上放置文件系统并加载它们,从而使用它们了。如前所述,/dev/mapper 和(本例中)卷组的/dev/myvg 目录中会有指向设备的符号链接。因此,举例来说,你可以运行以下三条命令来创建文件系统、临时加载文件系统并查看逻辑卷的实际空间:
# mkfs -t ext4 /dev/mapper/myvg-mylv1
mke2fs 1.44.1 (24-Mar-2018)
Creating filesystem with 2621440 4k blocks and 655360 inodes
Filesystem UUID: 83cc4119-625c-49d1-88c4-e2359a15a887
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632
Allocating group tables: done
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
# mount /dev/mapper/myvg-mylv1 /mnt
# df /mnt
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/myvg-mylv1 10255636 36888 9678076 1% /mnt
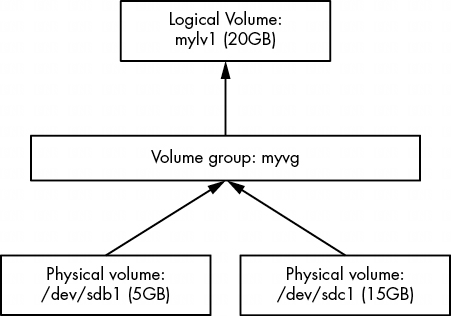
我们还没有研究过对另一个逻辑卷 mylv2 的任何操作,因此让我们用它来使这个示例更有趣。假如你发现你并没有真正使用第二个逻辑卷。你决定删除它,并调整第一个逻辑卷的大小,以占用卷组的剩余空间。图 4-6 显示了我们的目标。
假定你已经移动或备份了要删除的逻辑卷上的重要内容,并且当前系统没有使用该逻辑卷(也就是说,你已经卸载了它),那么首先使用 lvremove 命令将其删除。使用该命令操作逻辑加密卷时,将使用不同的语法,即用斜线分隔加密卷组和逻辑加密卷名称(myvg/mylv2):
# lvremove myvg/mylv2
Do you really want to remove and DISCARD active logical volume myvg/mylv2? [y/n]: y
Logical volume "mylv2" successfully removed
运行 lvremove 时要小心。由于您在执行其他 LVM 命令时没有使用过这种语法,因此可能会不小心用空格代替斜线。在这种情况下,如果你犯了这个错误,lvremove 就会假定你想删除 myvg 和 mylv2 卷组上的所有逻辑卷(你几乎肯定没有名为 mylv2 的卷组,但这不是目前最大的问题)。因此,如果你不注意,你可能会删除卷组上的所有逻辑卷,而不仅仅是一个。
从这个交互过程中可以看出,lvremove 会反复检查你是否真的想删除每个要删除的逻辑卷,以防止你出错。它也不会试图删除正在使用的卷。不过,不要以为别人问你任何问题,你都应该回答 “是”。
现在你可以调整第一个逻辑卷 mylv1 的大小了。 即使卷正在使用且其文件系统已加载,你也可以这样做。不过,重要的是要明白有两个步骤。要使用较大的逻辑卷,需要调整逻辑卷和逻辑卷内文件系统的大小(也可以在挂载逻辑卷时进行)。不过,由于这是一个很常见的操作,因此调整逻辑卷大小的 lvresize 命令有一个选项 (-r),可以为你同时调整文件系统的大小。
为了说明起见,让我们使用两个不同的命令来看看它是如何工作的。有几种方法可以指定逻辑卷的大小变化,但在本例中,最直接的方法是将卷组中的所有空闲 PE 添加到逻辑卷中。回想一下,你可以用 vgdisplay 找到这个数字;在我们正在运行的示例中,它是 2 602。下面是 lvresize 命令,用于将所有空闲 PE 添加到 mylv1:
# lvresize -l +2602 myvg/mylv1
Size of logical volume myvg/mylv1 changed from 10.00 GiB (2560 extents) to 20.16 GiB (5162 extents).
Logical volume myvg/mylv1 successfully resized.
现在需要调整内部文件系统的大小。可以使用 fsadm 命令来完成。使用 -v 选项)观察它在详细说明模式下的运行情况也很有趣:
# fsadm -v resize /dev/mapper/myvg-mylv1
fsadm: "ext4" filesystem found on "/dev/mapper/myvg-mylv1".
fsadm: Device "/dev/mapper/myvg-mylv1" size is 21650997248 bytes
fsadm: Parsing tune2fs -l "/dev/mapper/myvg-mylv1"
fsadm: Resizing filesystem on device "/dev/mapper/myvg-mylv1" to 21650997248 bytes (2621440 -> 5285888 blocks of 4096 bytes)
fsadm: Executing resize2fs /dev/mapper/myvg-mylv1 5285888
resize2fs 1.44.1 (24-Mar-2018)
Filesystem at /dev/mapper/myvg-mylv1 is mounted on /mnt; on-line resizing required
old_desc_blocks = 2, new_desc_blocks = 3
The filesystem on /dev/mapper/myvg-mylv1 is now 5285888 (4k) blocks long.
从输出结果可以看出,fsadm 只是一个脚本,它知道如何将参数转换为文件系统专用工具(如 resize2fs)使用的参数。默认情况下,如果你不指定大小,它会简单地调整大小以适应整个设备。
既然已经了解了调整卷大小的细节,你可能正在寻找捷径。更简单的方法是使用不同的语法指定大小,然后让 lvresize 为你执行分区大小调整,只需执行以下命令即可:
# lvresize -r -l +100%FREE myvg/mylv1
你可以在挂载 ext2/ext3/ext4 文件系统时对其进行扩展,这一点相当不错。遗憾的是,它不能反向操作。你不能在挂载文件系统时缩小它。不仅必须卸载文件系统,而且缩小逻辑卷的过程需要反向操作。因此,手动调整分区大小时,需要先调整分区大小,然后再调整逻辑卷大小,确保新逻辑卷的大小仍足以容纳文件系统。同样,使用带有 -r 选项的 lvresize 会更方便,因为它可以帮你协调文件系统和逻辑卷的大小。
在介绍了 LVM 比较实用的操作基础知识后,我们现在可以简单了解一下它的实现。与本书中几乎所有其他主题一样,LVM 包含许多层和组件,内核和用户空间的各部分之间有相当细致的分离。
很快你就会看到,查找 PV 以发现卷组和逻辑卷的结构有些复杂,Linux 内核宁愿不处理其中的任何部分。内核空间没有理由做这些事情;PV 只是块设备,而用户空间可以随机访问块设备。事实上,LVM(更具体地说,当前系统中的 LVM2)本身只是一套了解 LVM 结构的用户空间实用程序的名称。
另一方面,内核负责将逻辑卷块设备上的位置请求路由到实际设备上的真实位置。设备映射器(有时简称为 devmapper)就是这项工作的驱动程序,它是夹在普通块设备和文件系统之间的一个新层。顾名思义,设备映射器所执行的任务就像跟踪地图一样;你几乎可以把它想象成把街道地址转换为全球经纬度坐标之类的绝对位置。(这是一种虚拟化形式;我们将在本书其他部分看到的虚拟内存也是基于类似的概念)。
在 LVM 用户空间工具和设备映射器之间有一些粘合剂:一些在用户空间运行的实用程序,用于管理内核中的设备映射。让我们从 LVM 开始,看看 LVM 方面和内核方面的情况。
在执行任何操作之前,LVM 实用程序必须首先扫描可用的块设备,以查找物理卷。LVM 必须在用户空间执行的步骤大致如下:
每个 PV 的开头都有一个标头,用于标识卷、卷组和其中的逻辑卷。LVM 实用程序可以将这些信息放在一起,并确定是否存在卷组(及其逻辑卷)所需的所有 PV。如果一切正常,LVM 就可以将信息传递给内核。
如果您对 PV 上 LVM 头文件的外观感兴趣,可以运行如下命令:
# dd if=/dev/sdb1 count=1000 | strings | less
在本例中,我们使用 /dev/sdb1 作为 PV。别指望输出结果会很漂亮,但它确实显示了 LVM 所需的信息。
任何 LVM 实用程序,如 pvscan、lvs 或 vgcreate,都可以执行扫描和处理 PV 的工作。
LVM 根据 PV 上的所有标头确定逻辑卷的结构后,会与内核的设备映射器驱动程序通信,以初始化逻辑卷的块设备并加载其映射表。它通过 /dev/mapper/control 设备文件上的 ioctl(2) 系统调用(常用的内核接口)来实现这一功能。要监控这种交互并不现实,但可以使用 dmsetup 命令查看结果的细节。
使用 dmsetup info 命令可以获得设备映射器当前服务的映射设备清单。下面是本章前面创建的一个逻辑卷可能得到的结果:
# dmsetup info
Name: myvg-mylv1
State: ACTIVE
Read Ahead: 256
Tables present: LIVE
Open count: 0
Event number: 0
Major, minor: 253, 1
Number of targets: 2
UUID: LVM-1pHrOee5zyTUtK5gnNSpDYshM8Cbokf3OfwX4T0w2XncjGrwct7nwGhpp7l7J5aQ
设备的主编号和次编号与映射设备的 /dev/dm-* 设备文件相对应;该设备映射器的主编号为 253。因为次要序号是 1,所以设备文件被命名为 /dev/dm-1。请注意,内核为映射设备提供了一个名称和另一个 UUID。LVM 向内核提供了这些信息(内核 UUID 只是卷组和逻辑卷 UUID 的连接)。
还记得/dev/mapper/myvg-mylv1 这样的符号链接吗? udev 通过使用第 3.5.2 节所述的规则文件,根据来自设备映射器的新设备创建这些链接。
你也可以通过 dmsetup table 命令查看 LVM 提供给设备映射器的表。下面是我们之前的例子,当时有两个 10GB 的逻辑卷(mylv1 和 mylv2),分布在两个 5GB (/dev/sdb1)和 15GB (/dev/sdc1)的物理卷上:
# dmsetup table
myvg-mylv2: 0 10960896 linear 8:17 2048
myvg-mylv2: 10960896 10010624 linear 8:33 20973568
myvg-mylv1: 0 20971520 linear 8:33 2048
每一行都提供了特定映射设备的映射段。对于设备 myvg-mylv2,有两段,而对于 myvg-mylv1,只有一段。名称后面的字段依次是
有趣的是,在我们的例子中,LVM 选择将 /dev/sdc1 中的空间用于我们创建的第一个逻辑卷(mylv1)。LVM 决定要以连续的方式布局第一个 10GB 逻辑卷,而唯一的办法就是在 /dev/sdc1 上这样做。然而,在创建第二个逻辑加密卷(mylv2)时,LVM 别无选择,只能将其分为两段,分布在两个 PV 上。图 4-7 显示了这种安排。
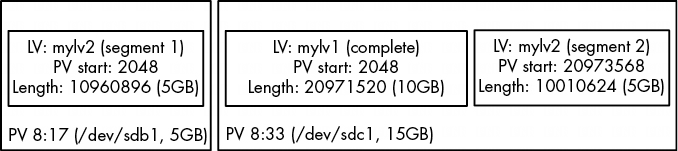
图 4-7: LVM 如何安排 mylv1 和 mylv2
此外,当我们移除 mylv2 并扩展 mylv1 以适应卷组中的剩余空间时,PV 中的原始起始偏移量仍保留在 /dev/sdc1 上,但其他一切都发生了变化,以包括 PV 的剩余部分:
# dmsetup table
myvg-mylv1: 0 31326208 linear 8:33 2048
myvg-mylv1: 31326208 10960896 linear 8:17 2048
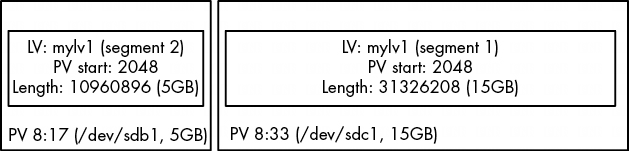
图 4-8: 删除 mylv2 并扩展 mylv1 后的安排
你可以在虚拟机上尽情试验逻辑卷和设备映射器,看看映射结果如何。许多功能(如软件 RAID 和加密磁盘)都建立在设备映射器上。
在 Unix 系统中与磁盘相关的组件中,用户空间和内核之间的界限可能很难描述。如前所述,内核处理来自设备的原始块 I/O,而用户空间工具可以通过设备文件使用块 I/O。不过,用户空间通常只将块 I/O 用于初始化操作,如分区、文件系统创建和交换空间创建。在正常使用中,用户空间只使用内核在块 I/O 上提供的文件系统支持。同样,在虚拟内存系统中处理交换空间时,内核也会处理大部分繁琐的细节。
本章剩余部分将简要介绍 Linux 文件系统的内部结构。这是比较高级的内容,你当然不需要了解这些内容就能继续阅读本书。如果你是第一次阅读本书,请跳到下一章,开始学习 Linux 如何启动。
传统的 Unix 文件系统有两个主要组成部分:一个可以存储数据的数据块池和一个管理数据池的数据库系统。数据库以 inode 数据结构为中心。Inode 是一组描述特定文件的数据,包括文件类型、权限以及最重要的文件数据在数据池中的位置。inode 由 inode 表中列出的数字标识。
文件名和目录也作为 inode 实现。目录 inode 包含与其他 inode 相对应的文件名和链接列表。
为了提供一个真实的例子,我创建了一个新的文件系统,将其挂载,并将目录更改为挂载点。然后,我使用这些命令添加了一些文件和目录:
$ mkdir dir_1
$ mkdir dir_2
$ echo a > dir_1/file_1
$ echo b > dir_1/file_2
$ echo c > dir_1/file_3
$ echo d > dir_2/file_4
$ ln dir_1/file_3 dir_2/file_5
请注意,我创建的 dir_2/file_5 是 dir_1/file_3 的硬链接,这意味着这两个文件名实际上代表的是同一个文件(稍后将详细介绍)。你可以自己试试。不一定要在新的文件系统上进行。
如果要查看该文件系统中的目录,其内容将如图 4-9 所示。
注意
如果你在自己的系统上尝试这样做,inode 数字可能会有所不同,特别是如果你运行命令在现有文件系统上创建文件和目录的话。具体的数字并不重要,重要的是它们指向的数据。
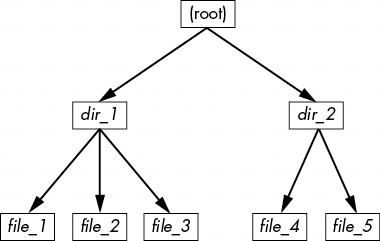
如图 4-10 所示,文件系统的实际布局是一组 inodes,看起来并不像用户级表示那样简洁。
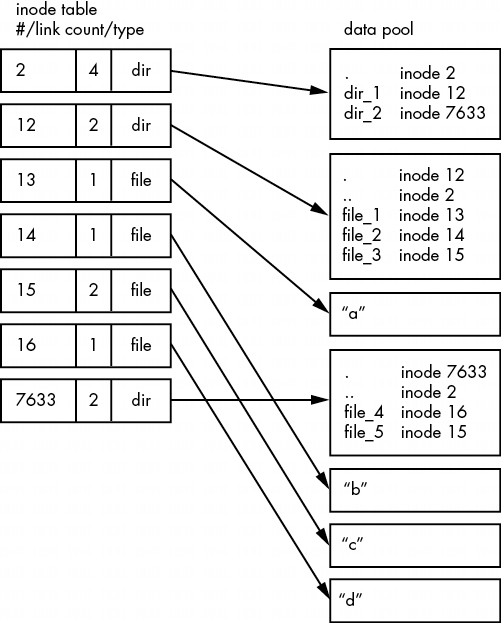
如何理解这一点?对于任何 ext2/3/4 文件系统,都是从 2 号节点开始,也就是根节点(尽量不要与系统根文件系统混淆)。从图 4-10 中的 inode 表可以看出,这是一个目录 inode (dir),因此可以按照箭头指向数据池,在那里可以看到根目录的内容:名为 dir_1 和 dir_2 的两个条目分别对应 inode 12 和 7633。要查看这些条目,请返回到 inode 表,查看其中任何一个 inode。
要查看该文件系统中的 dir_1/文件_2,内核会执行以下操作:
这种由 inode 指向目录数据结构、由目录数据结构指向 inode 的系统,可以创建我们熟悉的文件系统层次结构。此外,请注意目录 inodes 包含 .(当前目录)和 .(父目录,根目录除外)的条目。这样就很容易获得参考点,并沿着目录结构向下导航。
使用 ls -i 命令可以查看任何目录的节点编号。下面是本例中根目录下的内容(如需更详细的 inode 信息,请使用 stat 命令):
$ ls -i
12 dir_1 7633 dir_2
你可能想知道 inode 表中的链接计数。你已经在普通 ls -l 命令的输出中看到了链接计数,但很可能忽略了它。链接计数与图 4-9 中的文件,尤其是 “硬链接 ”文件_5 有什么关系?链接计数字段是指向一个 inode 的目录条目总数(在所有目录中)。大多数文件的链接计数都是 1,因为它们在目录条目中只出现过一次。这是意料之中的。大多数情况下,当你创建一个文件时,你会创建一个新的目录条目和一个新的 inode。但 inode 15 出现了两次。首先,它被创建为 dir_1/file_3,然后又被链接为 dir_2/file_5。硬链接就是在目录中手动创建一个条目,指向一个已经存在的 inode。使用 ln 命令(不带 -s 选项)可以手动创建新的硬链接。
这也是删除文件有时被称为取消链接的原因。如果运行 rm dir_1/file_2,内核会在 inode 12 的目录条目中搜索名为 file_2 的条目。一旦发现 file_2 与 inode 14 相对应,内核就会删除该目录项,然后从 inode 14 的链接计数中减去 1。这样,inode 14 的链接计数将为 0,内核将知道不再有任何名称链接到该 inode。因此,内核现在可以删除该 inode 及其相关数据。
然而,如果运行 rm dir_1/file_3,最终结果是 inode 15 的链接计数从 2 变为 1(因为 dir_2/file_5 仍指向该处),内核知道不能删除该 inode。
链接计数对目录的作用也是一样的。请注意,inode 12 的链接计数是 2,因为那里有两个 inode 链接:一个是 inode 2 目录条目中的 dir_1,另一个是它自己的目录条目中的自引用(.)。如果创建一个新的目录 dir_1/dir_3,则第 12 个节点的链接数将变为 3,因为新目录将包含一个父(...)条目,该条目链接回第 12 个节点,就像第 12 个节点的父链接指向第 2 个节点一样。
链接计数中有一个小例外。根节点 2 的链接数为 4,但图 4-10 只显示了三个目录条目链接。第四个 "链接位于文件系统的超级块中,因为超级块会告诉你在哪里可以找到根节点。
不要害怕在你的系统上做实验。创建一个目录结构,然后使用 ls -i 或 stat 来浏览各个部分是无害的。你不需要是 root 用户(除非你挂载并创建了一个新的文件系统)。
我们的讨论还缺少一个部分。在为新文件分配数据池区块时,文件系统如何知道哪些区块正在使用,哪些是可用的?最基本的方法之一是使用一种名为 “块位图 ”的附加管理数据结构。在这种方案中,文件系统保留一系列字节,每一位对应数据池中的一个区块。值为 0 表示该数据块是空闲的,值为 1 表示该数据块正在使用中。因此,分配和取消分配区块就是一个比特翻转的问题。
当 inode 表数据与块分配数据不匹配或链接计数不正确时,文件系统就会出现问题;例如,当你没有干净利落地关闭系统时就会出现这种情况。因此,如第 4.2.11 节所述,检查文件系统时,fsck 程序会遍历 inode 表和目录结构,生成新的链接计数和新的块分配映射(如块位图),然后将新生成的数据与磁盘上的文件系统进行比较。如果出现不匹配,fsck 必须修复链接计数,并决定如何处理在遍历目录结构时没有出现的任何节点和/或数据。大多数 fsck 程序会将这些 “孤儿 ”变成文件系统丢失+找到目录中的新文件。
在用户空间中处理文件和目录时,不必太担心它们下面的执行情况。进程应通过内核系统调用访问已挂载文件系统的文件和目录内容。但奇怪的是,你确实可以访问某些似乎不适合在用户空间中访问的文件系统信息,特别是 stat() 系统调用会返回 inode 编号和链接计数。
当你不维护文件系统时,是否需要担心 inode 编号、链接计数和其他执行细节?一般来说,不需要。用户模式程序可以访问这些内容主要是为了向后兼容。此外,并非所有 Linux 中的文件系统都有这些文件系统内部结构。VFS 接口层可确保系统调用总是返回 inode 编号和链接计数,但这些数字并不一定意味着什么。
你可能无法在非传统文件系统上执行传统的 Unix 文件系统操作。例如,你无法使用 ln 在挂载的 VFAT 文件系统上创建硬链接,因为它的目录条目结构是为 Windows 而不是 Unix/Linux 设计的,不支持这一概念。
幸运的是,Linux 系统上用户空间可用的系统调用提供了足够的抽象性,可以让你轻松访问文件--你不需要知道任何底层实现,就能访问文件。此外,文件名格式灵活,还支持混合大小写,因此很容易支持其他分层式文件系统。
请记住,特定的文件系统支持并不一定需要在内核中提供。例如,在用户空间文件系统中,内核只需充当系统调用的通道。
 登录查看全部
登录查看全部
参与评论
手机查看
返回顶部